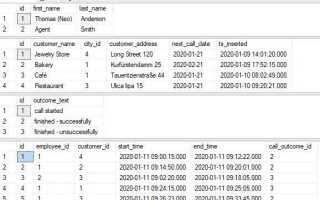
Скрипты SQL – это текстовые файлы, содержащие команды для работы с базами данных. Они могут быть использованы для создания, обновления или удаления объектов базы данных, а также для выполнения запросов. Важно понимать, где искать такие скрипты, чтобы эффективно управлять ими и быстро находить нужную информацию в случае необходимости.
Основные места хранения скриптов SQL зависят от среды работы и используемых инструментов. На сервере базы данных скрипты могут быть частью автоматизированных процессов, хранящихся в системных каталогах или в виде встроенных процедур. Например, в SQL Server скрипты могут быть сохранены в виде хранимых процедур или функций, доступных через каталоги базы данных. В MySQL их можно найти в отдельных файлах или в виде запросов, хранящихся в репозиториях.
Для разработки и тестирования SQL-кода часто используются IDE, такие как SQL Server Management Studio или MySQL Workbench, где скрипты сохраняются в проектных файлах. Эти файлы обычно содержат не только команды SQL, но и структуру базы данных, а также данные для тестирования. Некоторые разработчики предпочитают хранить свои скрипты в системах контроля версий, таких как Git, что позволяет отслеживать изменения и совместно работать над проектом.
Также важно учитывать, что в крупных организациях скрипты SQL могут быть централизованно хранимы в репозиториях кода или специальных хранилищах для конфигурационных файлов, таких как GitLab или Bitbucket. Это позволяет разработчикам легко обновлять и управлять версиями кода, а также избегать потерь данных при миграции или масштабировании базы данных.
Как найти скрипты в базе данных SQL с помощью системных таблиц
Для поиска скриптов в базе данных SQL можно использовать системные таблицы, которые хранят метаданные о различных объектах базы данных. В зависимости от используемой СУБД, структура этих таблиц может различаться, но в большинстве случаев доступ к нужной информации можно получить через стандартные представления или системные таблицы.
Одним из ключевых представлений является sys.objects, которое содержит информацию обо всех объектах базы данных, таких как таблицы, представления, процедуры и функции. Чтобы найти скрипты для определённых объектов, необходимо обратиться к системным представлениям и функциям, связанным с хранением кода объектов, таких как хранимые процедуры или функции.
Ниже приведены несколько шагов для поиска скриптов с помощью системных таблиц в SQL Server:
- Поиск текста хранимых процедур и функций: В SQL Server скрипты для хранимых процедур, триггеров и функций можно найти в таблице
sys.sql_modules, которая хранит исходный текст этих объектов. Для получения скрипта можно выполнить следующий запрос: - Поиск текста триггеров: Для поиска текста триггеров в базе данных, можно использовать представление
sys.triggers. Запрос для получения текста триггера будет следующим: - Поиск по типу объектов: В случае необходимости поиска скриптов для конкретных типов объектов (например, только для представлений), можно использовать представление
sys.objects, которое содержит информацию о типах объектов. Пример запроса: - Поиск текста для представлений: Для поиска текста представлений используется то же представление
sys.sql_modules, но с фильтрацией по типу объекта: - Просмотр истории изменений: В случае использования расширенной истории изменений, можно запросить таблицы, хранящие информацию о создании и изменении объектов. Например, в
sys.objectsхранится дата создания объекта, а вsys.syscommentsможно найти старые версии кода, если объекты были изменены.
SELECT OBJECT_NAME(object_id), definition
FROM sys.sql_modules
WHERE OBJECTPROPERTY(object_id, 'IsProcedure') = 1;SELECT t.name AS TriggerName, m.definition
FROM sys.triggers t
INNER JOIN sys.sql_modules m ON t.object_id = m.object_id;SELECT name
FROM sys.objects
WHERE type = 'V';SELECT OBJECT_NAME(object_id), definition
FROM sys.sql_modules
WHERE OBJECTPROPERTY(object_id, 'IsView') = 1;Также, в других СУБД, таких как MySQL и PostgreSQL, могут использоваться другие системные таблицы. Например, в MySQL информация о текстах объектов хранится в таблице information_schema.routines для процедур и функций, а в PostgreSQL – в pg_proc для процедур и функций, с текстом в поле prosrc.
