Определение количества записей в SQL запросе является одной из самых базовых, но важных задач при работе с базами данных. Знание того, как эффективно получить число строк, соответствующих определённым критериям, помогает не только анализировать данные, но и оптимизировать запросы, улучшая производительность базы данных. Это особенно важно при работе с большими объёмами информации, где малейшая ошибка или неоптимальный запрос могут существенно повлиять на скорость работы системы.
Для подсчёта числа строк используется агрегатная функция COUNT(). Она позволяет вычислить количество записей в выборке, удовлетворяющих указанным условиям. В простейшем случае можно использовать COUNT(*), чтобы посчитать все строки таблицы или результирующего набора данных. Однако более сложные запросы требуют уточнения условий, например, подсчёт уникальных значений или строк, удовлетворяющих определённым фильтрам.
COUNT() является универсальным инструментом, но важно учитывать, что его использование может повлиять на производительность, особенно в случае работы с большими таблицами или при сложных фильтрациях. Для оптимизации запросов стоит обращать внимание на индексы, структуру таблиц и правильно настроенные условия фильтрации.
Использование функции COUNT() для подсчёта всех записей
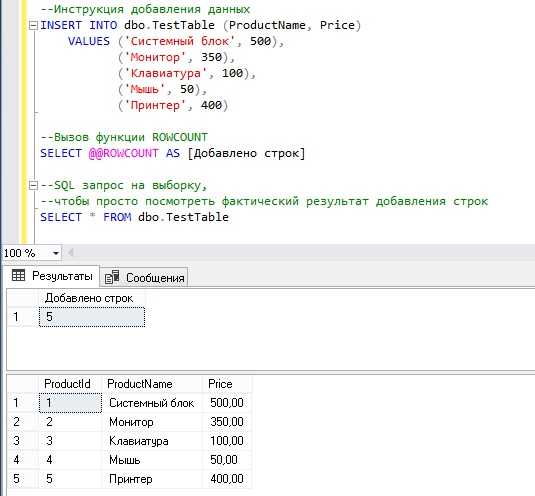
Основной синтаксис функции COUNT() выглядит следующим образом:
SELECT COUNT(*) FROM имя_таблицы;Этот запрос вернёт количество всех строк в указанной таблице, включая те, где присутствуют значения NULL.
Чтобы подсчитать количество записей, удовлетворяющих определённым условиям, можно использовать WHERE:
SELECT COUNT(*) FROM имя_таблицы WHERE условие;Пример: если нужно посчитать количество сотрудников в таблице «employees», которые работают в определённом отделе:
SELECT COUNT(*) FROM employees WHERE department = 'Sales';При использовании COUNT() важно помнить, что она игнорирует NULL значения, если в запросе указано поле. Например, при подсчёте количества уникальных значений в столбце, можно использовать следующую конструкцию:
SELECT COUNT(DISTINCT column_name) FROM имя_таблицы;Этот запрос подсчитает количество уникальных значений в столбце «column_name». Важно, что COUNT(DISTINCT) исключает повторяющиеся и NULL значения.
Ещё одно важное замечание – при работе с большими данными функция COUNT() может работать медленно, особенно если в таблице большое количество строк. Для ускорения выполнения запросов рекомендуется использовать индексы на столбцах, которые часто участвуют в фильтрации.
Как посчитать количество записей с определённым условием WHERE
Для подсчёта количества записей с определённым условием в SQL используется оператор COUNT, который применяется совместно с конструкцией WHERE. Это позволяет получить количество строк, соответствующих заданным фильтрам.
Пример базового запроса:
SELECT COUNT(*) FROM имя_таблицы WHERE условие;
Где:
COUNT(*)– функция, которая подсчитывает все строки, соответствующие условию;WHERE– фильтр, который ограничивает выборку только теми записями, которые соответствуют указанному условию;имя_таблицы– таблица, в которой выполняется поиск.
