

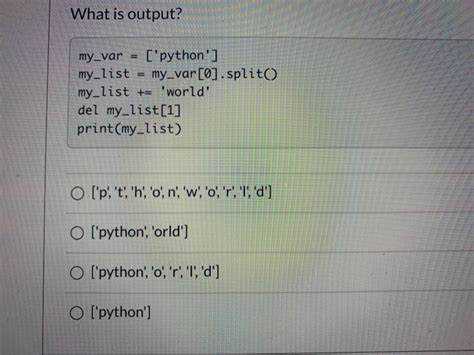
Методы title() и upper() применяются к строкам и возвращают их изменённые версии, но используются в разных контекстах. upper() преобразует все символы строки в заглавные, независимо от их позиции. Это полезно при нормализации текста, например, при сравнении строк без учёта регистра.
Метод title() возвращает строку, где первая буква каждого слова становится заглавной, а все остальные – строчными. Под словом в данном случае понимается последовательность символов, разделённых пробелами или знаками препинания. Особенность title() заключается в том, что он не распознаёт сокращения или слова с апострофами корректно: например, "don't" превращается в "Don'T", что может быть нежелательно при работе с натуральным языком.
Если требуется преобразовать строку в формат заголовка для отображения, title() может быть уместен, но для серьёзной обработки текстов предпочтительнее использовать библиотеку string.capwords() или регулярные выражения. Для приведения строк к единому регистру перед сохранением или сравнением предпочтительнее upper().
Как метод title изменяет строки с учётом разделителей
Метод title() преобразует первую букву каждого слова в строке в верхний регистр, а все остальные – в нижний. Под «словами» метод понимает фрагменты, разделённые символами, не являющимися буквами. Это значит, что символы вроде пробела, тире, знаков препинания и цифр рассматриваются как границы слов.
Пример: 'пример-названия файла'.title() вернёт строку 'Пример-Названия Файла'. Метод интерпретирует дефис как границу, поэтому после него следующая буква также становится заглавной.
Если строка содержит апостроф или другие спецсимволы внутри слова, title() может дать неожиданный результат. Например, "john's car".title() вернёт "John'S Car", хотя апостроф – не граница слова в привычном смысле. Метод просто преобразует букву после апострофа в верхний регистр.
Рекомендация: для строк, содержащих нестандартные разделители, используйте предварительную обработку – разбивку на части с помощью регулярных выражений, изменение регистра вручную или применение capitalize() к каждому слову после пользовательского разделения.
Что произойдёт с уже заглавными буквами при применении title
Метод title() преобразует строку так, что первая буква каждого слова становится заглавной, а все остальные – строчными. Это поведение влияет и на те буквы, которые уже были заглавными, но находились не в начале слова.
- Если заглавная буква стоит внутри слова, она будет преобразована в строчную. Пример:
"PRoGRaMMing".title()вернёт"Programming". - Если слово начинается с заглавной буквы, но содержит другие заглавные, все, кроме первой, станут строчными:
"PyTHon lanGUage".title()→"Python Language". - Метод
title()не проверяет, была ли буква заглавной – он просто принудительно форматирует каждое слово по своей схеме.
Результат зависит от разделителей. Метод считает словом любую последовательность после пробела или символов, не являющихся буквами. Например:
"java-script".title()→"Java-Script"(после дефиса начинается новое слово)"API_test".title()→"Api_Test"(буквы «PI» и «est» становятся строчными)
Чтобы сохранить оригинальные заглавные внутри слов, title() использовать нецелесообразно. Лучше применить capitalize() к каждому слову вручную или использовать регулярные выражения с точечной заменой.
Преобразование строк с апострофами и дефисами методом title

Метод title() преобразует строку так, что первая буква каждого слова становится заглавной, а остальные – строчными. Однако при работе со словами, содержащими апострофы и дефисы, возникают особенности, которые важно учитывать.
- Слова с апострофами –
"it's", "don't", "rock'n'roll"– методtitle()обрабатывает некорректно: заглавной становится буква сразу после апострофа, хотя грамматически слово должно оставаться целым. Например,"rock'n'roll".title()возвращает"Rock'N'Roll", а не"Rock'n'Roll". - Слова с дефисами –
"mother-in-law", "well-known"– метод разбивает на части и делает каждую из них с заглавной буквы. Результат:"Mother-In-Law","Well-Known". Это соответствует нормам типографики, но может быть нежелательно, если необходимо сохранить оригинальный регистр частей.