Использование этих системных таблиц позволяет эффективно находить и извлекать код объектов SQL без необходимости вручную искать скрипты в файловой системе или других источниках. Важно понимать структуру метаданных, чтобы точно и быстро находить нужную информацию.
Поиск и организация SQL-скриптов в репозиториях Git

Для эффективного поиска и организации SQL-скриптов в репозиториях Git необходимо учитывать несколько ключевых аспектов: структура каталогов, использование версионного контроля, а также систематизация самих скриптов.
Структура каталогов играет важную роль в упрощении поиска нужных файлов. Рекомендуется создавать отдельные директории для различных типов скриптов: миграции, создания таблиц, вставки данных и т.д. Например, структура может выглядеть так:
/migrations /2025-04-24-initial-schema.sql /2025-05-10-add-users-table.sql /2025-06-01-update-indexes.sql /schemas /users-table-schema.sql /products-table-schema.sql /seed-data /initial-users.sql /sample-products.sql
Такая организация позволяет быстро находить скрипты, связанные с конкретными задачами, и минимизирует вероятность ошибок при их использовании.
Важным инструментом для поиска является git grep. Эта команда позволяет быстро искать текстовые фрагменты внутри файлов. Например, чтобы найти все скрипты, содержащие создание таблиц, можно выполнить следующую команду:
git grep 'CREATE TABLE' -- '*.sql'
Для еще более точных результатов можно комбинировать поиск с регулярными выражениями. Это особенно полезно при работе с большими репозиториями, содержащими тысячи SQL-скриптов.
Использование тегов и комментариев в самом коде SQL-скриптов помогает структурировать их для быстрого поиска и понимания. В начале каждого скрипта можно добавлять метки, указывающие его назначение, например:
-- Скрипт для создания таблицы пользователей -- Назначение: initial schema -- Дата создания: 2025-04-24 CREATE TABLE users ( id INT PRIMARY KEY, name VARCHAR(100) );
Кроме того, теги версии (например, в формате `v1.0`, `v2.3` и т.д.) могут быть полезны для указания соответствия конкретной версии базы данных или этапа разработки. Для управления версиями схем рекомендуется использовать специальные инструменты, такие как Liquibase или Flyway, которые интегрируются с Git-репозиториями и автоматизируют применение изменений.
Организация коммитов в Git также имеет значение. Каждый коммит должен быть атомарным и представлять собой логичную единицу изменений, например, создание таблицы или изменение структуры базы данных. Рекомендуется использовать четкие и информативные сообщения для коммитов:
git commit -m "Создание таблицы пользователей (users) и индекса по email"
Такой подход облегчает поиск нужных изменений и позволяет быстро откатить базу данных на нужную версию в случае необходимости.
В крупных проектах часто возникают проблемы с поддержанием порядка в репозитории, когда SQL-скрипты создаются разными командами. Для решения этой проблемы полезно внедрить конвенции по именованию файлов и строгое соблюдение единого подхода к организации кода. Например, использовать формат дат в именах файлов для отслеживания их последовательности:
/2025-04-24_create-users-table.sql /2025-05-10_add-index-to-users-email.sql
При таком подходе всегда будет легко определить, в какой последовательности применялись скрипты.
Интеграция с CI/CD – еще один способ оптимизации работы с SQL-скриптами в Git. Автоматическое тестирование миграций и проверка их корректности на всех этапах жизненного цикла разработки позволяют уменьшить количество ошибок, связанных с выполнением SQL-скриптов. Применение миграций через систему CI/CD помогает предотвратить несоответствия между окружениями разработки и продакшн.
Особенности хранения SQL-скриптов в файловой системе сервера
SQL-скрипты часто хранятся в файловой системе сервера для обеспечения доступности, удобства версии и управления ими. Основное внимание при организации хранения стоит уделить вопросам безопасности, структуры каталогов и прав доступа.
Рекомендуется использовать строгую иерархию каталогов, где каждый набор скриптов имеет свое отдельное пространство. Например, для разных проектов или для разных типов операций (создание таблиц, обновление данных, миграции) могут быть выделены отдельные директории. Это упрощает поиск нужного скрипта и его использование.
Права доступа играют ключевую роль в защите скриптов. Для файлов SQL рекомендуется минимизировать доступ, ограничивая его только необходимыми пользователями или группами. Часто SQL-скрипты включают чувствительные данные, такие как логины или пароли, что делает их потенциальной целью для атак. Важно, чтобы права на файлы были настроены так, чтобы только администраторы или авторизованные пользователи могли изменять или просматривать скрипты.
