Когда задача требует извлечения нескольких максимальных значений из таблицы SQL, важно учитывать подход, который будет одновременно эффективным и точным. В SQL существует несколько методов для решения этой задачи, каждый из которых имеет свои особенности в зависимости от структуры данных и специфики запроса.
Первый способ – использование подзапросов с ключевым словом IN. Этот подход позволяет легко извлечь несколько строк, соответствующих максимальным значениям. Например, если вам нужно получить несколько максимальных зарплат сотрудников, можно выполнить запрос с использованием подзапроса, чтобы найти все строки с зарплатами, равными максимальной или ниже второй по величине.
Однако, этот метод может стать неэффективным для больших таблиц, так как каждый раз выполняется подзапрос для нахождения максимальных значений. В таких случаях полезно будет рассмотреть альтернативы, такие как использование оконных функций.
Оконные функции в SQL предлагают более гибкий и производительный способ получения нескольких максимальных значений. Использование ROW_NUMBER(), RANK() или DENSE_RANK() позволяет не только находить максимальные значения, но и учитывать их позиции относительно других строк. Например, DENSE_RANK() вернёт одинаковый ранг для одинаковых значений, что идеально подходит для случаев, когда несколько строк имеют одно и то же максимальное значение.
В зависимости от задачи и объема данных, выбор между подзапросами и оконными функциями будет определяться требуемой производительностью и сложностью запросов. Оконные функции являются более предпочтительным вариантом для работы с большими наборами данных, так как они позволяют избежать повторного выполнения подзапросов и значительно ускоряют выполнение.
Использование подзапроса для нахождения нескольких максимальных значений
Подзапросы позволяют эффективно находить несколько максимальных значений в SQL. Этот подход используется для того, чтобы извлечь строки, значения которых равны максимальному или близкому к нему. Подход состоит в применении подзапроса в разделе WHERE или в комбинации с агрегатными функциями.
Простой пример – нахождение всех сотрудников, чьи зарплаты равны максимальной среди всех записей. Для этого можно использовать подзапрос, который возвращает максимальное значение зарплаты из таблицы сотрудников. Затем в основном запросе мы выбираем все строки, где зарплата равна этому максимальному значению.
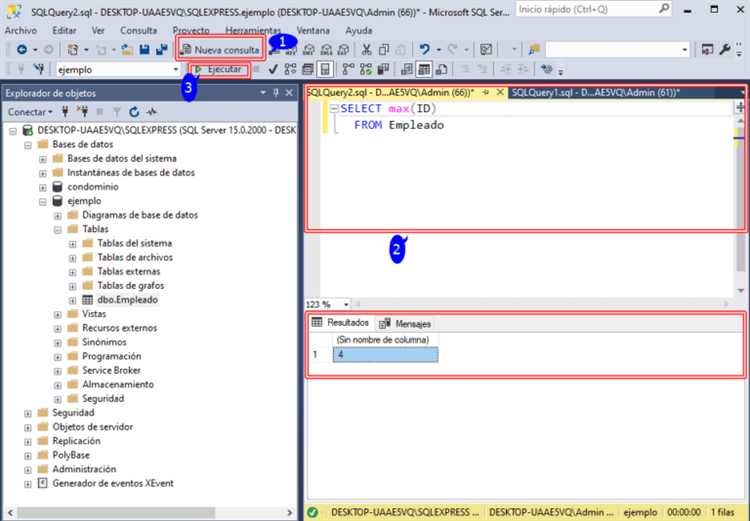
SELECT employee_id, name, salary FROM employees WHERE salary = (SELECT MAX(salary) FROM employees);
Если нужно найти несколько максимальных значений, например, 3 самые высокие зарплаты, подзапрос можно модифицировать. Вместо того чтобы просто искать максимальную зарплату, можно использовать конструкцию IN в подзапросе, чтобы вернуть несколько значений:
SELECT employee_id, name, salary FROM employees WHERE salary IN ( SELECT salary FROM employees ORDER BY salary DESC LIMIT 3 );
Этот запрос сначала извлекает три наибольшие зарплаты из таблицы сотрудников, а затем возвращает все строки, где зарплата входит в этот список. Такой метод эффективен, когда нужно выбрать несколько максимальных значений.
