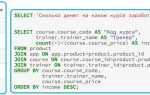
Добавление данных в SQL-таблицу – это операция, без которой не обходится ни одно веб-приложение или корпоративная система. Основная команда – INSERT INTO, и её правильное использование зависит от структуры таблицы, типов данных и необходимости валидации на уровне СУБД. Перед добавлением стоит убедиться, что все обязательные поля указаны, а формат значений соответствует требованиям схемы.
Если таблица содержит автоинкрементное поле, например id, его не нужно указывать явно. Запрос вида INSERT INTO users (name, email) VALUES ('Иван', 'ivan@example.com'); добавит строку, где id сгенерируется автоматически. При этом следует помнить, что нарушение ограничений, таких как NOT NULL или UNIQUE, вызовет ошибку выполнения.
Для пакетного добавления рекомендуется использовать множественные значения: INSERT INTO products (name, price) VALUES ('Товар A', 100), ('Товар B', 150);. Это существенно повышает производительность, особенно при работе с большим объёмом данных. Также важно контролировать транзакции – в случае ошибок их можно откатить, сохранив целостность данных.
При работе с внешними ключами добавление данных должно происходить в правильной последовательности. Сначала заполняются родительские таблицы, затем дочерние. В противном случае будет нарушена ссылка, и СУБД отклонит запрос. Всегда проверяйте наличие связанных записей перед вставкой.
Синтаксис оператора INSERT INTO для одной записи
Оператор INSERT INTO добавляет новую строку в указанную таблицу. Для вставки одной записи используется следующая структура:
INSERT INTO имя_таблицы (столбец1, столбец2, ..., столбецN)
VALUES (значение1, значение2, ..., значениеN);- Имя таблицы – строгое совпадение с существующим объектом в базе.
- Список столбцов указывается в нужном порядке. Пропускать его можно только если значения подаются для всех столбцов и в точном порядке, определённом в схеме таблицы.
- VALUES содержит конкретные значения, соответствующие типам данных каждого из перечисленных столбцов.
Особенности использования:
- Числовые и логические значения указываются без кавычек:
42,TRUE. - Строки заключаются в одинарные кавычки:
'текст'. - Дата и время указываются в формате, соответствующем СУБД, чаще всего
'YYYY-MM-DD'. - NULL передаётся напрямую, без кавычек:
NULL.
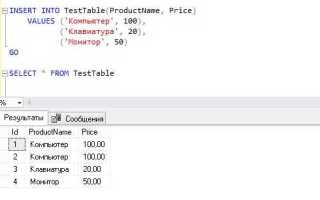
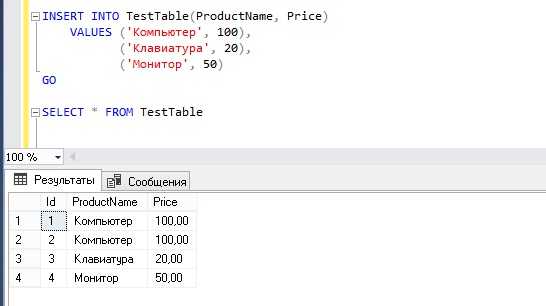
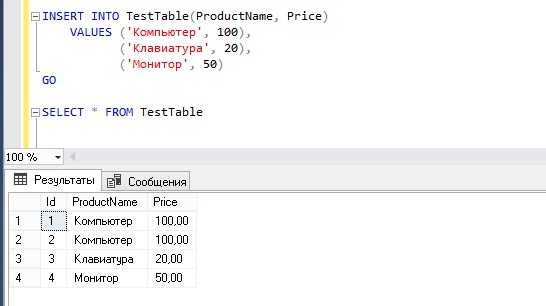
Пример вставки одной строки в таблицу users:
INSERT INTO users (id, name, email, is_active)
VALUES (1, 'Иван', 'ivan@example.com', TRUE);Рекомендации:
- Всегда указывайте список столбцов – это защищает от ошибок при изменении структуры таблицы.
- Проверяйте типы данных перед вставкой: несоответствие вызовет ошибку выполнения.
- Используйте подготовленные выражения или параметры при вставке данных из внешнего ввода для защиты от SQL-инъекций.
