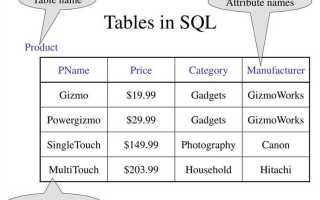
Для извлечения данных из таблицы в SQL используется оператор SELECT. Этот запрос позволяет выбрать строки и столбцы, которые соответствуют заданным условиям. Синтаксис команды прост, но для эффективной работы с большими объемами данных важно правильно настроить фильтры, сортировку и агрегирование.
Простейший SELECT запрос позволяет получить все данные из таблицы. Для этого достаточно указать имя таблицы после ключевого слова SELECT. Пример запроса:
SELECT * FROM employees;
Этот запрос вернёт все столбцы и строки из таблицы employees. Однако в реальной практике такие запросы часто неэффективны. Важно ограничить выборку только нужными данными, указав имена столбцов. Например, если нужно получить только имя и должность сотрудников:
SELECT name, position FROM employees;
Фильтрация данных в запросах осуществляется с помощью оператора WHERE. Например, чтобы вывести только тех сотрудников, чья должность – «менеджер», запрос будет выглядеть так:
SELECT name, position FROM employees WHERE position = ‘Manager’;
Для более сложных фильтров можно использовать логические операторы AND, OR и NOT, а также функции для работы с датами или строками. Например, чтобы выбрать сотрудников, работающих с 2020 года, запрос будет таким:
SELECT name, position FROM employees WHERE hire_date >= ‘2020-01-01’;
SELECT name, position FROM employees ORDER BY hire_date DESC;
Выборка данных с использованием оператора SELECT
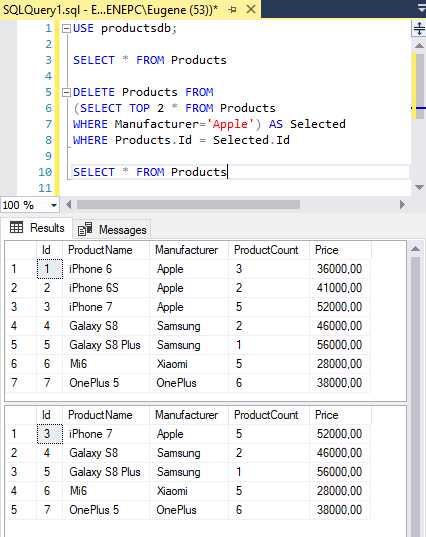
Оператор SELECT используется для извлечения данных из базы данных. Он позволяет гибко формировать запросы, указывая, какие поля и строки нужно получить. Для простого извлечения всех данных из таблицы достаточно использовать запрос:
SELECT * FROM имя_таблицы;Однако в большинстве случаев необходимо получить не все строки, а только определённые, соответствующие условиям. Для этого применяется ключевое слово WHERE, которое задаёт фильтр. Пример:
SELECT имя, возраст FROM пользователи WHERE возраст > 18;Кроме того, можно указать сортировку результатов с помощью ORDER BY. По умолчанию данные сортируются по возрастанию, но для сортировки в порядке убывания используется ключевое слово DESC:
SELECT имя, возраст FROM пользователи WHERE возраст > 18 ORDER BY возраст DESC;Если необходимо выбрать только уникальные значения в столбце, используется ключевое слово DISTINCT:
SELECT DISTINCT город FROM пользователи;Для выборки определённого количества строк применяется ключевое слово LIMIT (для MySQL) или TOP (для SQL Server). Пример для MySQL:
SELECT имя FROM пользователи LIMIT 10;Оператор SELECT также поддерживает агрегационные функции, такие как COUNT(), AVG(), SUM(), MIN() и MAX(). Эти функции позволяют выполнять вычисления на столбцах. Например, чтобы посчитать количество пользователей старше 18 лет, можно написать:
SELECT COUNT(*) FROM пользователи WHERE возраст > 18;Для группировки данных по определённому столбцу используется ключевое слово GROUP BY. Это позволяет, например, подсчитать средний возраст пользователей в каждом городе:
SELECT город, AVG(возраст) FROM пользователи GROUP BY город;Использование оператора SELECT с условиями, сортировкой и агрегацией позволяет гибко извлекать нужные данные и оптимизировать работу с базой данных.
Фильтрация данных с помощью WHERE
Оператор WHERE используется в SQL для фильтрации данных на основе определённых условий. Он ограничивает результат выборки, возвращая только те записи, которые удовлетворяют указанным критериям. Этот оператор может быть использован с любыми типами данных, такими как строки, числа или даты.