Вместо того чтобы хранить SQL-скрипты в открытом виде, можно использовать шифрование для защиты содержимого. Для этого используют механизмы операционной системы или специализированные решения для управления конфиденциальной информацией. Однако следует помнить, что с шифрованием связано увеличение нагрузки на систему, что важно учитывать при проектировании.
При хранении скриптов на сервере важно избегать использования однотипных имен для файлов, чтобы не возникало путаницы и не были затерты важные данные. Важным моментом является использование версионирования. Многие системы контроля версий, такие как Git, могут быть использованы для управления изменениями в SQL-скриптах. Это позволяет отслеживать изменения, откатывать их при необходимости и сохранять историю изменений.
Логирование изменений в скриптах полезно для обеспечения прозрачности процессов. Для этого можно использовать интеграцию с системами логирования, которые будут отслеживать каждое изменение и уведомлять администраторов о его важности или причине. Это также позволяет анализировать, какие скрипты были запущены, и какие изменения были внесены в базу данных.
Важно помнить о совместимости SQL-скриптов с операционными системами, на которых они выполняются. Платформенные особенности могут влиять на формат файлов, пути к файлам и даже на саму структуру скриптов. Поэтому при разработке и хранении скриптов стоит учитывать специфику операционной системы сервера, будь то Linux, Windows или другие системы.
Резервное копирование является неотъемлемой частью стратегии управления SQL-скриптами. Регулярное создание резервных копий файлов помогает защитить важные данные от потери. Резервные копии должны храниться в безопасном месте и быть доступными для восстановления в случае сбоев или ошибок.
Как использовать комментарии для поиска и документирования скриптов в SQL
Комментарии в SQL выполняют две ключевые функции: помогают разработчикам и администраторам баз данных быстрее понимать логику запросов и обеспечивают эффективную организацию кода. Для поиска и документирования скриптов, комментарии играют важную роль в упрощении процессов разработки и сопровождения.
В SQL можно использовать два типа комментариев: однострочные и многострочные. Однострочные комментарии начинаются с двойного дефиса (—), а многострочные – с символов /* и заканчиваются на */.
При документировании скриптов важно не просто оставлять описание каждой операции, но и структурировать комментарии так, чтобы они легко воспринимались и использовались для поиска. Например, для поиска конкретных частей кода можно вводить в комментарии ключевые слова, такие как TODO, FIXME, или REVIEW, что помогает выделить участки, которые требуют внимания.
Пример:
-- TODO: Оптимизировать запрос на выборку пользователей по возрасту SELECT * FROM users WHERE age > 30;
Важно также использовать теги в комментариях для структурирования данных. Например, добавление меток Author, Date или Version поможет отслеживать изменения и авторов изменений в скриптах. Это особенно полезно, если проект развивается и различные разработчики вносят изменения в одни и те же части кода.
Пример:
/* Author: Иванов И. Date: 24.04.2025 Version: 1.0 Описание: Запрос для получения списка активных пользователей */ SELECT * FROM users WHERE status = 'active';
Также полезно добавлять ссылки на связанные тикеты в системах управления проектами, таких как Jira или GitLab, прямо в комментариях. Это ускоряет поиск и понимание контекста изменений, особенно в больших проектах.
Комментарии должны быть лаконичными, но содержательными. Избегайте избыточных или очевидных комментариев, которые не добавляют ценности, например, «Выбираем все записи из таблицы», если код сам по себе понятен.
Регулярное использование комментариев для поиска и документирования помогает упростить поддержку кода и ускоряет процесс его дальнейшей модификации. Важно понимать, что комментарии – это не только описание действий в коде, но и инструмент для эффективного взаимодействия с коллегами и упрощения поиска нужных фрагментов в большом количестве скриптов.
Роль SQL-сценариев в системах автоматического резервного копирования
SQL-сценарии играют ключевую роль в автоматизации процессов резервного копирования данных в реляционных базах данных. Они позволяют настраивать регулярные и точные копии данных, что критически важно для обеспечения восстановления информации в случае сбоев или потерь. В отличие от традиционных методов резервного копирования, которые фокусируются на файловых системах, SQL-сценарии позволяют работать непосредственно с базой данных, обеспечивая целостность и полноту данных.
