В SQL выбор уникальных значений из таблицы – это одна из базовых задач, которая часто требуется при анализе данных или подготовке отчетности. Обычно для этого используют оператор DISTINCT, но в некоторых случаях могут быть полезны и другие методы, в зависимости от структуры данных и целей запроса.
Когда необходимо получить уникальные значения, наиболее распространенным инструментом является команда SELECT DISTINCT, которая позволяет отфильтровывать повторяющиеся строки. Однако важно понимать, что эта операция может быть ресурсоемкой на больших объемах данных, так как база данных должна провести дополнительную работу по сравнению всех записей.
Для более точного контроля над уникальностью данных часто используются другие подходы. Например, можно комбинировать GROUP BY с агрегатными функциями, такими как COUNT() или MAX(), чтобы отобрать уникальные значения с определенными условиями. Этот метод дает больше гибкости и позволяет фильтровать данные на основе сложных критериев.
Еще один способ – использование подзапросов или ROW_NUMBER() в сочетании с оконными функциями, что может быть полезно в ситуациях, когда требуется отобрать уникальные записи с дополнительными вычислениями или сортировкой. Такой подход значительно сокращает количество данных, которые нужно обработать в результате запроса, что может быть полезно для повышения производительности.
Использование оператора DISTINCT для получения уникальных значений
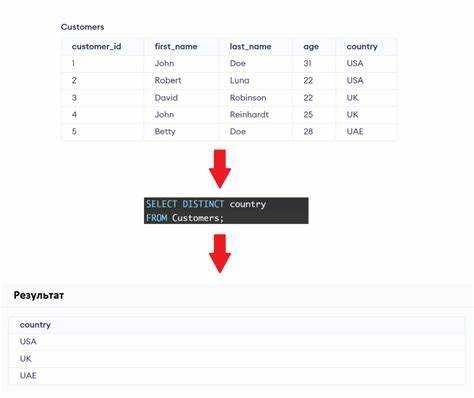
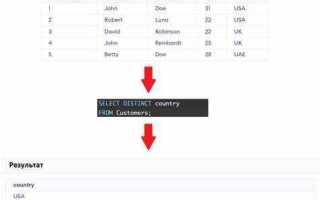
Оператор DISTINCT используется в SQL для выборки уникальных значений из колонок таблицы. Он позволяет исключить дублирующиеся записи, что особенно полезно при анализе данных или извлечении отдельных значений из больших наборов данных.
Для применения DISTINCT достаточно указать его перед списком колонок в запросе. Например, запрос:
SELECT DISTINCT column_name FROM table_name;
вернёт только уникальные значения из указанной колонки. Это избавляет от необходимости вручную фильтровать дубли. Важно помнить, что DISTINCT работает на уровне строки: если одна строка имеет одинаковые значения во всех выбранных колонках, то такая строка будет исключена из результатов. Для получения уникальных комбинаций значений в нескольких колонках можно использовать DISTINCT с несколькими полями:
SELECT DISTINCT column1, column2 FROM table_name;
Результатом запроса будут уникальные комбинации значений для сочетания колонок column1 и column2. Если в строках встречаются одинаковые значения в обеих колонках, такие строки не будут включены в выборку.
При использовании DISTINCT важно учитывать, что этот оператор может повлиять на производительность запроса, особенно на больших таблицах. Для оптимизации рекомендуется добавлять индексы на те колонки, по которым часто используется DISTINCT.
Если требуется не только уникальные значения, но и подсчёт количества различных записей, можно использовать функцию COUNT с DISTINCT:
SELECT COUNT(DISTINCT column_name) FROM table_name;
Этот запрос вернёт количество уникальных значений в указанной колонке.
Как выбрать уникальные строки по нескольким столбцам
Для выборки уникальных строк по нескольким столбцам в SQL используется ключевое слово DISTINCT. При этом оно применяется ко всем столбцам в запросе, и результат будет включать только те строки, которые полностью уникальны по набору значений в этих столбцах.
Если требуется выбрать уникальные строки по комбинации нескольких столбцов, достаточно указать все эти столбцы после ключевого слова SELECT, а затем применить DISTINCT к этому набору. Например, запрос:
SELECT DISTINCT column1, column2 FROM table_name;вернёт все уникальные комбинации значений из столбцов column1 и column2.
Важно помнить, что DISTINCT работает не по отдельным столбцам, а по всему набору значений в строке. То есть, если значения в столбцах column1 и column2 одинаковы в разных строках, только одна строка будет возвращена.