Рекомендуется:
- Для апострофов – использовать
splitи ручную сборку строки, чтобы избежать ошибочного заглавного регистра внутри слова. - Для дефисов – учитывать контекст. Если слово должно сохранять исходный стиль, предпочтительна ручная обработка:
'-'.join(part.capitalize() for part in s.split('-')). - Не применять
title()к пользовательским именам или терминам, где важен точный формат (например, «O’Neill»).
Метод title() не анализирует грамматику и не различает морфологические границы слов. Он работает по шаблону: символ после любого не-буквенного – заглавный. Это приводит к ошибкам при наличии апострофов и дефисов.
Поведение метода upper при наличии цифр и специальных символов

Метод upper() преобразует все буквенные символы строки в верхний регистр. Цифры и специальные символы остаются без изменений. Это поведение обусловлено тем, что метод работает только с символами, которые имеют различие между верхним и нижним регистром в таблице Unicode.
Примеры:
«python3.8».upper() вернёт «PYTHON3.8». Буквы переведены в верхний регистр, но 3, . и 8 остались без изменений.
«email@example.com!».upper() даст результат «EMAIL@EXAMPLE.COM!». Символы @, . и ! не изменились.
Метод не вызывает ошибок при наличии любых символов, включая пробелы, знаки препинания и служебные знаки. Он безопасен для строк, содержащих смешанный тип символов.
Для предварительной фильтрации можно использовать метод isalnum() или регулярные выражения, если необходимо исключить спецсимволы до преобразования регистра.
Пример фильтрации перед применением upper():
».join(c for c in s if c.isalpha()).upper() – преобразует только буквы, игнорируя цифры и знаки.
Сравнение title и upper на примере многоязычных строк
Метод title() преобразует первую букву каждого слова в заглавную, остальные – в строчные. Метод upper() переводит все символы в верхний регистр. При работе с многоязычными строками поведение этих методов зависит от особенностей конкретного языка и стандарта Unicode.
Для строки на английском языке "hello world" результат будет ожидаем: "Hello World" и "HELLO WORLD". Однако для строки на турецком языке "istanbul" метод upper() вернёт "ISTANBUL", хотя корректным в турецкой грамматике является "İSTANBUL". Это связано с тем, что upper() не учитывает языковой контекст, а использует стандартное преобразование Unicode без локализации.
В случае с немецким "straße", upper() преобразует в "STRASSE", заменяя ß на SS, что допустимо, но может быть нежелательно в формальном тексте. Метод title() при этом вернёт "Strasse", что может привести к потере семантики оригинального слова.
С кириллицей оба метода работают предсказуемо: "привет мир".title() выдаёт "Привет Мир", .upper() – "ПРИВЕТ МИР". Однако title() не различает аббревиатуры: "api документация".title() преобразуется в "Api Документация", что может быть нежелательно в технических текстах.
Рекомендуется использовать upper() для стандартного преобразования регистра, когда важна предсказуемость и однозначность результата. Метод title() подходит для простых текстов, но требует осторожности при работе с техническими терминами и неанглийскими языками. Для корректной работы с национальными правилами преобразования регистра следует использовать библиотеку PyICU или другие решения с поддержкой локалей.
Когда title и upper дают неожиданные результаты
Методы title() и upper() в Python могут вести себя неожиданно, если данные содержат специальные символы или числовые значения. Рассмотрим эти случаи более детально.
Метод upper() приводит все символы строки к верхнему регистру. Однако, он не изменяет символы, которые уже находятся в верхнем регистре, и оставляет числовые и специальные символы без изменений. Например:
'hello123!'.upper()Результат: 'HELLO123!'
В этом примере метод корректно изменил только буквы, оставив цифры и символы нетронутыми. Это может быть неожиданным, если ожидается изменение всех символов, включая цифры.
Метод title() преобразует строку так, чтобы каждое слово начиналось с заглавной буквы. Однако он применяет преобразование только к буквам, а не к цифрам или символам. Проблема возникает, когда строка содержит такие элементы, как апострофы, дефисы или другие символы, которые могут быть неправильно интерпретированы. Например:
'it's a beautiful day'.title()Результат: 'It'S A Beautiful Day'
Как видно, метод title() преобразует слово it's в It'S, где буква S остается в верхнем регистре из-за апострофа. Это может нарушить ожидаемый формат. Для правильной работы с такими строками следует использовать дополнительные проверки или кастомные функции для обработки апострофов и других символов.