Простой пример: чтобы получить все записи, где возраст пользователя больше 30, запрос будет выглядеть так:
SELECT * FROM users WHERE age > 30;
Можно комбинировать несколько условий с помощью логических операторов AND, OR и NOT. Например, если нужно найти пользователей, чей возраст больше 30 и статус равен ‘активный’, запрос будет таким:
SELECT * FROM users WHERE age > 30 AND status = 'active';
Для фильтрации по строкам используются операторы сравнения, такие как =, <>, LIKE. Оператор LIKE позволяет искать данные по шаблону, что полезно при работе с текстовыми полями. Например, чтобы найти все имена, начинающиеся на букву «А»:
SELECT * FROM users WHERE name LIKE 'A%';
Если необходимо исключить некоторые записи, используется оператор NOT. Например, чтобы исключить пользователей с возрастом меньше 18 лет:
SELECT * FROM users WHERE NOT age < 18;
Для работы с диапазонами значений применяются операторы BETWEEN и IN. Оператор BETWEEN выбирает записи, которые находятся в указанном диапазоне. Например, запрос для выбора пользователей с возрастом от 18 до 30 лет:
SELECT * FROM users WHERE age BETWEEN 18 AND 30;
Оператор IN позволяет выбирать записи, где значение столбца совпадает с любым из нескольких заданных. Пример использования IN для фильтрации по статусу:
SELECT * FROM users WHERE status IN ('active', 'pending');
Фильтрация данных с помощью WHERE позволяет эффективно извлекать только нужные записи, что важно для оптимизации работы с большими объемами данных.
Сортировка результатов с ORDER BY
Команда ORDER BY в SQL используется для упорядочивания строк в результатах запроса по одному или нескольким столбцам. Сортировка может быть как по возрастанию (ASC), так и по убыванию (DESC). По умолчанию используется сортировка по возрастанию.
Пример сортировки по одному столбцу:
SELECT имя, возраст FROM пользователи ORDER BY возраст;
В этом примере результат будет отсортирован по возрасту в порядке возрастания. Для сортировки по убыванию можно добавить DESC:
SELECT имя, возраст FROM пользователи ORDER BY возраст DESC;
Можно сортировать по нескольким столбцам. В этом случае строки упорядочиваются сначала по первому столбцу, затем, если значения одинаковы, по второму и так далее:
SELECT имя, возраст, город FROM пользователи ORDER BY город ASC, возраст DESC;
Такой запрос сначала отсортирует пользователей по городу, а затем в пределах каждого города – по возрасту в порядке убывания.
При сортировке по числовым значениям или датам результат будет естественным для этих типов данных. При сортировке строк в SQL учитываются алфавитные значения, при этом большая буква будет идти перед маленькой.
Для работы с NULL-значениями используется правило: NULL всегда будет идти в конце при сортировке по возрастанию и в начале – по убыванию. Если нужно изменить поведение, можно воспользоваться конструкцией IS NULL в WHERE:
SELECT имя, возраст FROM пользователи WHERE возраст IS NULL ORDER BY имя;
Так можно выделить строки с пустыми значениями в отдельный блок при сортировке.
Агрегация данных с функциями SUM, COUNT и AVG
Агрегационные функции SQL позволяют обрабатывать данные в таблицах, выполняя операции, такие как суммирование, подсчёт записей и вычисление среднего значения. Рассмотрим основные из них: SUM, COUNT и AVG.
SUM – функция для вычисления суммы значений в указанном столбце. Она полезна при подсчёте общего объёма продаж, выручки или других количественных показателей.
- Пример: подсчёт общей суммы заказов по каждому клиенту:
SELECT customer_id, SUM(order_total) FROM orders GROUP BY customer_id;
COUNT используется для подсчёта количества строк, которые соответствуют условиям запроса. Эту функцию часто применяют для оценки количества заказов, товаров или пользователей.
- Пример: подсчёт количества заказов, сделанных каждым клиентом:
SELECT customer_id, COUNT(order_id) FROM orders GROUP BY customer_id;
AVG вычисляет среднее значение по указанному столбцу. Она полезна для получения среднего значения цен, затрат, количества товаров и других показателей.
- Пример: нахождение среднего значения стоимости заказов по каждому клиенту:
SELECT customer_id, AVG(order_total) FROM orders GROUP BY customer_id;
Важно помнить, что все агрегационные функции часто используются в сочетании с GROUP BY, чтобы агрегировать данные по определённым группам, например, по клиентам или товарам.