Для выполнения более сложных фильтраций можно использовать комбинацию GROUP BY и агрегатных функций, например, COUNT() или MAX(), чтобы получить уникальные строки по нескольким столбцам, учитывая дополнительные условия.
Пример с использованием GROUP BY:
SELECT column1, column2, COUNT(*) FROM table_name GROUP BY column1, column2;Этот запрос вернёт уникальные комбинации значений из столбцов column1 и column2, а также количество строк для каждой комбинации.
Если необходимо учитывать уникальность только по определённым столбцам, а не по всей строке, иногда полезно использовать подзапросы или оконные функции. В таких случаях рекомендуется тестировать производительность запросов, поскольку сложные операции с большими объёмами данных могут требовать значительных вычислительных ресурсов.
Применение GROUP BY для получения уникальных комбинаций данных
Оператор GROUP BY используется для агрегации данных по определённому признаку. Он позволяет разделить строки таблицы на группы и применить агрегатные функции (например, COUNT, SUM, AVG) для каждой из групп. Для получения уникальных комбинаций данных часто достаточно правильно настроить этот оператор.
Основная цель GROUP BY – это выделение уникальных комбинаций значений нескольких столбцов. Например, если требуется получить уникальные пары значений двух столбцов, то использование GROUP BY поможет собрать их в отдельные группы.
Пример запроса, который возвращает уникальные комбинации значений из двух столбцов:
SELECT column1, column2 FROM table_name GROUP BY column1, column2;
При необходимости агрегировать данные по нескольким столбцам можно комбинировать GROUP BY с другими функциями. Например, для подсчёта числа уникальных комбинаций значений используется запрос:
SELECT column1, column2, COUNT(*) FROM table_name GROUP BY column1, column2;
В данном случае запрос подсчитает количество строк для каждой уникальной комбинации значений в столбцах column1 и column2. Такой подход полезен при анализе распределения данных по группам.
Если требуется получить уникальные комбинации только для одного столбца, то достаточно использовать:
SELECT DISTINCT column1 FROM table_name;
Этот запрос вернёт только уникальные значения из столбца column1. Однако использование GROUP BY позволяет комбинировать столбцы для более сложных запросов и извлекать полезную информацию о взаимодействии данных между собой.
Рекомендуется всегда учитывать производительность при работе с большими объёмами данных, поскольку операции группировки могут требовать значительных вычислительных ресурсов. Оптимизация запросов с GROUP BY достигается путём индексирования столбцов, по которым выполняется группировка, а также использованием фильтров с WHERE до группировки для уменьшения объёма обрабатываемых данных.
Фильтрация уникальных значений с помощью подзапросов
Подзапросы могут быть полезным инструментом для фильтрации уникальных значений в SQL, особенно когда требуется работать с промежуточными результатами, которые не могут быть сразу получены с помощью стандартных методов фильтрации, таких как DISTINCT. В отличие от прямого использования DISTINCT, подзапросы позволяют более гибко обрабатывать данные, выбирая уникальные элементы на основе более сложных условий.
Для фильтрации уникальных значений с помощью подзапросов часто используется конструкция IN, которая позволяет выбрать данные, которые присутствуют в результатах подзапроса. Например, если необходимо выбрать уникальные значения из одной таблицы на основе значений другой таблицы, можно воспользоваться следующим запросом:
SELECT column_name
FROM table_name
WHERE column_name IN (
SELECT DISTINCT column_name
FROM another_table
);
Этот запрос вернет все уникальные значения из table_name, которые соответствуют значениям из another_table.
Еще одним вариантом является использование подзапроса с условием EXISTS. Этот оператор проверяет наличие хотя бы одного значения, удовлетворяющего условию в подзапросе. Например:
SELECT column_name
FROM table_name t1
WHERE EXISTS (
SELECT 1
FROM another_table t2
WHERE t2.column_name = t1.column_name
);
В этом примере возвращаются строки из table_name, для которых есть соответствующие записи в another_table, что позволяет фильтровать уникальные значения по определенным критериям.
Подзапросы также можно использовать для обработки более сложных условий с уникальными значениями. Например, если требуется выбрать уникальные записи, которые не встречаются в другой таблице:
SELECT column_name
FROM table_name
WHERE column_name NOT IN (
SELECT DISTINCT column_name
FROM another_table
);
Таким образом, подзапросы предоставляют гибкость в выборе уникальных значений, что особенно важно при работе с большими объемами данных и сложными логическими условиями. Важно учитывать, что использование подзапросов может повлиять на производительность запросов, особенно если они используются без оптимизации.
