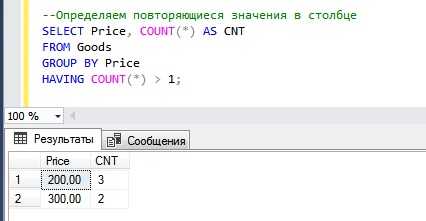
Повторяющиеся значения в базе данных могут указывать на дублирование данных, ошибки ввода или особенности бизнес-логики. Для их выявления в SQL используется конструкция GROUP BY совместно с агрегатной функцией COUNT(). Например, чтобы найти повторяющиеся email-адреса в таблице users, нужно сгруппировать строки по столбцу email и отфильтровать группы с количеством больше одного: SELECT email FROM users GROUP BY email HAVING COUNT(*) > 1.
Если требуется не только значение, но и полные строки с дубликатами, используют подзапрос. Например: SELECT * FROM users WHERE email IN (SELECT email FROM users GROUP BY email HAVING COUNT(*) > 1). Такой подход позволяет анализировать контекст повторяющихся данных, включая другие столбцы – имя, дата регистрации и др.
При работе с несколькими столбцами важно учитывать, что SQL сравнивает точные совпадения. Для нахождения повторов по комбинации, например, имя и дата рождения, используется: SELECT name, birth_date FROM users GROUP BY name, birth_date HAVING COUNT(*) > 1. Такой запрос выявит пользователей с совпадающими анкетными данными, что особенно актуально при проверке корректности импортированных данных.
Чтобы избежать случайных совпадений, важно нормализовать данные до выполнения запроса: привести строки к одному регистру, убрать пробелы, привести даты к единому формату. Это можно сделать с помощью функций LOWER(), TRIM(), TO_CHAR() или аналогов, в зависимости от СУБД.
Как найти дубликаты по одному столбцу с помощью GROUP BY и HAVING
Чтобы выявить дубликаты по конкретному столбцу, используйте комбинацию операторов GROUP BY и HAVING, позволяющую сгруппировать записи и отобрать те, где количество повторений превышает один.
- Выберите интересующий столбец – это может быть, например,
emailв таблице пользователей. - Сгруппируйте данные по этому столбцу с помощью
GROUP BY. - Добавьте условие
HAVING COUNT(*) > 1, чтобы оставить только повторяющиеся значения.
Пример запроса:
SELECT email
FROM users
GROUP BY email
HAVING COUNT(*) > 1;Такой запрос вернёт все адреса электронной почты, которые встречаются более одного раза. Чтобы получить больше информации о записях с дубликатами, объедините этот запрос с подзапросом или используйте IN:
SELECT *
FROM users
WHERE email IN (
SELECT email
FROM users
GROUP BY email
HAVING COUNT(*) > 1
);Для ускорения выполнения на больших объёмах данных обязательно проверьте наличие индекса на столбце, по которому ищете дубликаты.
Как извлечь все строки с повторяющимся значением без удаления уникальных
Для извлечения строк с повторяющимися значениями без удаления уникальных в SQL, можно использовать конструкцию с функцией COUNT() в сочетании с подзапросами или оконными функциями. Этот подход позволяет выбрать только те строки, где значение в одном из столбцов встречается более одного раза.
Пример запроса для получения всех строк с повторяющимися значениями в столбце column_name:
SELECT *
FROM table_name
WHERE column_name IN (
SELECT column_name
FROM table_name
GROUP BY column_name
HAVING COUNT(*) > 1
);В данном примере внешний запрос выбирает все строки, где значение в столбце column_name встречается более одного раза. Подзапрос группирует строки по этому столбцу и фильтрует группы с количеством элементов больше одного, что позволяет избирательно вернуть только повторяющиеся значения.
Для работы с большими данными рекомендуется использовать оконные функции, так как они позволяют более эффективно работать с наборами данных и избегать дополнительных операций с подзапросами.
