В SQL Server поддерживаются два типа компрессии: ROW и PAGE. Компрессия на уровне строк заменяет повторяющиеся значения более короткими представлениями, тогда как страничная компрессия использует алгоритмы шаблонного сжатия и словари. Для включения компрессии используется команда CREATE TABLE с параметром DATA_COMPRESSION внутри WITH.
В PostgreSQL компрессия реализована на уровне хранения, начиная с версии 14, где появился механизм TOAST compression с поддержкой алгоритмов pglz и lz4. Для применения нужно учитывать размер полей и типы данных – сжатие эффективно работает с большими текстовыми и бинарными полями.
В MySQL компрессия возможна через использование формата ROW_FORMAT=COMPRESSED в комбинации с движком InnoDB. Дополнительно нужно задать параметр KEY_BLOCK_SIZE, от которого зависит уровень компрессии. Наибольшую выгоду компрессия даёт при работе с индексируемыми текстовыми данными.
Перед включением компрессии важно протестировать производительность на реальных нагрузках, так как компрессия увеличивает потребление CPU. Также стоит оценить влияние на планы выполнения запросов и возможные ограничения, например, невозможность сжатия некоторых типов столбцов.
Выбор типа компрессии: строковая, страничная или колонковая
Строковая компрессия применяется на уровне отдельной строки и эффективна при хранении большого количества записей с повторяющимися значениями в пределах одной строки. Она снижает объем данных за счет устранения дублирующих элементов внутри строки. Рекомендуется использовать в OLTP-системах, где доминируют операции вставки и обновления. Недостаток – низкая степень сжатия при разнообразных данных в строке.
Страничная компрессия работает на уровне 8-килобайтных страниц и предоставляет более высокий коэффициент сжатия за счет анализа повторяющихся шаблонов в пределах всей страницы. Она подходит для умеренно читаемых и редактируемых данных. Эффективна при частом использовании одних и тех же значений в разных строках. Заметное снижение размера таблицы достигается без значительного влияния на производительность при чтении.
Колонковая компрессия оптимизирована для аналитических нагрузок и хранения данных в формате колоночных хранилищ. Применяется в системах, где чтение происходит по столбцам, а не по строкам. Позволяет добиться наибольшего сжатия, особенно при высокооднотипных данных в пределах одного столбца. Однако она требует поддержки колоночного хранения, например, в SQL Server – это Columnstore Index. Использование нецелесообразно в системах с интенсивными транзакциями.
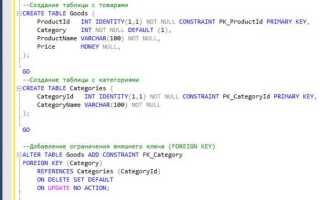
Создание таблицы с компрессией в Microsoft SQL Server

Пример создания таблицы с включенной компрессией строк:
CREATE TABLE Orders_Compressed
(
OrderID INT PRIMARY KEY,
OrderDate DATETIME,
CustomerID INT,
TotalAmount MONEY
)
WITH (DATA_COMPRESSION = ROW) ON [PRIMARY];Для сжатия на уровне страниц:
CREATE TABLE Orders_Compressed_Page
(
OrderID INT PRIMARY KEY,
OrderDate DATETIME,
CustomerID INT,
TotalAmount MONEY
)
WITH (DATA_COMPRESSION = PAGE) ON [PRIMARY];Для включения компрессии на существующей таблице используется команда ALTER TABLE:
ALTER TABLE Orders REBUILD PARTITION = ALL
WITH (DATA_COMPRESSION = PAGE);Сжатие эффективно при работе с большими объёмами повторяющихся данных. Перед применением рекомендуется выполнить оценку потенциального выигрыша с помощью встроенной процедуры:
sp_estimate_data_compression_savings
@schema_name = 'dbo',
@object_name = 'Orders',
@index_id = NULL,
@partition_number = NULL,
@data_compression = 'PAGE';Компрессия снижает размер таблиц и нагрузку на дисковую подсистему, но увеличивает нагрузку на CPU. Выбор типа сжатия зависит от структуры данных и частоты обращений. Рекомендуется тестировать производительность до и после применения изменений.