Реализация уникальных значений в таблицах с дубликатами
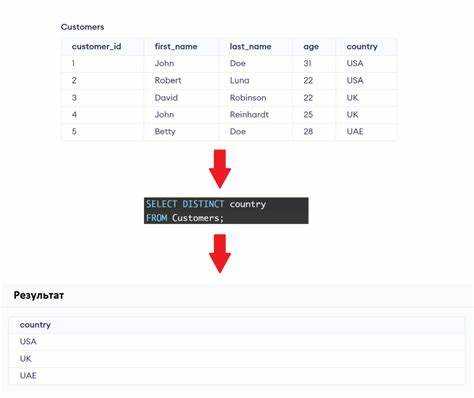
Чтобы исключить дубликаты из таблицы, можно воспользоваться оператором DISTINCT. Он позволяет выбрать только уникальные строки, исключая повторяющиеся записи. Однако важно понимать, что DISTINCT работает по всем столбцам, что может быть не всегда эффективно, если нужно выбрать уникальные значения только по одному столбцу.
Если задача заключается в удалении дубликатов на уровне одного поля, то можно использовать запрос с группировкой. Например, запрос SELECT column_name FROM table_name GROUP BY column_name вернет только уникальные значения для указанного столбца. Это подходит для анализа данных, когда нужно найти все возможные варианты значений в столбце, но не нужно учитывать комбинации других столбцов.
Для удаления дубликатов в таблице на постоянной основе можно использовать запрос с DELETE, комбинируя его с подзапросами или оконными функциями. Один из способов – это определить строку с минимальным идентификатором для каждого дубликата и удалить все остальные. Пример запроса:
DELETE FROM table_name WHERE id NOT IN ( SELECT MIN(id) FROM table_name GROUP BY column_name );
В этом примере из таблицы удаляются все строки, кроме той, которая имеет минимальный идентификатор для каждой группы значений в column_name.
Для создания уникальных значений в таблице без удаления данных можно использовать ограничение UNIQUE при создании таблицы или добавлении столбца. Это предотвратит добавление дубликатов в будущем, обеспечивая уникальность значений в столбце. Пример создания столбца с уникальными значениями:
ALTER TABLE table_name ADD UNIQUE (column_name);
Если требуется получить уникальные значения по нескольким столбцам, можно также использовать комбинацию с GROUP BY. Такой подход поможет выбрать уникальные записи на основе сочетания нескольких полей.
Как оптимизировать запросы для поиска уникальных значений
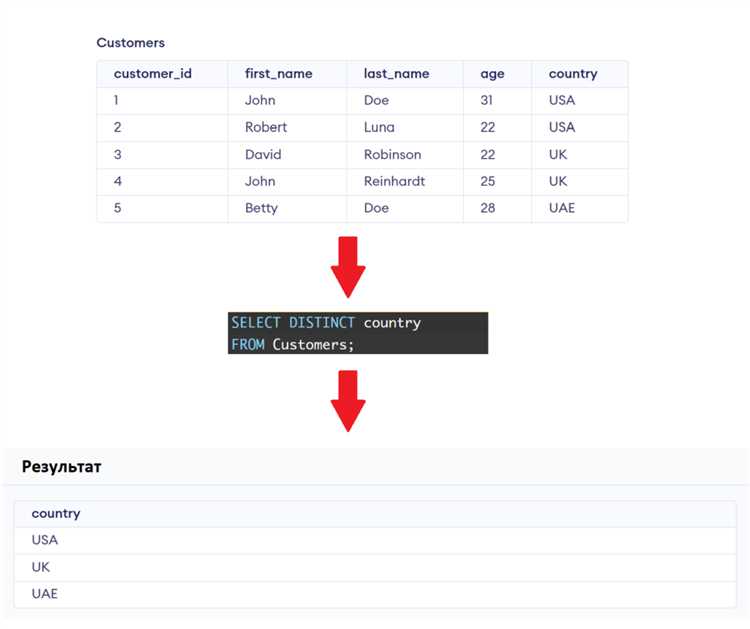
Для оптимизации запросов с операцией поиска уникальных значений в SQL важно учитывать несколько ключевых аспектов, которые могут значительно снизить нагрузку на сервер и ускорить выполнение запросов.