Подобный подход позволяет гибко настраивать количество максимальных значений, используя LIMIT и ORDER BY. Однако стоит помнить, что использование подзапросов может снизить производительность при больших объемах данных, поэтому важно учитывать оптимизацию запросов и, если возможно, использовать индексы по соответствующим столбцам.
Применение функции RANK() для выделения топ-N значений
Функция RANK() в SQL используется для присвоения рангов строкам в результате запроса на основе определённого порядка сортировки. Это мощный инструмент, который позволяет выделять топ-N значений, сортируя данные по определённым критериям. В отличие от других функций ранжирования, таких как DENSE_RANK() или ROW_NUMBER(), функция RANK() оставляет пропуски в номерах рангов в случае одинаковых значений, что важно учитывать при анализе данных.
Для того чтобы извлечь топ-N значений с использованием RANK(), необходимо сначала правильно сформировать запрос, включающий сортировку по нужному столбцу. Например, чтобы получить топ-3 зарплаты сотрудников, можно использовать следующий запрос:
SELECT employee_id, salary, RANK() OVER (ORDER BY salary DESC) AS rank FROM employees WHERE rank <= 3;
Здесь RANK() OVER (ORDER BY salary DESC) присваивает ранг каждому сотруднику, начиная с самого высокого значения зарплаты. Однако при одинаковых зарплатах сотрудники будут иметь одинаковый ранг, и следующее значение будет пропущено. Это важно, если необходимо учесть не только топ-N значений, но и пропуски между ними.
Если необходимо выбрать топ-N значений без пропусков в номерах рангов, стоит использовать функцию ROW_NUMBER(), которая будет присваивать уникальные ранги, не оставляя промежутков. Однако для задач, где важен порядок с пропусками, RANK() является оптимальным решением.
Также стоит учитывать, что в запросах с RANK() можно использовать различные критерии сортировки. Например, для анализа продаж в нескольких регионах можно присваивать ранги по объему продаж и в каждом регионе выделять топ-N продавцов. В таких случаях нужно указать параметр PARTITION BY, чтобы разделить данные на группы по регионам:
SELECT region, salesperson_id, sales_amount, RANK() OVER (PARTITION BY region ORDER BY sales_amount DESC) AS rank FROM sales WHERE rank <= 3;
Этот запрос выделит топ-3 продавцов в каждом регионе, учитывая особенности данных в разных частях компании.
При работе с RANK() важно помнить, что она будет полезна в тех случаях, когда важно сохранить все строки с одинаковыми значениями в одном ранге, при этом не нарушая логическую последовательность рангов.
Использование LIMIT и OFFSET для выбора нескольких максимальных значений
Для получения нескольких максимальных значений с использованием SQL можно применить операторы LIMIT и OFFSET. Эти операторы позволяют гибко выбирать строки из набора данных, минимизируя необходимость в сложных подзапросах и упрощая запросы к базе данных.
Оператор LIMIT ограничивает количество строк, которые возвращаются запросом, а OFFSET задаёт смещение от начала набора. Это позволяет получить «страничное» извлечение данных и использовать их для выборки нескольких максимальных значений без необходимости в сложных вычислениях или оконных функциях.
Пример базового запроса для получения первых 5 максимальных значений в таблице:
SELECT * FROM таблица ORDER BY значение DESC LIMIT 5;
Однако, для выборки нескольких "следующих" максимальных значений можно использовать OFFSET. Например, для получения значений с 6 по 10, запрос будет следующим:
SELECT * FROM таблица ORDER BY значение DESC LIMIT 5 OFFSET 5;
Важно отметить, что использование OFFSET может снизить производительность при больших наборах данных, так как база данных вынуждена пропускать строки до заданного смещения. В таких случаях стоит рассмотреть альтернативы, такие как использование оконных функций или временных таблиц.