Пример с использованием оконной функции COUNT():
SELECT *
FROM (
SELECT *, COUNT(*) OVER (PARTITION BY column_name) AS cnt
FROM table_name
) AS subquery
WHERE cnt > 1;Здесь функция COUNT() OVER (PARTITION BY column_name) подсчитывает количество вхождений каждого значения в столбце column_name без необходимости группировать данные. Внешний запрос фильтрует строки, где количество больше одного.
Оба метода позволяют извлечь все строки с повторяющимися значениями, сохраняя уникальные строки в результирующем наборе данных. Выбор между ними зависит от специфики задачи и производительности при работе с большими объемами данных.
Как определить количество повторений каждого значения в таблице

Для определения количества повторений каждого значения в таблице SQL используется агрегатная функция COUNT() вместе с оператором GROUP BY. Это позволяет сгруппировать данные по уникальным значениям и подсчитать их количество в каждой группе.
Простой пример запроса, который позволяет определить количество повторений каждого значения в таблице, выглядит так:
SELECT колонка, COUNT(*)
FROM таблица
GROUP BY колонка;Где:
колонка– это имя столбца, по которому будет производиться группировка;COUNT(*)– подсчитывает количество строк для каждой уникальной записи в выбранной колонке;таблица– имя таблицы, в которой проводится анализ.
При необходимости можно добавить условие с помощью HAVING для фильтрации результатов. Например, чтобы вывести только те значения, которые встречаются более одного раза, можно использовать такой запрос:
SELECT колонка, COUNT(*)
FROM таблица
GROUP BY колонка
HAVING COUNT(*) > 1;Кроме того, COUNT() можно комбинировать с другими функциями для более сложных запросов. Например, если вам нужно подсчитать количество повторений уникальных значений в нескольких столбцах, можно сделать так:
SELECT колонка1, колонка2, COUNT(*)
FROM таблица
GROUP BY колонка1, колонка2;Этот запрос возвращает количество повторений для каждой комбинации значений в колонка1 и колонка2.
Не забывайте, что использование GROUP BY приводит к созданию группы для каждого уникального значения в указанном столбце. Если столбец содержит NULL, то все строки с NULL значениями будут сгруппированы вместе.
В некоторых случаях полезно использовать индекс на колонке, по которой будет производиться группировка, чтобы ускорить выполнение запроса, особенно при работе с большими объемами данных.
Как отобрать только одну строку из каждой группы повторяющихся записей
Рассмотрим пример: у вас есть таблица employees с данными о сотрудниках, в которой встречаются дубли по полю email, и вы хотите оставить только одну запись для каждого уникального адреса электронной почты.
Для этого можно использовать оконную функцию ROW_NUMBER(), которая присваивает уникальный порядковый номер каждой строке в группе, сортируя их по нужному полю. Например, если мы хотим выбрать только первую строку для каждого уникального email, запрос будет выглядеть так:
WITH RankedEmployees AS (
SELECT
employee_id,
email,
ROW_NUMBER() OVER (PARTITION BY email ORDER BY employee_id) AS rn
FROM employees
)
SELECT
employee_id,
email
FROM RankedEmployees
WHERE rn = 1;
В данном запросе:
ROW_NUMBER() OVER (PARTITION BY email ORDER BY employee_id)генерирует уникальный номер для каждой строки в группе с одинаковым email, сортируя их поemployee_id;- Внешний запрос отбирает только те записи, где номер строки равен 1, то есть первую запись из каждой группы.
Если необходимо выбрать строки с другим порядком, например, по дате или другому полю, измените условие сортировки в функции ORDER BY.
Этот метод подходит для ситуаций, когда нужно отобрать одну строку, но при этом нет явных агрегатных данных, таких как максимальные или минимальные значения, которые могли бы быть использованы для группировки.
Кроме того, стоит учитывать, что ROW_NUMBER() можно эффективно использовать в запросах с большими объемами данных, так как оконные функции не требуют выполнения дополнительных подзапросов или джоинов, что может улучшить производительность.
Как найти дубликаты с учетом нескольких столбцов одновременно
Для поиска дубликатов с учетом нескольких столбцов в SQL необходимо использовать конструкцию GROUP BY в сочетании с агрегатными функциями, например, COUNT(). Такой подход позволяет выделить строки, которые повторяются по заданному набору столбцов.