Применение компрессии при помощи ALTER TABLE
Для включения компрессии на существующей таблице используется команда ALTER TABLE с указанием подходящего типа сжатия. В PostgreSQL, начиная с версии 14, поддерживается метод TOAST-компрессии, который можно изменить через ALTER TABLE ... SET STORAGE и ALTER TABLE ... ALTER COLUMN ... SET COMPRESSION. Пример: ALTER TABLE документы ALTER COLUMN содержание SET COMPRESSION lz4; – включает использование алгоритма LZ4 для хранения содержимого в колонке.
В Oracle используется ALTER TABLE имя ENABLE ROW MOVEMENT и далее ALTER TABLE имя COMPRESS FOR OLTP для включения OLTP-сжатия, подходящего для часто изменяемых данных. Для архивных данных применяется COMPRESS FOR ARCHIVE.
В Microsoft SQL Server компрессия задаётся через ALTER TABLE имя REBUILD PARTITION = ALL WITH (DATA_COMPRESSION = PAGE) или ROW, где PAGE обеспечивает более высокую степень сжатия, включая индексные страницы, в отличие от ROW.
Перед применением необходимо убедиться, что таблица не участвует в ограничениях, препятствующих перестроению (например, активные репликации или индексные зависимости). Также важно провести оценку выигрыша в объёме хранения и влияния на производительность с помощью sp_estimate_data_compression_savings в SQL Server или EXPLAIN ANALYZE в PostgreSQL после включения компрессии.
Проверка текущего состояния компрессии таблицы
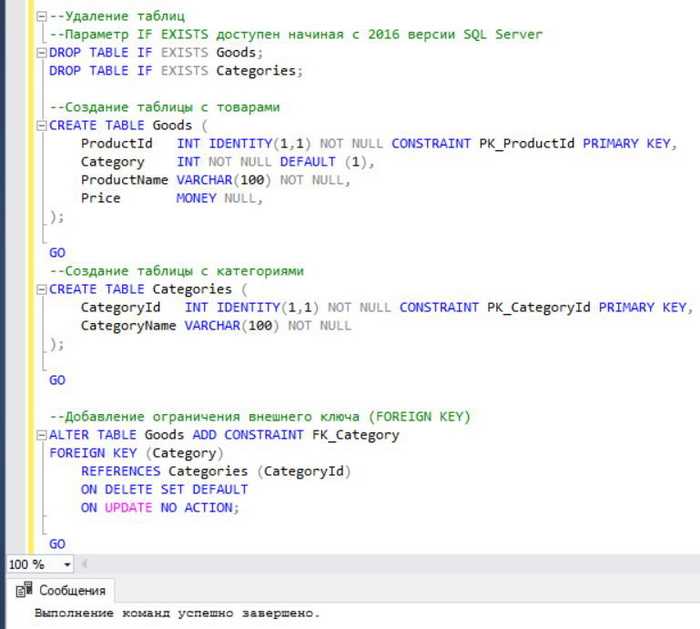
Для определения текущего типа компрессии таблицы в SQL Server используйте представление системного каталога sys.partitions в сочетании с sys.tables и sys.indexes. Ключевое поле – data_compression, которое указывает режим сжатия: 0 – NONE, 1 – ROW, 2 – PAGE.
Пример запроса:
SELECT
t.name AS TableName,
i.name AS IndexName,
p.partition_number,
p.data_compression_desc
FROM
sys.partitions p
JOIN
sys.indexes i ON p.object_id = i.object_id AND p.index_id = i.index_id
JOIN
sys.tables t ON i.object_id = t.object_id
WHERE
t.name = 'Имя_Вашей_Таблицы';
Если таблица содержит несколько партиций, проверьте каждую из них. Компрессия может быть разной для каждой партиции. Значение data_compression_desc покажет, активирован ли режим строковой или страничной компрессии.