Добавление нескольких строк одной командой INSERT
Синтаксис позволяет указать несколько наборов значений через запятую после списка столбцов:
INSERT INTO employees (name, position, salary) VALUES ('Иванов', 'Менеджер', 70000), ('Петров', 'Аналитик', 65000), ('Сидоров', 'Разработчик', 80000);
Все строки должны содержать одинаковое количество значений, соответствующих указанным столбцам. Порядок и типы данных должны строго совпадать со структурой таблицы.
Для крупных наборов данных лучше группировать вставку по 500–1000 строк за раз. Это оптимальный баланс между производительностью и стабильностью, особенно при работе с ограничениями памяти или сетевыми задержками.
Если требуется вставлять данные программно, предпочтительнее использовать подготовленные выражения с параметризацией, что минимизирует риск SQL-инъекций и упрощает пакетную обработку.
Некоторые СУБД, например PostgreSQL, позволяют использовать расширение RETURNING для получения идентификаторов добавленных строк сразу после вставки. Это особенно полезно при добавлении связанных данных в другие таблицы.
Использование подзапроса в INSERT INTO. SELECT
Подзапрос в конструкции INSERT INTO ... SELECT позволяет копировать данные из одной таблицы в другую без промежуточных операций на стороне клиента. Это особенно эффективно при переносе данных, формировании архивов или агрегации записей по определённым условиям.
Синтаксис:
INSERT INTO целевая_таблица (колонка1, колонка2, ...)
SELECT колонка1, колонка2, ... FROM источник WHERE условие;
Количество и порядок колонок в SELECT должны строго соответствовать списку колонок в INSERT INTO. Типы данных должны быть совместимы: например, нельзя вставить строку в числовое поле без преобразования.
Пример: перенос активных пользователей в таблицу архивных записей:
INSERT INTO архив_пользователей (id, имя, email)
SELECT id, имя, email FROM пользователи WHERE активен = false;
Рекомендуется использовать фильтрацию и предикаты в подзапросе, чтобы избежать дублирования и вставки лишних данных. При наличии уникальных ограничений следует дополнительно проверять, что подзапрос не приведёт к нарушению ограничений уникальности или внешних ключей.
Если требуется трансформировать данные при вставке, можно использовать функции и выражения в SELECT. Пример:
INSERT INTO продажи_архив (дата, сумма)
SELECT дата_продажи, сумма * 1.2 FROM продажи WHERE год = 2024;
Неэффективное использование: вставка всех записей без фильтра или повторяющиеся запросы без ограничений – это создаёт избыточные данные и нагрузку на СУБД. Используйте EXISTS или NOT EXISTS в подзапросе для дополнительной проверки перед вставкой:
INSERT INTO новые_товары (id, название)
SELECT id, название FROM товары t
WHERE NOT EXISTS (SELECT 1 FROM новые_товары n WHERE n.id = t.id);
Добавление данных с пропущенными значениями для некоторых столбцов
При вставке данных в таблицу SQL не обязательно указывать значения для всех столбцов, если для них заданы значения по умолчанию или разрешены NULL. Пример:
INSERT INTO сотрудники (имя, должность) VALUES ('Иванов Пётр', 'инженер');
Если в таблице столбец отдел допускает NULL или имеет значение по умолчанию, его можно не указывать в запросе. При этом важно знать структуру таблицы – убедитесь, что отсутствующие поля не обязательны (не имеют ограничения NOT NULL без значения по умолчанию).
Чтобы проверить, какие столбцы допускают пропуски, используйте описание таблицы:
DESCRIBE сотрудники; или PRAGMA table_info(сотрудники); для SQLite.
Если требуется явно задать NULL, используйте ключевое слово:
INSERT INTO сотрудники (имя, должность, отдел) VALUES ('Сидорова Анна', 'аналитик', NULL);
Никогда не вставляйте пустые строки (») вместо NULL, если поле предназначено для хранения чисел или дат – это приведёт к ошибкам при обработке. Всегда используйте NULL по назначению.