Для избегания подобных ситуаций рекомендуется предварительно проверять строки и при необходимости очищать их от нежелательных символов или использовать регулярные выражения для более точного контроля преобразования.
Какие задачи удобнее решать с помощью title, а какие – с upper
Методы title() и upper() выполняют схожие функции преобразования текста, но применяются в разных ситуациях. Каждый из них имеет свою специфику, которая определяет, какие задачи удобнее решать с их помощью.
Метод title() приводит первый символ каждого слова к верхнему регистру, а остальные – к нижнему. Это особенно удобно для обработки заголовков или имен, где нужно соблюсти стандарты написания, например, в литературных произведениях или в официальных документах, где важно, чтобы каждое слово начиналось с заглавной буквы. Такой метод полезен, когда требуется привести строку к формату заголовка или имени, например:
text = "hello world"
print(text.title()) # Выведет: Hello WorldЭто преобразование подходит для задач, связанных с генерацией читаемых заголовков или обработки текста, где каждое слово должно начинаться с заглавной буквы (кроме маленьких слов, таких как предлоги или союзы, если это не предусмотрено стилем).
Метод upper() переводит весь текст в верхний регистр. Этот метод эффективен, когда требуется выделить текст или сделать его более заметным, например, для создания заголовков в списках, предупреждений или выделения важных сообщений. Использование upper() полезно в случае, когда нужно, чтобы весь текст был в одном формате, например:
text = "warning"
print(text.upper()) # Выведет: WARNINGЭто преобразование подходит для задач, где нужно подчеркнуть важность или выделить текст среди остального контента, например, в заголовках предупреждений, статусах ошибок или сообщениях, требующих внимания.
Таким образом, title() лучше использовать для создания стильных заголовков или обработки имен, а upper() – для выделения текста или создания акцента. Выбор метода зависит от контекста, в котором используется текст.
Вопрос-ответ:
Чем метод title отличается от метода upper в Python?
Метод title преобразует строку так, чтобы первое слово начиналось с заглавной буквы, а все остальные слова начинались с маленькой. Например, строка «hello world» после применения метода title превратится в «Hello World». Метод upper, наоборот, делает все символы строки заглавными, например, «hello world» станет «HELLO WORLD».
Можно ли использовать методы title и upper для преобразования строки в определенный регистр с учетом специфики слов в строке?
Да, эти методы имеют разные цели. Метод title обычно используется для преобразования строк, где важно, чтобы каждое слово начиналось с заглавной буквы, что полезно при форматировании заголовков. Метод upper же применяется, если необходимо сделать весь текст полностью заглавным, например, для выделения текста. Разница между ними заключается именно в этом подходе к форматированию: title ориентируется на каждый отдельный элемент строки, а upper действует глобально на всю строку.
Что будет, если применить метод title к строке с уже заглавными буквами?
Если строка уже имеет заглавные буквы в начале слов, метод title не изменит эту строку. Например, строка «Hello World» останется «Hello World», так как она уже соответствует формату, который применяется методом title. Однако если строка имеет неявные маленькие буквы в других местах, метод все равно приведет их к нужному виду — заглавные буквы в начале каждого слова и маленькие — в остальных частях.
Какая разница в применении методов title и upper для строк, содержащих числа или символы?
Методы title и upper не изменяют числа и символы в строке. Они действуют только на буквы. Например, строка «hello 123 world!» после применения метода title превратится в «Hello 123 World!», а при применении метода upper — в «HELLO 123 WORLD!». Числа и символы останутся без изменений, так как эти методы влияют только на алфавитные символы.
Когда лучше использовать метод upper, а когда title в реальных задачах?
Метод upper обычно используется, когда нужно сделать весь текст заглавным, например, для выделения текста в интерфейсе или логах. Он полезен для акцента на важной информации. Метод title же подходит, когда нужно правильно отформатировать заголовки или имена, где важно, чтобы каждое слово начиналось с заглавной буквы. Например, для автоматического форматирования заголовков или при обработке строк, содержащих имена собственные.