Первый шаг – использование индексов. Создание индекса на колонках, по которым осуществляется поиск уникальных значений, ускоряет выполнение запросов, особенно если таблица содержит большое количество данных. Индексы позволяют СУБД быстро находить нужные значения, минимизируя время поиска.
При использовании оператора DISTINCT следует помнить, что он требует сортировки данных, что может быть дорогостоящей операцией при больших объемах. Чтобы снизить нагрузку, используйте GROUP BY вместо DISTINCT, если это возможно. GROUP BY позволяет сгруппировать данные по уникальным значениям и, в некоторых случаях, выполняется быстрее, чем DISTINCT, поскольку не требует сортировки всех данных.
Вместо того чтобы искать уникальные значения в больших таблицах, можно использовать предварительную агрегацию данных. Создайте представление или временную таблицу с предварительно отсортированными и уникальными значениями. Это позволит уменьшить количество данных, обрабатываемых в основном запросе, и ускорит его выполнение.
Для улучшения производительности также важно правильно формировать запросы, исключая лишние соединения и подзапросы. Чаще всего операция поиска уникальных значений не требует сложных объединений таблиц, что позволяет снизить затраты на выполнение запроса.
Если данные содержат дубликаты в одном столбце, попробуйте сначала устранить их на уровне индексации, а не в самом запросе. Это можно сделать с помощью механизма уникальных индексов, что позволит базе данных автоматически исключать повторяющиеся записи без явного применения DISTINCT в запросах.
Еще один способ оптимизации – использование ограничений на уровне схемы данных. Например, если в таблице не должно быть дубликатов в определенном столбце, задайте ограничение UNIQUE на этот столбец. Это предотвратит необходимость в фильтрации дубликатов на уровне запросов.
Не забывайте о регулярной оптимизации базы данных, включая обновление статистики и дефрагментацию индексов. Это обеспечит базу данных актуальной информацией о распределении данных и поможет эффективно обрабатывать запросы, включая те, которые выполняются для поиска уникальных значений.
Решение проблем с производительностью при работе с уникальными значениями
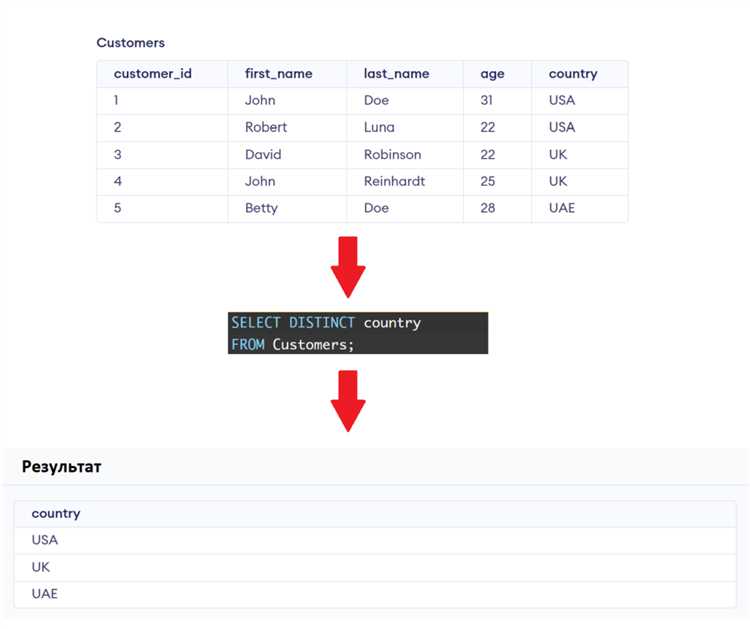
Работа с уникальными значениями в SQL может вызывать проблемы с производительностью, особенно при больших объемах данных. Чтобы избежать значительных замедлений, следует применять подходы, направленные на оптимизацию запросов и эффективное использование ресурсов базы данных.