Для анализа фактической эффективности компрессии рекомендуется использовать хранимую процедуру sp_estimate_data_compression_savings, сравнивающую текущий и предполагаемый объем данных при смене режима сжатия. Это позволяет точно оценить, стоит ли применять компрессию и какой её тип выбрать.
Оценка выигрыша от компрессии с помощью sp_estimate_data_compression_savings

Для оценки выигрыша от применения компрессии данных в SQL Server можно использовать системную хранимую процедуру sp_estimate_data_compression_savings. Эта процедура предоставляет информацию о возможном уменьшении объема данных при различных типах компрессии, что помогает понять потенциальные выгоды от использования компрессии на уровне таблиц или индексов.
Процедура sp_estimate_data_compression_savings позволяет рассчитать предполагаемый эффект компрессии для различных типов данных и структур. На основе этой информации можно принять обоснованное решение о целесообразности применения компрессии. Важный момент – процедура не изменяет данные, она только предоставляет расчетный результат, который можно использовать для дальнейших решений.
Для использования sp_estimate_data_compression_savings необходимо указать следующие параметры:
@schema_name– имя схемы таблицы или индекса.@object_name– имя таблицы или индекса, для которых будет оценена компрессия.@partition_number– номер партиции (если нужно оценить компрессию для конкретной партиции, если она существует).@index_id– идентификатор индекса (если применяется к индексу).@data_compression– тип компрессии:NONE,ROW,PAGEилиCOLUMNSTORE.
Рассмотрим пример вызова процедуры:
EXEC sp_estimate_data_compression_savings
@schema_name = 'dbo',
@object_name = 'SalesOrders',
@data_compression = 'PAGE';
Процедура вернет приблизительный размер данных после применения выбранной компрессии, что позволяет оценить возможную экономию места на диске.
При интерпретации результатов следует учитывать следующие моменты:
- Реальные результаты могут отличаться: расчет предоставляет приблизительную оценку, основанную на статистике таблицы и данных. Фактический выигрыш зависит от особенностей данных.
- Типы данных: Некоторые типы данных (например, текстовые и бинарные поля) могут не давать значительного выигрыша при компрессии. Лучше всего компрессия работает с числовыми и строковыми данными, содержащими повторяющиеся значения.
- Параметры компрессии: Компрессия с использованием
ROWиPAGEподходит для традиционных таблиц, аCOLUMNSTORE– для аналитических нагрузок, где важна эффективность хранения и скорости запросов.
Рекомендуется использовать sp_estimate_data_compression_savings на этапах предварительного анализа, чтобы избежать излишних затрат на компрессию, которая может не дать значительного эффекта. Таким образом, оценка возможного выигрыша позволяет более точно планировать ресурсы и избегать ненужных операций.
Ограничения и нюансы при использовании компрессии на разных типах данных
Компрессия данных в SQL может значительно улучшить производительность и экономить место на диске, но ее эффективность зависит от типа данных, который используется. Разные типы данных могут иметь разные реакции на компрессию, и важно учитывать их особенности при принятии решений.
Текстовые данные (например, CHAR, VARCHAR, TEXT) обычно хорошо сжимаются, поскольку часто содержат повторяющиеся символы или слова. Однако, если строка слишком короткая или содержит много уникальных символов, компрессия может не дать ощутимых преимуществ. Для таких данных рекомендуется использовать алгоритмы компрессии, поддерживающие эффективное сжатие длинных строк с повторяющимися шаблонами, такие как Run-Length Encoding (RLE).