Условие может быть любым выражением, которое проверяется для каждой строки, например:
- Сравнение значений:
price > 1000; - Проверка на равенство:
status = 'active'; - Диапазон значений:
date BETWEEN '2025-01-01' AND '2025-12-31'; - Вхождение в список:
id IN (1, 2, 3).
Например, чтобы посчитать количество активных пользователей, запрос будет выглядеть так:
SELECT COUNT(*) FROM users WHERE status = 'active';
Если условие состоит из нескольких частей, можно использовать логические операторы AND и OR.
SELECT COUNT(*) FROM orders WHERE status = 'completed' AND order_date >= '2025-01-01';
Важный момент – использование COUNT(*) возвращает количество строк, включая строки с NULL значениями в полях. Если нужно посчитать только строки, где в каком-либо поле есть значение, используйте COUNT(поле), где поле – это имя конкретного столбца.
SELECT COUNT(status) FROM users WHERE registration_date >= '2025-01-01';
Этот запрос посчитает только те записи, где поле status не является NULL. Это важно при анализе данных, чтобы избежать неверного подсчёта.
Для более сложных условий можно комбинировать операторы и использовать регулярные выражения или функции, такие как LIKE для поиска по шаблону:
SELECT COUNT(*) FROM products WHERE product_name LIKE '%premium%';
Таким образом, подсчёт количества записей с условием WHERE позволяет точно и эффективно анализировать данные, фильтруя их по нужным критериям.
Использование DISTINCT для подсчёта уникальных значений
Для подсчёта уникальных значений в SQL запросах часто используется оператор DISTINCT. Он помогает исключить дубликаты и вернуть только уникальные строки, что особенно полезно при анализе данных или поиске уникальных значений в столбцах.
Применение DISTINCT может быть полезным в следующих случаях:
- Когда нужно посчитать количество уникальных значений в колонке.
- Когда необходимо извлечь только уникальные записи из набора данных.
Пример использования DISTINCT для подсчёта количества уникальных значений:
SELECT COUNT(DISTINCT column_name) FROM table_name;Этот запрос вернёт количество уникальных значений в столбце column_name таблицы table_name.
Важно помнить, что DISTINCT работает на уровне строк, то есть оно сравнивает все значения в строке для того, чтобы определить её уникальность. Для того чтобы посчитать уникальные значения в нескольких столбцах одновременно, нужно указать все эти столбцы в запросе:
SELECT COUNT(DISTINCT column1, column2) FROM table_name;Этот запрос вернёт количество уникальных сочетаний значений из столбцов column1 и column2.
Однако стоит помнить, что использование DISTINCT может иметь влияние на производительность, особенно при больших объёмах данных. Если данные сильно повторяются, оптимизация запросов может потребовать дополнительных индексов или переработки структуры таблиц.
Рекомендуется применять DISTINCT в случаях, когда важен именно подсчёт уникальных значений, а не всех записей подряд. Например, при анализе пользователей с уникальными IP-адресами или подсчёте различных категорий товаров, представленных в базе данных.
Как посчитать количество записей в группах с GROUP BY
Для подсчета количества записей в группах при использовании оператора GROUP BY в SQL применяется агрегатная функция COUNT(). Эта функция возвращает количество строк в каждой группе, определенной условием GROUP BY.
Пример простого запроса, который группирует данные по определенному полю и подсчитывает количество записей в каждой группе:
SELECT поле, COUNT(*) FROM таблица GROUP BY поле;
В этом запросе поле – это имя столбца, по которому производится группировка, а COUNT(*) возвращает количество строк в каждой группе. Обратите внимание, что * означает подсчет всех строк, включая те, где значения в других столбцах могут быть NULL.
Если нужно подсчитать количество записей по условиям, можно добавить фильтр с помощью HAVING. Этот оператор позволяет задать условия для агрегированных данных после выполнения группировки. Например:
SELECT поле, COUNT(*) FROM таблица GROUP BY поле HAVING COUNT(*) > 5;
Важно помнить, что GROUP BY всегда делит данные на подмножества, и для каждой группы будет рассчитано отдельное значение COUNT().