Основной принцип заключается в том, чтобы сгруппировать строки по выбранным столбцам и отфильтровать те, которые встречаются больше одного раза. Пример запроса:
SELECT column1, column2, COUNT(*) FROM table_name GROUP BY column1, column2 HAVING COUNT(*) > 1;
В этом запросе:
- column1, column2 – столбцы, по которым ищутся дубликаты;
- COUNT(*) – подсчитывает количество строк для каждой группы;
- HAVING COUNT(*) > 1 – фильтрует группы, которые встречаются более одного раза.
Если необходимо получить все строки, а не только значения столбцов, участвующих в группировке, можно использовать подзапросы или JOIN. Пример:
SELECT t.* FROM table_name t INNER JOIN ( SELECT column1, column2 FROM table_name GROUP BY column1, column2 HAVING COUNT(*) > 1 ) dup ON t.column1 = dup.column1 AND t.column2 = dup.column2;
Этот запрос возвращает все строки из исходной таблицы, которые имеют повторяющиеся значения в столбцах column1 и column2.
Для поиска дубликатов, включающих более трех столбцов, достаточно добавить дополнительные столбцы в конструкцию GROUP BY и HAVING. Например:
SELECT column1, column2, column3, COUNT(*) FROM table_name GROUP BY column1, column2, column3 HAVING COUNT(*) > 1;
Этот запрос позволяет находить дубликаты по трем столбцам одновременно, что бывает полезно, когда требуется учесть несколько факторов при поиске повторений.
Для повышения производительности при работе с большими объемами данных можно создавать индексы по используемым столбцам, что ускорит выполнение таких запросов. Особенно это важно, если таблица содержит миллионы строк.
Как использовать оконные функции для анализа повторяющихся данных
Оконные функции в SQL позволяют выполнить вычисления, учитывая соседние строки в пределах определенного окна, что идеально подходит для поиска и анализа повторяющихся значений. Основное преимущество оконных функций в том, что они не требуют агрегации строк, что позволяет сохранить все данные в исходном виде.
Для анализа повторяющихся данных удобно использовать оконные функции, такие как ROW_NUMBER(), RANK(), DENSE_RANK() и COUNT(). Они помогают выделить дубликаты, а также понять их распределение по различным критериям.
Пример: если нужно найти строки с одинаковыми значениями в определенном столбце, можно применить функцию COUNT() с оконным разделением по этому столбцу. Например, запрос, который подсчитывает количество повторяющихся значений в колонке product_id:
SELECT product_id, COUNT(*) OVER (PARTITION BY product_id) AS product_count
FROM sales
Этот запрос вернет количество повторений для каждого product_id. Если вам нужно выделить только те строки, где повторения больше одного, используйте условие в HAVING:
SELECT product_id, COUNT(*) OVER (PARTITION BY product_id) AS product_count
FROM sales
HAVING COUNT(*) OVER (PARTITION BY product_id) > 1
Функция ROW_NUMBER() полезна для присваивания уникальных порядковых номеров строкам в рамках каждого окна. Она может помочь при идентификации дубликатов с сохранением одного из них, например, выбрать только первую запись для каждого повторяющегося значения:
WITH ranked_sales AS (
SELECT product_id, ROW_NUMBER() OVER (PARTITION BY product_id ORDER BY sale_date) AS row_num
FROM sales
)
SELECT product_id, sale_date
FROM ranked_sales
WHERE row_num = 1
Для более сложных анализов, например, при необходимости учета равенства значений (например, для сортировки одинаковых значений по датам или количествам), можно использовать RANK() или DENSE_RANK(). Эти функции дают возможность отличить строки, которые имеют одинаковые значения, но отличаются по другому признаку.
Когда требуется анализировать повторяющиеся данные с учетом нескольких факторов, оконные функции позволяют эффективно разделить данные по нужным категориям, не нарушая целостности информации. Оптимальное использование этих функций позволяет быстро и без излишних вычислений выявить дубликаты и аномалии в больших объемах данных.