- Использование индексов: Один из ключевых способов улучшить производительность при выборке уникальных значений – это создание индексов. Индекс на столбце, содержащем уникальные значения, значительно ускоряет выполнение запросов, таких как
SELECT DISTINCTилиGROUP BY. Однако важно следить за тем, чтобы индекс не был избыточным, так как это может замедлить операции вставки и обновления. - Минимизация использования
DISTINCT: ОперацияDISTINCTможет быть дорогой, особенно если применяется к большим таблицам. Рассмотрите возможность заменыDISTINCTна более эффективные методы, такие как использованиеGROUP BY, если это возможно, или предварительная фильтрация данных с помощью подзапросов или временных таблиц. - Использование агрегатных функций: Для извлечения уникальных значений можно использовать агрегатные функции, такие как
MINилиMAXв сочетании сGROUP BY, что часто работает быстрее, чемDISTINCT, особенно на индексированных столбцах. - Параллельная обработка: В случае работы с большими объемами данных рассмотрите возможность использования параллельной обработки запросов. Базы данных, такие как PostgreSQL и Oracle, поддерживают выполнение запросов в несколько потоков, что может значительно ускорить выборку уникальных значений на больших объемах.
- Фильтрация данных на уровне приложения: В некоторых случаях можно избежать излишних операций в SQL-запросах, перемещая фильтрацию уникальных значений на уровень приложения. Например, если работа с уникальными значениями нужна не для всего набора данных, а только для части, можно выполнить первичную фильтрацию на стороне приложения, чтобы передать в SQL только необходимую часть данных.
- Использование оконных функций: В некоторых ситуациях можно воспользоваться оконными функциями, например,
ROW_NUMBER(), чтобы выбрать уникальные строки, не используяDISTINCT. Оконные функции позволяют получить уникальные строки без необходимости сортировки всех данных, что ускоряет выполнение запроса. - Оптимизация структуры данных: Поддерживайте нормализованную структуру базы данных. Чрезмерная денормализация может привести к значительным избыточным данным, что замедляет поиск уникальных значений. Например, вместо хранения всех значений в одной таблице, разделите их по категориям, что позволит легче выделять уникальные записи.
- Периодическая очистка данных: Регулярная очистка и архивирование старых данных поможет сократить объем обрабатываемых записей. Меньший объем данных ускоряет запросы, включая выборку уникальных значений, и снижает нагрузку на систему.
Используя эти методы, можно эффективно работать с уникальными значениями, минимизируя проблемы с производительностью даже при значительных объемах данных.
Вопрос-ответ:
Как выбрать уникальные значения в SQL?
Для того чтобы выбрать уникальные значения в SQL, можно использовать оператор `DISTINCT`. Этот оператор позволяет получить только те строки, которые имеют уникальные значения в одном или нескольких столбцах. Например, запрос `SELECT DISTINCT column_name FROM table_name;` вернет все уникальные значения из столбца `column_name` таблицы `table_name`.
Какая разница между `DISTINCT` и `GROUP BY` для получения уникальных значений?
Оператор `DISTINCT` и `GROUP BY` оба позволяют получить уникальные значения, но используются в разных контекстах. `DISTINCT` применяется для выбора уникальных значений из одного или нескольких столбцов без агрегации данных. Например, запрос `SELECT DISTINCT column_name FROM table_name;` вернет уникальные значения. В то время как `GROUP BY` используется для группировки данных, обычно с агрегатными функциями, такими как `COUNT`, `SUM`, `AVG`, например: `SELECT column_name, COUNT(*) FROM table_name GROUP BY column_name;`.
Как выбрать уникальные значения, игнорируя `NULL` значения?
Если вам нужно выбрать уникальные значения, игнорируя `NULL`, можно использовать условие `WHERE column_name IS NOT NULL` перед использованием `DISTINCT`. Например, запрос: `SELECT DISTINCT column_name FROM table_name WHERE column_name IS NOT NULL;` вернет все уникальные значения из столбца `column_name`, исключая `NULL`.
Можно ли выбрать уникальные значения по нескольким столбцам одновременно?
Да, можно. Для этого в запросе с оператором `DISTINCT` указываются несколько столбцов. Например, запрос `SELECT DISTINCT column1, column2 FROM table_name;` вернет уникальные сочетания значений в столбцах `column1` и `column2` из таблицы `table_name`. Это означает, что уникальность будет проверяться по парам значений в этих столбцах, а не по отдельным столбцам.
Можно ли использовать `DISTINCT` с агрегатными функциями в одном запросе?
Оператор `DISTINCT` можно использовать в сочетании с агрегатными функциями, но есть нюансы. Например, запрос с `DISTINCT` и функцией `COUNT`: `SELECT COUNT(DISTINCT column_name) FROM table_name;` вернет количество уникальных значений в столбце `column_name`. Однако, важно помнить, что `DISTINCT` будет работать только с данными, которые проходят через агрегатную функцию, и не изменяет результаты самой функции.