Кроме того, агрегатная функция COUNT() может быть использована с конкретным столбцом, что позволяет подсчитывать только непустые значения в этом столбце. Пример:
SELECT поле, COUNT(другой_столбец) FROM таблица GROUP BY поле;
В этом случае будут подсчитаны только строки, где значение в другом_столбце не является NULL.
Группировка с подсчетом записей используется в различных сценариях, например, для анализа данных о продажах, пользователях или других категориях, когда важно знать не только сами записи, но и их распределение по группам.
Использование COUNT с JOIN для подсчёта записей в связанных таблицах
Для подсчёта записей в связанных таблицах можно использовать оператор COUNT в сочетании с JOIN. Это позволяет вычислить количество строк, которые соответствуют определённым условиям в нескольких таблицах, при этом учитывая их связи. Часто такие запросы используются для получения статистики или аналитики по данным из разных сущностей.
Рассмотрим пример: у нас есть две таблицы – users и orders. Таблица users хранит информацию о пользователях, а таблица orders – об их заказах. Чтобы посчитать количество заказов для каждого пользователя, мы можем использовать JOIN для объединения данных и COUNT для подсчёта:
SELECT users.id, COUNT(orders.id) AS order_count FROM users LEFT JOIN orders ON users.id = orders.user_id GROUP BY users.id;
В этом запросе:
- Используется
LEFT JOIN, чтобы включить всех пользователей, даже если у них нет заказов. - Подсчитываются заказы каждого пользователя с помощью функции
COUNT. - Для группировки результатов применяется
GROUP BYпо идентификатору пользователя, чтобы подсчитать количество заказов для каждого из них.
Важно понимать, что при использовании LEFT JOIN количество заказов для пользователей, не имеющих заказов, будет равно 0. Если использовать INNER JOIN, то в результат попадут только те пользователи, у которых есть хотя бы один заказ.
В более сложных случаях, например, при подсчёте записей с несколькими связями, можно комбинировать несколько JOIN операторов. Например, если нужно посчитать количество заказов и количество продуктов в этих заказах, запрос будет выглядеть следующим образом:
SELECT users.id, COUNT(DISTINCT orders.id) AS order_count, COUNT(DISTINCT products.id) AS product_count FROM users LEFT JOIN orders ON users.id = orders.user_id LEFT JOIN order_items ON orders.id = order_items.order_id LEFT JOIN products ON order_items.product_id = products.id GROUP BY users.id;
Здесь добавлен дополнительный JOIN с таблицей order_items, которая связывает заказы с продуктами, и подсчитывается количество уникальных продуктов для каждого пользователя. Использование DISTINCT позволяет избежать дублирования данных в подсчёте.
Этот подход можно адаптировать для более сложных структур данных и различных типов связей между таблицами. Важно помнить, что при использовании JOIN в сочетании с COUNT всегда следует тщательно продумывать логику объединения данных, чтобы избежать неправильных результатов, например, из-за дублирования строк при множественных соответствиях в связанных таблицах.
Как учитывать NULL значения при подсчёте записей
В SQL при подсчёте записей важно понимать, как обрабатываются значения NULL. Обычно, когда используется функция COUNT(), она учитывает только те строки, где значения в выбранном столбце не равны NULL. Это необходимо учитывать, если в запросе встречаются пустые или неопределённые значения.
Если требуется посчитать все строки, независимо от того, содержат ли они NULL или нет, необходимо использовать COUNT(*) вместо COUNT(столбец). COUNT(*) подсчитывает все строки в таблице, включая те, где все или часть значений могут быть NULL.
Пример 1: Подсчёт всех строк в таблице:
SELECT COUNT(*) FROM таблица;
Пример 2: Подсчёт строк с ненулевым значением в конкретном столбце:
SELECT COUNT(столбец) FROM таблица;
В этом примере NULL значения будут игнорироваться, и подсчитаются только те строки, где столбец содержит данные.