Если пропущенные значения предполагаются регулярно, рекомендуется на этапе проектирования базы данных указывать значения по умолчанию для соответствующих столбцов:
ALTER TABLE сотрудники ALTER COLUMN отдел SET DEFAULT 'не указан';
Такое решение упрощает вставку записей без необходимости вручную управлять каждым пропущенным значением.
Работа с автоинкрементными полями при вставке записей
При вставке новой записи не указывайте значение автоинкрементного поля. Например, если столбец id является автоинкрементным, используйте:
INSERT INTO users (name, email) VALUES (‘Иван’, ‘ivan@example.com’);
В MySQL типичный способ задать автоинкремент – INT AUTO_INCREMENT PRIMARY KEY. В PostgreSQL следует использовать SERIAL или GENERATED BY DEFAULT AS IDENTITY. В SQL Server – INT IDENTITY(1,1).
Чтобы получить последнее сгенерированное значение после вставки:
MySQL: SELECT LAST_INSERT_ID();
PostgreSQL: RETURNING id в запросе INSERT или SELECT currval(‘sequence_name’);
SQL Server: SELECT SCOPE_IDENTITY();
Если вы попытаетесь вручную задать значение автоинкрементного поля, это может привести к конфликту с текущим значением счетчика. Чтобы избежать ошибок, явно задавайте значение только при миграциях или импорте данных, и только если СУБД это поддерживает.
Для сброса автоинкрементного счетчика используйте:
MySQL: ALTER TABLE users AUTO_INCREMENT = 1;
PostgreSQL: ALTER SEQUENCE users_id_seq RESTART WITH 1;
SQL Server: DBCC CHECKIDENT (‘users’, RESEED, 0);
Контролируйте доступ к автоинкрементным полям на уровне приложения или прав пользователей, чтобы исключить возможность их изменения вручную.
Обработка ошибок при дублирующих ключах при вставке
При вставке данных в таблицы SQL базы данных часто возникает ситуация, когда попытка добавить запись с уже существующим значением уникального или первичного ключа вызывает ошибку. Это может привести к прерыванию выполнения транзакции и потере данных, если ошибка не будет должным образом обработана. Важно учитывать несколько методов для эффективного управления такими ситуациями.
Первое, что следует учесть – это использование конструкции INSERT ON DUPLICATE KEY UPDATE для MySQL и MariaDB, которая позволяет обновить существующую запись, если ключ уже присутствует в базе. Например, следующая команда вставляет данные, а если ключ уже существует, обновляет указанные поля:
INSERT INTO users (id, name, email) VALUES (1, 'Ivan', 'ivan@example.com')
ON DUPLICATE KEY UPDATE name = 'Ivan', email = 'ivan@example.com';Для PostgreSQL аналогичный эффект можно получить, использовав ON CONFLICT:
INSERT INTO users (id, name, email) VALUES (1, 'Ivan', 'ivan@example.com')
ON CONFLICT (id) DO UPDATE SET name = EXCLUDED.name, email = EXCLUDED.email;Такой подход минимизирует необходимость в дополнительной проверке перед вставкой, однако важно удостовериться, что не происходит нежелательных обновлений данных, которые могут привести к ошибкам логики.
Если же необходимо полностью избежать обновления существующих записей, можно использовать конструкцию INSERT IGNORE (для MySQL), которая просто игнорирует вставку в случае дублирующего ключа:
INSERT IGNORE INTO users (id, name, email) VALUES (1, 'Ivan', 'ivan@example.com');Для PostgreSQL такой функционал реализуется через ON CONFLICT DO NOTHING, что исключает вставку, если конфликт ключей уже произошел:
INSERT INTO users (id, name, email) VALUES (1, 'Ivan', 'ivan@example.com')
ON CONFLICT (id) DO NOTHING;Важно помнить, что использование ON DUPLICATE KEY UPDATE и ON CONFLICT не только предотвращает ошибки, но и может скрыть проблемы в данных, особенно если обновление происходит с непредсказуемыми значениями. В таких случаях следует рассматривать возможность использования транзакций с явной обработкой ошибок и логированием.
