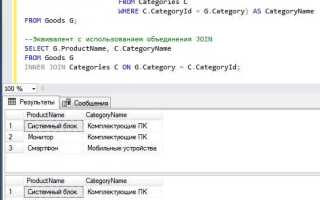
SQL используется для работы с реляционными базами данных. Чтобы извлечь данные, изменить структуру таблиц или добавить новые записи, необходимо составить точный SQL-запрос. Его синтаксис строго определён: любые ошибки приведут к сбою выполнения или некорректным результатам.
Для начала требуется подключение к СУБД – это может быть PostgreSQL, MySQL, SQLite или другая система. В большинстве случаев используется клиентская программа или встроенный терминал. Пример: в PostgreSQL достаточно команды psql -U имя_пользователя -d имя_базы для открытия сессии.
Базовый запрос на выборку выглядит так: SELECT столбцы FROM имя_таблицы;. Если нужно отфильтровать строки, добавляется WHERE. Например, SELECT * FROM users WHERE age > 30; вернёт всех пользователей старше 30 лет. Условие можно усложнить с помощью AND, OR, IN, BETWEEN и других операторов.
При выполнении запроса в интерактивной оболочке результат отображается сразу. В графических клиентах, таких как DBeaver или DataGrip, результаты показываются в отдельной вкладке. Важно проверять тип возвращаемых данных и количество строк, чтобы убедиться, что запрос работает корректно.
Чтобы запрос был читаемым и масштабируемым, рекомендуется использовать псевдонимы для таблиц, структурировать код по строкам и избегать вложенных подзапросов без необходимости. Также следует контролировать нагрузку: не использовать SELECT * в производственных системах, если не требуется извлекать все столбцы.
Выбор подходящего инструмента для выполнения SQL-запросов
Эффективная работа с SQL напрямую зависит от выбора подходящего инструмента. При выборе среды выполнения запросов необходимо учитывать поддержку нужного типа СУБД, доступные функции, удобство интерфейса и возможности расширения.
Для работы с популярными базами данных, такими как PostgreSQL, MySQL или Microsoft SQL Server, можно использовать как специализированные IDE, так и универсальные клиенты. Ниже представлены основные варианты:
| pgAdmin | Оптимальный выбор для PostgreSQL. Поддерживает визуальное проектирование баз данных, создание скриптов, просмотр статистики выполнения запросов. |
| MySQL Workbench | Рекомендуется для работы с MySQL и MariaDB. Предлагает визуальное моделирование схем, генерацию запросов и автоматизацию резервного копирования. |
| SQL Server Management Studio (SSMS) | Официальный инструмент для Microsoft SQL Server. Поддерживает управление экземплярами серверов, оптимизацию запросов, настройку безопасности. |
| DBeaver | Мультиформатный клиент с поддержкой множества СУБД. Подходит для одновременной работы с различными базами, имеет расширяемую архитектуру через плагины. |
| DataGrip | Профессиональное решение от JetBrains. Поддерживает интеллектуальную автоподстановку, рефакторинг SQL-кода и работу с версиями баз данных. |
Если требуется быстро выполнить простой запрос без сложной настройки среды, можно использовать встроенные консоли командной строки, такие как psql для PostgreSQL или mysql для MySQL. Они обеспечивают минимальное время запуска и высокую скорость работы.
Для облачных решений часто предпочтительнее использовать веб-интерфейсы, встроенные в платформы, например, Google Cloud Console или AWS Management Console, так как они не требуют установки дополнительного ПО и обеспечивают доступ из любой точки.
Выбор инструмента следует основывать на типе проекта: для сложных корпоративных систем рациональнее использовать профессиональные IDE с поддержкой версионирования и профилирования запросов, для разовых задач или обучения – легковесные клиенты или консольные утилиты.