Основное преимущество использования SQL-сценариев в процессе резервного копирования заключается в их гибкости. С помощью SQL можно настроить не только полные, но и инкрементальные или дифференциальные резервные копии. Эти типы копий обеспечивают минимизацию объема данных, которые нужно сохранять, что способствует экономии ресурсов и времени. Инкрементальные копии сохраняют только те изменения, которые произошли после последнего полного резервного копирования, а дифференциальные – изменения после последнего инкрементального или полного.
Для эффективного использования SQL-сценариев необходимо интегрировать их с задачами автоматического выполнения. Системы управления базами данных (СУБД) предоставляют средства для планирования задач (например, cron в Unix-подобных системах или задания SQL Server Agent для Microsoft SQL Server). Важно также регулярно проверять успешность выполнения сценариев и анализировать логи, чтобы убедиться, что резервное копирование прошло без ошибок.
Важно помнить, что для резервного копирования в SQL можно использовать как стандартные команды (например, BACKUP DATABASE в MS SQL или mysqldump в MySQL), так и сложные скрипты, которые включают в себя не только команды на создание резервных копий, но и дополнительные проверки целостности данных или отправку уведомлений в случае ошибок. Это позволяет автоматизировать не только сам процесс создания копий, но и мониторинг его состояния.
Для эффективного восстановления данных из резервных копий важно также учитывать синхронизацию времени между резервным копированием и фактическим состоянием базы данных. SQL-сценарии могут автоматически отслеживать метки времени и состояние транзакций, что позволяет точно восстановить данные на момент сбоя или ошибки, без потерь и несоответствий.
Как управлять версиями SQL-скриптов с использованием инструментов CI/CD

Управление версиями SQL-скриптов в рамках процессов CI/CD (непрерывной интеграции и доставки) позволяет эффективно отслеживать изменения в базе данных, автоматизировать их развертывание и минимизировать ошибки. Важно выбрать правильный подход для версионирования, чтобы избежать проблем при совместной работе над проектами.
Первым шагом является интеграция SQL-скриптов в систему контроля версий, например, Git. Скрипты должны быть структурированы по версии и предназначению, например, создания или изменения таблиц, индексов, триггеров. Для каждой новой версии базы данных рекомендуется создавать отдельный скрипт с уникальным именем, содержащим дату и краткое описание изменений. Это помогает отслеживать изменения на разных стадиях проекта.
Для автоматизации развертывания SQL-скриптов на разных средах можно использовать инструменты CI/CD, такие как Jenkins, GitLab CI или GitHub Actions. В таких системах можно настроить пайплайны для автоматического применения скриптов в тестовой и продакшн средах. Скрипты необходимо выполнять в определенном порядке, что позволяет избежать несоответствий между версиями базы данных. Один из подходов – хранить миграции в виде отдельных файлов с нумерацией, чтобы гарантировать, что они применяются в правильной последовательности.
В процессе миграции базы данных важно использовать инструменты, которые поддерживают откат изменений. Это необходимо для случаев, когда применение скрипта вызывает ошибки или неудачные изменения. Одним из популярных инструментов для таких операций является Flyway. Он позволяет хранить миграции в Git и автоматически обновлять схему базы данных при каждом обновлении.
Рекомендуется также автоматизировать тестирование SQL-скриптов. Каждый новый скрипт следует проверять на тестовой среде, прежде чем применять на продакшн. Это можно делать через пайплайны, включая в них шаги для тестирования SQL-запросов, выполнения юнит-тестов или интеграционных тестов, которые проверяют корректность работы базы данных с приложением.
Кроме того, стоит внедрить систему для контроля версий самих миграций. Например, можно использовать версионирование с помощью инструментов, таких как Liquibase, который записывает каждую миграцию в отдельный файл, отслеживая изменения и обеспечивая совместимость между версиями базы данных в разных средах.
Такой подход позволяет эффективно управлять версиями SQL-скриптов и интегрировать их в процессы CI/CD, что способствует стабильности и предсказуемости при разработке и эксплуатации базы данных.