Другой способ обработки ошибок – это использование блоков TRY...CATCH в SQL Server и PostgreSQL для перехвата исключений. Например, для SQL Server можно использовать следующий подход:
BEGIN TRY
INSERT INTO users (id, name, email) VALUES (1, 'Ivan', 'ivan@example.com');
END TRY
BEGIN CATCH
PRINT 'Ошибка при вставке: ' + ERROR_MESSAGE();
END CATCH;Для PostgreSQL используется блок EXCEPTION, позволяющий перехватывать ошибки и обрабатывать их отдельно:
BEGIN
INSERT INTO users (id, name, email) VALUES (1, 'Ivan', 'ivan@example.com');
EXCEPTION WHEN unique_violation THEN
RAISE NOTICE 'Ошибка: запись с таким ключом уже существует.';
END;Такой подход позволяет не только отлавливать ошибки, но и делать обработку более гибкой, например, записывать информацию о возникших проблемах в отдельные логи или предпринимать другие действия для сохранения целостности данных.
Примеры вставки данных из внешних источников с использованием SQL
Прежде чем начать, стоит помнить, что источник данных должен быть заранее подготовлен: в нем не должно быть ошибок или недочетов, которые могут повлиять на качество вставляемых данных. Рассмотрим следующие методы.
1. Вставка данных через CSV-файлы
Если данные находятся в CSV-файле, процесс импорта можно осуществить с помощью команды LOAD DATA INFILE для MySQL или аналогичной для других СУБД.
LOAD DATA INFILE '/path/to/data.csv' INTO TABLE my_table FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n' IGNORE 1 LINES;
В этом примере данные из файла data.csv загружаются в таблицу my_table, где каждый столбец разделяется запятой, а строки – символом новой строки. Команда IGNORE 1 LINES пропускает заголовок файла, если он присутствует.
2. Вставка данных через программный интерфейс
Данные также могут поступать из внешнего источника через API. Для этого можно использовать различные библиотеки, например, requests в Python, чтобы получить данные в формате JSON или XML, а затем вставить их в базу данных.
import requests
import mysql.connector
# Получение данных из API
response = requests.get('https://example.com/api/data')
data = response.json()
# Соединение с базой данных
db = mysql.connector.connect(
host="localhost",
user="user",
password="password",
database="database"
)
cursor = db.cursor()
# Вставка данных
for item in data:
cursor.execute("INSERT INTO my_table (column1, column2) VALUES (%s, %s)", (item['field1'], item['field2']))
db.commit()
cursor.close()
db.close()
В данном примере происходит извлечение данных из API в формате JSON и их последующая вставка в таблицу с использованием Python и библиотеки mysql.connector.
3. Вставка данных из других баз данных
Иногда данные могут поступать из других баз данных. Для этого используется механизм подключения к удаленной базе данных и выполнение запроса, который извлекает и вставляет данные.
INSERT INTO my_table (column1, column2) SELECT column1, column2 FROM remote_database.remote_table;
Этот запрос позволяет вставить данные из удаленной базы данных remote_database в таблицу my_table в локальной базе. Метод работает, если есть соответствующие разрешения для удаленного соединения.
4. Использование ETL-процессов для интеграции данных

Для более сложных сценариев, например, при обработке больших объемов данных, часто применяются ETL-процессы (Extract, Transform, Load). В таких случаях данные из разных источников сначала извлекаются, затем преобразуются в нужный формат, и только после этого загружаются в таблицу.
Типичный пример использования ETL:
- Извлечение данных из CSV, API или другой базы данных.
- Преобразование данных в нужный формат (например, очистка, фильтрация, агрегация).
- Загрузка преобразованных данных в таблицу с использованием SQL-запросов, таких как
INSERT INTOилиMERGE.
Сложные ETL-процессы часто автоматизируются с помощью инструментов, таких как Apache Nifi или Talend, для упрощения и ускорения работы.
5. Вставка данных через команды INSERT с подзапросами
При интеграции с внешними источниками, если данные уже находятся в другой таблице той же базы данных, можно использовать подзапросы для их вставки:
INSERT INTO target_table (column1, column2) SELECT column1, column2 FROM source_table WHERE condition;
Такой способ позволяет перенести данные без необходимости их выгрузки в промежуточные файлы, что ускоряет процесс и упрощает задачу.