Подключение к базе данных через SQL-клиент
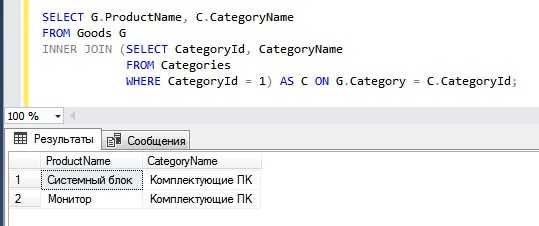
Для подключения к базе данных необходимо использовать SQL-клиент, поддерживающий нужный тип СУБД. Примеры: DBeaver, DataGrip, HeidiSQL, psql (для PostgreSQL), MySQL Shell. Установка клиента зависит от операционной системы, чаще всего доступны готовые установщики с официальных сайтов.
Перед подключением убедитесь, что:
- База данных запущена и доступна по сети
- Известны параметры подключения: адрес сервера, порт, имя пользователя, пароль, имя базы данных
- На клиентской машине открыт нужный порт (по умолчанию: 5432 для PostgreSQL, 3306 для MySQL)
Пример подключения в DBeaver:
- Создайте новое подключение через меню “Database” → “New Database Connection”
- Выберите тип СУБД
- Укажите host, порт, имя базы, пользователя и пароль
- Нажмите “Test Connection”, проверьте результат
- Если подключение успешно – сохраните параметры
При использовании консольного клиента psql:
psql -h 127.0.0.1 -p 5432 -U имя_пользователя имя_базыЕсли используется MySQL:
mysql -h 127.0.0.1 -P 3306 -u имя_пользователя -p имя_базыПри ошибке “Connection refused” проверьте, запущен ли сервер базы данных и разрешено ли подключение снаружи. В конфигурации PostgreSQL это файлы postgresql.conf и pg_hba.conf. В MySQL – my.cnf, параметр bind-address.
Рекомендуется использовать отдельного пользователя с минимальными правами для работы с конкретной базой.
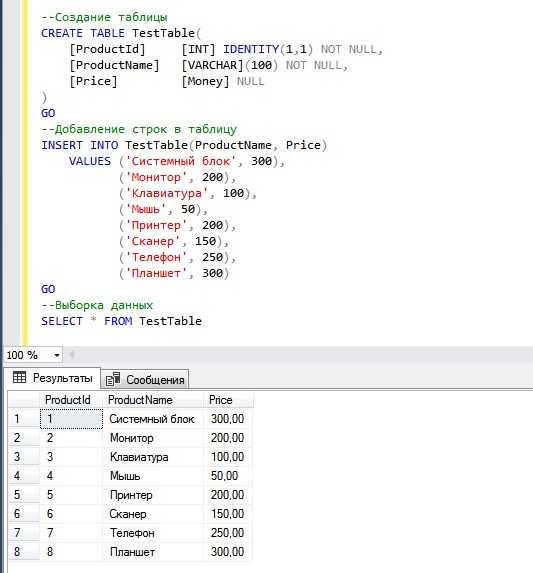
Создание простого SELECT-запроса для извлечения данных
SELECT-запрос позволяет выбрать нужные столбцы из одной или нескольких таблиц. Базовый синтаксис: SELECT имя_столбца FROM имя_таблицы;
Для выбора всех столбцов используется символ *: SELECT * FROM сотрудники; – вернёт все строки и все столбцы таблицы «сотрудники».
Чтобы ограничить выборку определёнными столбцами, перечисли их через запятую: SELECT имя, должность FROM сотрудники;
Фильтрация выполняется через WHERE. Пример: SELECT имя FROM сотрудники WHERE отдел = 'Продажи';
Сортировка добавляется с помощью ORDER BY: SELECT имя FROM сотрудники ORDER BY дата_приёма;
Для ограничения количества строк используется LIMIT: SELECT * FROM сотрудники LIMIT 10;
SQL чувствителен к именам таблиц и столбцов в зависимости от СУБД. В PostgreSQL имена без кавычек приводятся к нижнему регистру, в MySQL – не чувствительны к регистру, если не настроено иначе.
Пробелы и запятые имеют значение. Ошибка в синтаксисе, например, лишняя запятая в конце списка столбцов, приведёт к сбою выполнения запроса.