Как извлечь несколько максимальных значений с помощью оконных функций
Оконные функции в SQL позволяют анализировать набор данных, не изменяя его структуры. Чтобы извлечь несколько максимальных значений с помощью оконных функций, используется комбинация функций, таких как ROW_NUMBER(), RANK() или DENSE_RANK(). Эти функции позволяют отсортировать строки внутри определённого окна и выбрать только нужные записи.
Пример использования оконных функций для получения нескольких максимальных значений:
ROW_NUMBER()– нумерует строки в окне, присваивая каждой строке уникальный номер. Для извлечения первых N значений можно ограничить запрос значением N.RANK()– присваивает ранг строкам, но в случае одинаковых значений возвращает одинаковые ранги. Позволяет извлечь несколько строк с одинаковыми значениями.DENSE_RANK()– аналогичнаRANK(), но не оставляет пропусков в номерах рангов.
Рассмотрим пример на практике. Допустим, у нас есть таблица sales с колонками id, employee_id, sales_amount. Нам нужно выбрать 3 наибольших значения по sales_amount.
SELECT id, employee_id, sales_amount, RANK() OVER (ORDER BY sales_amount DESC) AS rank FROM sales WHERE RANK() OVER (ORDER BY sales_amount DESC) <= 3;
Здесь функция RANK() сортирует данные по убыванию sales_amount и присваивает ранг каждой строке. После этого можно ограничить выборку до строк с рангом, не превышающим 3.
Если нужно извлечь топ N значений с учётом одинаковых результатов, то лучше использовать DENSE_RANK(), так как она не оставляет пропусков в номерах, если несколько строк имеют одинаковое значение.
SELECT id, employee_id, sales_amount, DENSE_RANK() OVER (ORDER BY sales_amount DESC) AS rank FROM sales WHERE DENSE_RANK() OVER (ORDER BY sales_amount DESC) <= 3;
В отличие от RANK(), если две строки имеют одинаковое значение, то обе получат одинаковый ранг, и следующие строки будут иметь ранг, который не пропускает числа.
Оконные функции дают гибкость в извлечении данных, так как позволяют работать с сортировкой и группировкой, не изменяя структуру результирующего набора. Это делает их полезным инструментом для извлечения нескольких максимальных значений, сохраняя при этом возможность учитывать одинаковые показатели и работать с большими объемами данных.
Получение максимальных значений с учётом связей между таблицами
При работе с базами данных часто возникает задача извлечь максимальные значения с учётом связей между таблицами. Для этого используются соединения (JOIN), которые позволяют извлечь данные из нескольких таблиц, обеспечивая контекст для поиска максимальных значений в связанных записях.
Один из самых распространённых случаев – нахождение максимального значения в одной таблице при учёте информации из другой. Для этого можно использовать оператор JOIN с агрегатной функцией MAX(). Пример запроса, где требуется найти максимальный доход для каждого клиента с учётом их заказов:
SELECT c.client_id, MAX(o.amount) AS max_order_amount FROM clients c JOIN orders o ON c.client_id = o.client_id GROUP BY c.client_id;
В данном запросе происходит соединение таблицы "clients" с таблицей "orders" по полю client_id. Для каждого клиента вычисляется максимальная сумма его заказа. Такой подход позволяет получить максимальные значения в контексте каждого клиента, а не просто для всей таблицы.