Для целочисленных данных (INT, BIGINT) компрессия может быть менее эффективной. Эти типы данных часто имеют небольшие значения, что затрудняет использование стандартных методов сжатия. Однако, при хранении больших массивов чисел с одинаковыми значениями или в пределах одного диапазона, компрессия может заметно сократить объем данных. В таких случаях следует применять алгоритмы, которые эффективно сжимаются по диапазонам значений, например, Delta Encoding.
Для двоичных данных (BLOB, BINARY, VARBINARY) компрессия может быть эффективной только в случае, если данные содержат повторяющиеся паттерны или блоки. Если данные имеют случайную структуру, например, криптографические хеши или сжатые файлы, компрессия не только не приведет к экономии пространства, но и может увеличить размер хранения из-за накладных расходов на алгоритмы сжатия. Для таких типов данных стоит осторожно подходить к выбору компрессии, а в некоторых случаях вообще избегать ее.
Особое внимание стоит уделить дата- и временным данным (DATE, TIME, DATETIME). Эти типы данных, как правило, занимают фиксированное количество байт, и их компрессия вряд ли принесет значительную выгоду, если только данные не имеют паттернов, таких как одинаковые или схожие временные метки. Для улучшения сжатия можно использовать схемы, ориентированные на хранение разницы между временными метками, что позволит уменьшить объем данных при хранении большого количества записей.
Типы данных с плавающей точкой (FLOAT, DOUBLE) представляют собой числа с нефиксированной точностью. Из-за особенностей представления чисел с плавающей запятой, сжатие таких данных часто имеет ограниченную эффективность. В случаях, когда необходимо хранить большое количество значений с одинаковой точностью, лучше использовать методы, которые сохраняют только отличия в значениях, такие как Floating-Point Delta Encoding.
Кроме того, важно учитывать, что использование компрессии может негативно повлиять на производительность при частых обновлениях данных. Когда данные часто изменяются, затраты на компрессию и декомпрессию могут быть выше, чем выгода от уменьшения объема хранения. Это особенно актуально для данных с высокой частотой обновлений или многократных операций записи.
Таким образом, перед применением компрессии необходимо провести анализ данных, их структуры и предполагаемого использования, чтобы выбрать оптимальный метод компрессии и избежать излишних затрат на ресурсы при обновлениях и запросах.
Вопрос-ответ:
Что такое компрессия данных в SQL и зачем она нужна при создании таблиц?
Компрессия данных в SQL — это процесс сжатия информации в таблице с целью уменьшения объема занимаемого пространства. Это может быть полезно при работе с большими объемами данных, так как позволяет экономить дисковое пространство, ускорять обработку запросов и снижать нагрузку на сервер. Особенно полезна компрессия в случаях, когда таблицы содержат повторяющиеся данные, такие как текстовые строки или числовые значения, которые можно эффективно сжать.
Как создать таблицу с компрессией в SQL?
Для создания таблицы с компрессией в SQL обычно используются специальные настройки при определении таблицы или столбцов. Например, в SQL Server можно использовать параметр `ROWSTORE COMPRESSION` или `PAGE COMPRESSION`, который позволяет сжимать данные на уровне строк или страниц. В MySQL для сжатия данных можно использовать движок хранения InnoDB с параметром `COMPRESSED`. Процесс создания такой таблицы в обоих случаях зависит от используемой системы управления базами данных, но общий принцип заключается в том, чтобы при создании таблицы указать нужную опцию сжатия данных.
Какие недостатки компрессии данных в SQL могут возникнуть при использовании в реальных проектах?
Одним из основных недостатков использования компрессии данных в SQL является то, что процесс сжатия и распаковки данных может потребовать дополнительных вычислительных ресурсов, что иногда может замедлять выполнение запросов, особенно при сложных операциях чтения или записи. Также стоит учитывать, что не все типы данных могут быть эффективно сжаты, и в некоторых случаях компрессия может не дать значительного выигрыша в объеме. Важно также учитывать, что компрессия требует дополнительной настройки и тестирования, чтобы добиться оптимальной производительности для конкретного проекта.