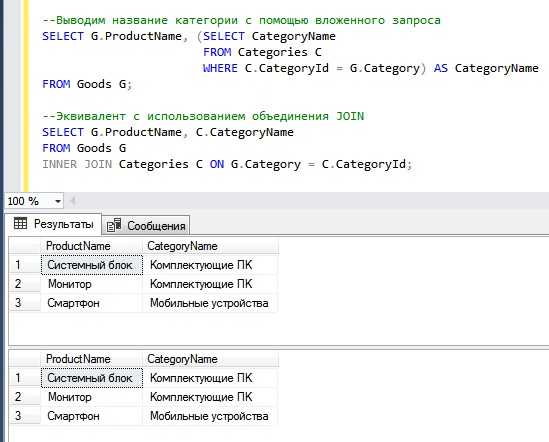
Фильтрация результатов с помощью WHERE
Оператор WHERE используется для отбора строк, которые соответствуют заданному условию. Он применяется после ключевого слова FROM и до ORDER BY или GROUP BY, если они присутствуют.
Пример: SELECT * FROM сотрудники WHERE отдел = ‘Маркетинг’; – выберет только тех сотрудников, у которых значение в столбце отдел равно Маркетинг.
Поддерживаются логические операторы: =, <>, >, >=, <, <=. Можно комбинировать условия с помощью AND и OR:
SELECT * FROM заказы WHERE сумма > 10000 AND статус = ‘Оплачен’;
Для поиска по шаблону используется LIKE. Символ % заменяет любое количество символов: WHERE имя LIKE ‘Ив%’ найдет всех, чье имя начинается на «Ив».
Если необходимо проверить наличие значения в списке, применяется IN: WHERE страна IN (‘Россия’, ‘Казахстан’).
Проверка на NULL выполняется через IS NULL или IS NOT NULL: WHERE дата_отгрузки IS NOT NULL.
Чтобы исключить повторяющийся код в подзапросах, используйте EXISTS: WHERE EXISTS (SELECT 1 FROM товары WHERE товары.id = заказы.товар_id).
Убедитесь, что фильтруемые столбцы проиндексированы, иначе производительность запроса может резко снизиться при больших объемах данных.
Сортировка и ограничение количества строк в выдаче
Для упорядочивания результатов используется оператор ORDER BY. По умолчанию сортировка выполняется по возрастанию (ASC). Для обратного порядка указывается DESC.
Пример: выбор товаров с сортировкой по цене от самой высокой к низкой:
SELECT name, price FROM products ORDER BY price DESC;
Сортировать можно по нескольким столбцам. Например, сначала по категории, затем по имени:
SELECT name, category FROM products ORDER BY category ASC, name ASC;
Чтобы ограничить количество строк, используется LIMIT. Этот оператор особенно полезен при работе с большими объемами данных или для реализации постраничной навигации.
Пример: вывести только первые 5 записей:
SELECT id, title FROM articles ORDER BY created_at DESC LIMIT 5;
Смещение задается с помощью OFFSET:
SELECT id, title FROM articles ORDER BY created_at DESC LIMIT 5 OFFSET 10;
В некоторых СУБД можно использовать короткую форму: LIMIT 10, 5 – это эквивалент LIMIT 5 OFFSET 10.
Комбинирование ORDER BY и LIMIT позволяет эффективно выбирать, например, последние события, самые дорогие товары или любые другие приоритетные записи.
Изменение данных с помощью INSERT, UPDATE и DELETE
SQL предоставляет три основных оператора для работы с данными в таблицах: INSERT, UPDATE и DELETE. Эти операторы позволяют добавлять, изменять и удалять записи в базе данных.
INSERT используется для добавления новых строк в таблицу. Основная структура запроса выглядит так:
INSERT INTO имя_таблицы (столбец1, столбец2, ...) VALUES (значение1, значение2, ...);
Важно указывать все столбцы, для которых должны быть заданы значения, если не предусмотрены значения по умолчанию или автоматическая генерация (например, для автоинкрементируемых полей). Если столбцы не указываются, то значения должны быть указаны в том же порядке, в каком они представлены в таблице.