Применение стандартов именования для упорядочивания SQL-скриптов
- Использование префиксов для типов объектов: Каждый тип объекта в базе данных должен иметь свой префикс. Например:
- Таблицы:
tbl_–tbl_customers - Виды:
vw_–vw_active_orders - Хранимые процедуры:
sp_–sp_get_user_details - Триггеры:
trg_–trg_before_insert
- Таблицы:
- Использование разделителей: Для улучшения читаемости имен следует использовать символы подчеркивания
_для разделения слов. Например:get_user_by_id,calculate_total_price. - Использование явных и понятных имен: Имена должны отражать суть действия или объекта. Для хранимых процедур предпочтительнее использовать глаголы, такие как
get,set,update,delete. Например:get_user_details,set_order_status. - Использование CamelCase: В некоторых проектах применяется стиль именования, где каждое новое слово начинается с заглавной буквы. Этот стиль лучше использовать для методов или функций, например:
getUserDetails. - Международная совместимость: Имена должны быть написаны на английском языке, что облегчает работу с кодом в международных командах и позволяет избежать проблем с кодировками. Например:
order_idвместономер_заказа. - Ограничение длины имен: Слишком длинные имена могут затруднить чтение и поддержку кода. Рекомендуется ограничить длину имени до 30-40 символов, если это возможно, не теряя при этом ясности.
Соблюдение этих стандартов позволяет не только ускорить разработку, но и упростить поддержку системы в долгосрочной перспективе. Каждый разработчик и администратор базы данных будет способен быстро разобраться в структуре и логике работы системы, что снижает вероятность ошибок и повышает производительность команды.
Вопрос-ответ:
Что такое SQL-скрипты и для чего они используются?
SQL-скрипты — это текстовые файлы, содержащие последовательность SQL-команд. Эти скрипты позволяют автоматизировать задачи с базами данных, такие как создание таблиц, обновление данных или выполнение запросов. Скрипты могут быть использованы для быстрого выполнения однотипных операций или для выполнения сложных операций с данными, например, при миграции данных или настройке базы данных.
Где можно найти готовые SQL-скрипты?
Готовые SQL-скрипты можно найти на различных ресурсах в интернете, таких как GitHub, Stack Overflow, а также в специализированных форумах по разработке и администрированию баз данных. Множество скриптов доступно в открытых репозиториях или на сайтах, посвящённых SQL и базам данных. Некоторые скрипты можно найти в документации СУБД (систем управления базами данных), которая часто включает примеры кода.
Как хранятся SQL-скрипты в базе данных?
SQL-скрипты обычно не хранятся непосредственно в базе данных, а сохраняются как текстовые файлы на сервере или в репозиториях. В некоторых случаях SQL-скрипты могут быть сохранены как строки в базе данных, если необходимо хранить их для последующего использования или восстановления. Например, можно использовать таблицу для хранения скриптов и их метаданных, чтобы потом легко извлекать и запускать их при необходимости.
Какие форматы файлов обычно используют для хранения SQL-скриптов?
Для хранения SQL-скриптов чаще всего используются текстовые файлы с расширением .sql. Это стандартный формат, поддерживаемый большинством СУБД. Такие файлы могут быть открыты в любом текстовом редакторе, а также легко импортированы в систему управления базами данных для выполнения. В некоторых случаях могут использоваться и другие форматы, такие как .txt, если скрипт не содержит специфических SQL-операций, но это реже.
Как безопасно хранить и управлять SQL-скриптами?
Для безопасного хранения SQL-скриптов рекомендуется использовать систему контроля версий, такую как Git. Это позволяет отслеживать изменения, хранить различные версии скриптов и легко работать в команде. Также важно использовать безопасные места для хранения этих файлов, например, зашифрованные хранилища, чтобы предотвратить утечку данных. Кроме того, следует ограничить доступ к скриптам, особенно если они содержат чувствительную информацию о базе данных или её структуре.
Где можно найти готовые скрипты для SQL?
Готовые скрипты для SQL можно найти на различных ресурсах в интернете. Одним из популярных вариантов является GitHub, где пользователи выкладывают свои проекты и скрипты. Также существуют специализированные сайты, такие как Stack Overflow, SQLServerCentral, или сайт Microsoft Docs, на которых можно найти примеры скриптов для различных задач. Кроме того, на форумах и в блогах часто обсуждают типовые решения и делятся кодом, что позволяет быстро находить нужные фрагменты кода для конкретных целей.
Как скрипты SQL хранятся и как их можно организовать?
Скрипты SQL обычно хранятся в текстовых файлах с расширением .sql, которые можно сохранять на локальном диске или в облачных хранилищах, таких как Google Drive или GitHub, для удобного доступа и совместного использования. Важно организовывать такие скрипты по каталогам, разделяя их по функциональности или проектам. Также можно использовать системы управления версиями (например, Git), чтобы отслеживать изменения в скриптах и работать с ними в команде. При организации хранения стоит учитывать, что скрипты, которые изменяют структуру базы данных, обычно выделяют в отдельные файлы или папки, а скрипты для выборки данных — в другие.