Если задача заключается в нахождении максимального значения, при этом необходимо учитывать дополнительное условие, например, активность клиента в определённый период, можно использовать WHERE или фильтры в JOIN. Пример с дополнительным фильтром по дате:
SELECT c.client_id, MAX(o.amount) AS max_order_amount FROM clients c JOIN orders o ON c.client_id = o.client_id WHERE o.order_date >= '2025-01-01' GROUP BY c.client_id;
Если необходимо не только получить максимальные значения, но и извлечь другие поля из связанной таблицы, можно воспользоваться подзапросами. Пример, когда для каждого клиента нужно найти максимальную сумму заказа и дату этого заказа:
SELECT c.client_id, o.amount, o.order_date FROM orders o WHERE o.amount = (SELECT MAX(amount) FROM orders WHERE client_id = o.client_id);
Этот запрос возвращает максимальный заказ каждого клиента с учётом даты заказа. Он работает через подзапрос, который для каждого клиента находит максимальное значение в таблице заказов.
Для получения нескольких максимальных значений можно использовать оконные функции. В этом случае не требуется группировка, и можно работать с данными более гибко. Пример использования оконной функции ROW_NUMBER() для поиска максимальных значений по каждому клиенту:
WITH ranked_orders AS ( SELECT c.client_id, o.amount, o.order_date, ROW_NUMBER() OVER (PARTITION BY c.client_id ORDER BY o.amount DESC) AS rn FROM clients c JOIN orders o ON c.client_id = o.client_id ) SELECT client_id, amount, order_date FROM ranked_orders WHERE rn = 1;
Здесь используется оконная функция ROW_NUMBER(), которая нумерует заказы каждого клиента в порядке убывания суммы. Запрос извлекает только первый (максимальный) заказ для каждого клиента.
Таким образом, для извлечения максимальных значений с учётом связей между таблицами важно правильно выбрать тип соединения, использовать агрегатные функции или оконные функции в зависимости от задачи, а также учитывать специфические условия, например, фильтрацию по дате или статусу записи.
Особенности сортировки при получении нескольких максимальных значений
Когда требуется извлечь несколько максимальных значений из таблицы, важно учитывать, как именно происходит сортировка данных. Обычный запрос с сортировкой по убыванию может не всегда дать правильный результат, особенно в случае, если несколько записей имеют одинаковые максимальные значения.
Если данные, которые вы хотите получить, содержат повторяющиеся максимумы, стандартная сортировка не всегда выделяет нужное количество строк. В таких случаях важно использовать подходы, которые гарантируют правильную выборку, например, через оконные функции или дополнительные условия в запросе.
Один из методов, который позволяет работать с такими ситуациями, – использование оконных функций с функцией RANK() или DENSE_RANK(). Эти функции присваивают ранги строкам, которые имеют одинаковое значение, что позволяет точнее определить, сколько строк с максимальными значениями вам нужно выбрать.
Пример запроса с оконной функцией для получения нескольких максимальных значений:
SELECT column_name, RANK() OVER (ORDER BY column_name DESC) AS rank FROM table_name WHERE rank <= 5;
Этот запрос извлечет 5 строк с максимальными значениями, при этом строки с одинаковыми значениями будут иметь одинаковый ранг.
Если ваша задача состоит в том, чтобы извлечь строго определённое количество записей с максимальными значениями (например, 5 строк с максимальными, без учета повторений), можно использовать функцию DENSE_RANK(), которая будет пропускать ранги между одинаковыми значениями.
Еще один вариант – использование подзапросов с агрегатными функциями. Например, можно сначала получить максимальное значение, а затем выбрать все строки с этим значением, используя конструкцию IN или JOIN. Однако такой подход может быть менее эффективным по сравнению с оконными функциями, особенно при работе с большими объемами данных.
При проектировании таких запросов важно учитывать индексирование по столбцам, которые участвуют в сортировке. Индексы значительно повышают производительность, снижая время выполнения запроса. При этом индексирование по нескольким столбцам может дать лучшие результаты при более сложных фильтрах и сортировках.