UPDATE используется для изменения данных в существующих записях. Основная структура запроса выглядит так:
UPDATE имя_таблицы SET столбец1 = значение1, столбец2 = значение2 WHERE условие;
Обязательно используйте условие в WHERE, чтобы избежать изменения всех строк в таблице. Без условия можно обновить все записи, что, как правило, нежелательно.
DELETE удаляет данные из таблицы. Запрос на удаление имеет такую структуру:
DELETE FROM имя_таблицы WHERE условие;
Как и в случае с UPDATE, не забудьте указать условие для фильтрации записей. Если условие не указано, будет удалена вся таблица, что приведет к потере всех данных в ней.
Каждый из этих операторов выполняет изменения в данных, и правильное использование условий в запросах помогает избежать ошибок и нежелательных последствий.
Обработка ошибок при выполнении SQL-запросов
При выполнении SQL-запросов могут возникать различные ошибки, которые важно обрабатывать для корректной работы приложения и базы данных. Ошибки можно разделить на синтаксические, логические и ошибки выполнения.
Синтаксические ошибки возникают, когда SQL-запрос не соответствует грамматике SQL. Это могут быть опечатки в ключевых словах, неправильное использование скобок или запятых. Такие ошибки обычно легко выявляются с помощью систем управления базами данных (СУБД), которые возвращают сообщения об ошибках с указанием строки и типа ошибки. Для предотвращения таких ошибок важно тщательно проверять синтаксис запросов и использовать средства автозавершения, если они доступны в вашей среде разработки.
Логические ошибки проявляются, когда запрос синтаксически правильный, но возвращает неверные данные. Например, можно использовать неправильные операторы сравнения или пропустить важное условие в WHERE. Эти ошибки сложнее обнаружить, поскольку запрос может завершиться без явных ошибок, но результат не будет соответствовать ожиданиям. Рекомендуется использовать ограниченные выборки данных для тестирования запросов, чтобы убедиться в корректности логики.
Ошибки выполнения возникают при попытке выполнить запрос, который не может быть обработан сервером базы данных. Например, попытка доступа к несуществующей таблице или нарушение ограничения целостности данных (например, вставка данных, нарушающих уникальность ключа). Чтобы минимизировать такие ошибки, важно использовать проверки данных на уровне приложения перед отправкой запросов в базу данных. Также стоит настроить правильные индексы и ограничения на уровне базы данных, чтобы предотвратить попытки нарушить целостность данных.
Для обработки ошибок в SQL-запросах можно использовать транзакции. Это позволяет откатить все изменения, сделанные в рамках транзакции, если возникает ошибка. Транзакции обеспечивают атомарность операций, что позволяет избежать частичных изменений в базе данных, которые могут привести к неконсистентности данных.
Для отлова ошибок на уровне кода можно использовать механизмы обработки исключений, доступные в различных языках программирования, таких как try-catch в Java, Python или C#. В блоке catch можно обработать ошибку, записать её в журнал или предпринять другие меры, например, уведомить пользователя о проблеме.
Не стоит забывать и о логировании ошибок. Записывать все ошибки, возникающие при выполнении запросов, следует в отдельный журнал или лог-файл. Это поможет в дальнейшем анализировать причины ошибок и оптимизировать работу с базой данных.
Вопрос-ответ:
Что такое SQL-запрос и зачем он нужен?
SQL-запрос — это команда, используемая для взаимодействия с базой данных. Он позволяет извлекать, обновлять, удалять или добавлять данные. Например, с помощью SQL-запроса можно получить список всех пользователей из базы данных или обновить информацию о пользователе. Запросы могут быть простыми, такими как выборка данных, или сложными, включающими объединение нескольких таблиц.
Какие ошибки могут возникнуть при выполнении SQL-запросов?
Наиболее распространенные ошибки при выполнении SQL-запросов включают синтаксические ошибки (например, пропущенные запятые или кавычки), ошибки в именах таблиц или колонок (если указать неверное имя), а также ошибки в логике запросов (например, использование неверных условий в WHERE). Для того чтобы избежать ошибок, важно тщательно проверять структуру запроса и данные в базе перед его выполнением. Ошибки также могут возникать, если в запросе используются несуществующие данные или неправильные типы данных.