Чтобы подсчитать количество строк с NULL значениями в определённом столбце, можно использовать условие с оператором IS NULL. Например:
SELECT COUNT(*) FROM таблица WHERE столбец IS NULL;
Это вернёт количество строк, где в указанном столбце значение NULL.
Таким образом, при работе с подсчётом записей необходимо чётко понимать разницу между COUNT(*) и COUNT(столбец), а также использовать дополнительные условия для работы с NULL значениями, если это требуется для задачи.
Оптимизация запроса на подсчёт записей с большими объёмами данных
Подсчёт количества записей в таблице с большими объёмами данных может существенно замедлить работу базы данных, особенно если запросы выполняются без должной оптимизации. Важно учитывать несколько аспектов для минимизации времени выполнения таких запросов.
1. Использование индексов. Для ускорения подсчёта рекомендуется создавать индексы на колонках, которые участвуют в фильтрации данных. Однако для простого подсчёта всех строк в таблице индекс может не дать значительного прироста скорости, так как в таких случаях запросы используют полное сканирование таблицы. Лучше использовать индексы на столбцах с частыми фильтрациями или объединениями.
2. Применение агрегатных функций с условиями. Использование функции COUNT() на больших объёмах данных может быть дорогим, если не использовать фильтрацию. Вместо подсчёта всех строк, полезно добавить WHERE-условия, которые ограничивают выборку. Если нужно посчитать только строки с определённым условием, например, активные записи, то это улучшит производительность.
3. Использование Materialized Views (материализованных представлений). В случае частых подсчётов, можно создать материализованное представление, которое будет хранить предварительный результат подсчёта. Это позволяет избежать повторных вычислений, ускоряя доступ к данным. Однако важно обновлять такие представления после изменений в основной таблице.
4. Параллельные запросы. Для баз данных, поддерживающих параллельное выполнение запросов (например, PostgreSQL, Oracle), можно использовать параллельные вычисления при подсчёте записей. Это ускоряет процесс за счёт использования нескольких ядер процессора для выполнения одной задачи.
5. Применение статистики. Во многих СУБД есть возможность использовать предварительно вычисленные статистики для оценки общего числа строк. Вместо выполнения полного подсчёта, СУБД может использовать информацию о распределении данных для быстрого получения результата, что значительно ускоряет запросы.
6. Разделение данных. В больших таблицах с историей данных может быть полезным разбиение таблицы на разделы по временным интервалам или другим ключевым признакам. Это позволяет уменьшить объём данных, с которым работает запрос, повышая производительность подсчёта.
7. Использование альтернативных подходов. Иногда эффективнее использовать не прямой подсчёт строк, а другие методы, например, создание кеша с результатами подсчётов или использование очередей для асинхронного выполнения подсчётов, чтобы избежать блокировки системы в пиковые моменты нагрузки.
Как посчитать записи без использования COUNT() через альтернативные методы

В SQL запросах, где необходимо посчитать количество записей, часто используется функция COUNT(). Однако, в некоторых случаях нужно обойтись без её применения, например, для оптимизации производительности или при ограничениях на использование определённых функций. Рассмотрим несколько альтернативных методов подсчёта записей.
1. Использование оконных функций
Один из способов подсчёта записей без COUNT() – использование оконных функций, таких как ROW_NUMBER(). Эта функция может быть использована для нумерации строк и, таким образом, для подсчёта их количества. Например, если мы хотим узнать количество строк в таблице без использования COUNT(), можно применить ROW_NUMBER() для создания уникальных номеров строк:
SELECT MAX(ROW_NUMBER() OVER ()) FROM таблица
Этот запрос возвращает наибольший номер строки, что соответствует количеству записей в таблице. Метод эффективен при работе с большими наборами данных.