Также стоит учитывать, что если в столбце присутствуют NULL-значения, функции SUM и AVG их игнорируют, а COUNT учитывает все строки, включая те, где значения NULL.
Объединение таблиц с JOIN
Для объединения данных из нескольких таблиц в SQL используется оператор JOIN. Он позволяет извлечь информацию, которая присутствует в нескольких таблицах, ссылаясь на общие столбцы. JOIN бывает нескольких типов, каждый из которых имеет свои особенности.
INNER JOIN возвращает только те строки, которые присутствуют в обеих таблицах, удовлетворяя условиям соединения. Этот тип соединения эффективен, когда необходимо получить данные, которые есть в обеих таблицах. Пример использования:
SELECT employees.name, departments.name FROM employees INNER JOIN departments ON employees.department_id = departments.id;
LEFT JOIN (или LEFT OUTER JOIN) извлекает все строки из левой таблицы, а из правой – только те, которые соответствуют условию соединения. Если совпадений нет, результат из правой таблицы будет заполнен значениями NULL. Такой тип полезен, когда нужно сохранить все данные из левой таблицы, даже если в правой таблице нет соответствующих строк.
SELECT employees.name, departments.name FROM employees LEFT JOIN departments ON employees.department_id = departments.id;
RIGHT JOIN (или RIGHT OUTER JOIN) аналогичен LEFT JOIN, но сохраняет все строки из правой таблицы. Если нет соответствующих данных в левой таблице, результат будет заполнен значениями NULL.
SELECT employees.name, departments.name FROM employees RIGHT JOIN departments ON employees.department_id = departments.id;
FULL JOIN (или FULL OUTER JOIN) возвращает все строки из обеих таблиц, заполняя NULL в местах, где нет соответствующих данных. Этот тип соединения полезен, когда важно иметь полное представление о данных, даже если строки из одной из таблиц не имеют пар.
SELECT employees.name, departments.name FROM employees FULL JOIN departments ON employees.department_id = departments.id;
При использовании JOIN важно правильно индексировать столбцы, по которым осуществляется соединение. Это ускоряет выполнение запроса, особенно при работе с большими таблицами. Также стоит учитывать, что JOIN может увеличивать время выполнения запроса, если таблицы содержат много строк или сложные условия соединения.
Использование подзапросов для сложных выборок
Подзапросы в SQL позволяют выполнять сложные запросы, когда требуется получить данные, которые зависят от других значений в той же или другой таблице. Вложенные запросы обычно используются для фильтрации данных, расчётов или агрегирования на основе условий, которые не могут быть заданы напрямую в основном запросе.
Подзапросы могут быть расположены в различных частях основного запроса: в WHERE, FROM и SELECT. Каждый из этих вариантов имеет свои особенности использования.
Подзапросы в WHERE позволяют фильтровать данные на основе значений, вычисленных в другом запросе. Например, чтобы выбрать сотрудников, чья зарплата выше средней по департаменту, можно использовать следующий запрос:
SELECT employee_name FROM employees WHERE salary > (SELECT AVG(salary) FROM employees WHERE department_id = employees.department_id);
В данном примере подзапрос вычисляет среднюю зарплату для каждого департамента, и основной запрос выбирает сотрудников, чья зарплата выше этого значения.
Подзапросы в FROM позволяют обрабатывать результаты подзапроса как временную таблицу. Это полезно, если нужно выполнить агрегацию или объединение с результатами подзапроса. Например, можно получить список департаментов с их общей зарплатой:
SELECT department_id, total_salary FROM (SELECT department_id, SUM(salary) AS total_salary FROM employees GROUP BY department_id) AS dept_salaries WHERE total_salary > 50000;
Здесь подзапрос сначала агрегистрирует зарплаты по департаментам, а основной запрос фильтрует те, у которых суммарная зарплата больше 50 000.
Подзапросы в SELECT могут быть использованы для вычислений, которые нужно добавить к каждому строковому результату. Например, для того чтобы вывести сотрудников и вычислить их бонус как процент от средней зарплаты по департаменту, можно использовать:
SELECT employee_name, salary, (salary / (SELECT AVG(salary) FROM employees WHERE department_id = e.department_id)) * 100 AS bonus_percent FROM employees e;
Важно помнить, что подзапросы, особенно вложенные и использующие агрегированные данные, могут сильно повлиять на производительность запросов. Поэтому при работе с большими объемами данных рекомендуется использовать индексы и анализировать планы выполнения запросов, чтобы убедиться в их эффективности.