2. Использование SUM() с условием
Вместо COUNT() можно использовать агрегацию через SUM(). Для этого нужно условно суммировать значения в столбце. Например, можно использовать выражение, которое будет считать строки по условию:
SELECT SUM(1) FROM таблица WHERE условие
Здесь SUM() будет суммировать единицы для каждой строки, удовлетворяющей условию. Это позволяет точно подсчитать количество строк, соответствующих заданным критериям, без использования COUNT().
3. Использование DISTINCT и GROUP BY
Если необходимо посчитать количество уникальных записей, можно использовать комбинацию DISTINCT и GROUP BY. Например, для подсчёта уникальных значений в столбце:
SELECT COUNT(DISTINCT столбец) FROM таблица
Хотя в этом примере используется COUNT(), аналогичную операцию можно выполнить через другие агрегационные функции, в зависимости от задачи. Также можно использовать GROUP BY, чтобы сгруппировать строки и подсчитать количество групп.
4. Использование внешних инструментов
Если расчёты должны быть выполнены на стороне клиента, можно использовать такие инструменты, как Python, для обработки результатов SQL-запросов. Например, запрос может возвращать все строки, а подсчёт количества записей осуществляется уже в коде. Этот метод полезен, когда необходимо выполнить дополнительные манипуляции с данными перед подсчётом.
5. Использование методов выборки с LIMIT и OFFSET
Для оценок можно использовать запросы с LIMIT и OFFSET. Выполнив запрос, который возвращает часть данных, можно использовать известные параметры для расчёта общей суммы, если это применимо в контексте задачи. Например:
SELECT * FROM таблица LIMIT 100 OFFSET 0
Данный запрос позволит получить первые 100 записей, после чего можно корректно масштабировать количество, если известно, сколько записей на каждой выборке.
Эти методы могут быть полезны в разных ситуациях, особенно когда COUNT() по каким-то причинам невозможно использовать или требуется повысить производительность запроса. Важно понимать, что каждый метод имеет свои ограничения и подходит для различных типов данных и задач.
Вопрос-ответ:
Как посчитать количество записей в SQL запросе?
Для того чтобы посчитать количество записей в SQL запросе, используется функция `COUNT()`. Эта функция позволяет подсчитать количество строк, которые удовлетворяют определённому условию. Например, запрос `SELECT COUNT(*) FROM employees;` вернёт количество всех записей в таблице `employees`. Если нужно посчитать записи с определённым условием, то можно использовать `WHERE`, как в примере: `SELECT COUNT(*) FROM employees WHERE age > 30;`. Такой запрос вернёт количество сотрудников, возраст которых больше 30 лет.
Что означает использование `COUNT(*)` в SQL запросе?
`COUNT(*)` в SQL возвращает количество строк в таблице или в результате запроса. Он не учитывает наличие значений в столбцах, а просто считает все строки. Например, если в таблице есть 100 строк, то запрос `SELECT COUNT(*) FROM table_name;` вернёт число 100, независимо от того, содержат ли эти строки значения в столбцах или нет. Это полезно, когда нужно подсчитать общее количество записей, независимо от их содержимого.
Как посчитать количество уникальных значений в столбце SQL запроса?
Для подсчёта уникальных значений в SQL запросе используется функция `COUNT(DISTINCT column_name)`. Эта функция позволяет подсчитать количество различных значений в указанном столбце. Например, запрос `SELECT COUNT(DISTINCT department) FROM employees;` вернёт количество уникальных отделов среди сотрудников. Таким образом, если в столбце будут повторяющиеся значения, они учитываться не будут, и результат отобразит только уникальные значения.
Можно ли подсчитать количество строк в таблице с условием в SQL запросе?
Да, в SQL можно подсчитать количество строк с условием, для этого используется функция `COUNT()` с оператором `WHERE`. Например, запрос `SELECT COUNT(*) FROM employees WHERE department = ‘Sales’;` вернёт количество сотрудников, работающих в отделе продаж. Условие в `WHERE` позволяет фильтровать данные и подсчитывать только те строки, которые соответствуют заданным критериям.