Не стоит забывать и о необходимости тестирования таких запросов на реальных данных для того, чтобы убедиться в их эффективности, особенно если работа ведется с большими объемами информации.
Оптимизация запросов для поиска нескольких максимальных значений
Поиск нескольких максимальных значений в SQL может быть ресурсоемким процессом, особенно при работе с большими объемами данных. Для эффективной оптимизации запросов важно учитывать структуру данных, выбор индексов и способы фильтрации результатов.
Основной проблемой является необходимость извлечь несколько максимальных значений с минимальными затратами ресурсов. Использование стандартных методов, таких как подзапросы или сортировка с ограничением, может привести к значительному увеличению времени выполнения. Рассмотрим несколько подходов к оптимизации.
- Использование оконных функций: Оконные функции, такие как
ROW_NUMBER(),RANK()илиDENSE_RANK(), позволяют получить несколько максимальных значений, не сортируя всю таблицу. Например, можно назначить ранги строкам на основе их значений и затем выбрать только те строки, которые соответствуют максимальным рангам.
Пример запроса с RANK():
SELECT column_name, RANK() OVER (ORDER BY column_name DESC) AS rank FROM table_name WHERE rank <= N;
- Использование
JOINс подзапросами: Для небольших наборов данных, где подзапросы не оказывают значительного влияния на производительность, можно использоватьJOINдля выборки строк с максимальными значениями. Этот метод особенно полезен, если необходимо получить значения из нескольких связанных таблиц.
Пример запроса с JOIN:
SELECT t1.* FROM table_name t1 JOIN ( SELECT MAX(column_name) AS max_value FROM table_name GROUP BY other_column ) t2 ON t1.column_name = t2.max_value;
- Использование индексов: Индексы могут значительно ускорить выполнение запросов, особенно при поиске максимальных значений в больших таблицах. Создание индекса на колонке, по которой выполняется поиск максимума, или на комбинации колонок, может значительно снизить время выполнения запроса.
Важно учитывать, что индексы на колонках с высокой кардинальностью (большое количество уникальных значений) будут наиболее эффективны при поиске максимальных значений.
Пример запроса с LIMIT:
SELECT column_name FROM table_name ORDER BY column_name DESC LIMIT N;
- Использование временных таблиц или CTE (Common Table Expressions): Для сложных запросов, которые включают несколько этапов обработки данных, полезно использовать временные таблицы или CTE. Это позволяет разделить запрос на несколько шагов, улучшая его читаемость и производительность за счет уменьшения объема данных на каждом этапе.
Пример запроса с CTE:
WITH RankedData AS ( SELECT column_name, RANK() OVER (ORDER BY column_name DESC) AS rank FROM table_name ) SELECT column_name FROM RankedData WHERE rank <= N;
Для достижения наилучших результатов важно учитывать тип базы данных, поскольку различные СУБД имеют свои особенности реализации оптимизаций. Например, в PostgreSQL использование индексов может быть менее эффективным, чем в MySQL, из-за различий в планах выполнения запросов. Регулярное анализирование и оптимизация запросов с помощью инструментов профилирования поможет найти узкие места в процессе выполнения.
Вопрос-ответ:
Как получить несколько максимальных значений в SQL?
Для получения нескольких максимальных значений в SQL можно использовать подзапрос с конструкцией `LIMIT` или `ROW_NUMBER()`. Один из распространённых методов — это использование подзапроса, который находит максимальное значение, а затем выбирает все строки, равные этому значению.
Можно ли в SQL выбрать несколько строк с одинаковыми максимальными значениями?
Да, для этого можно использовать запрос с подзапросом или оконные функции. Один из вариантов — использовать `ROW_NUMBER()` или `RANK()`. Например, запрос с использованием `RANK()` поможет вернуть все строки, которые имеют одинаковое максимальное значение, без удаления дубликатов.
Какие SQL-функции подходят для поиска нескольких максимальных значений?
Для этой задачи можно использовать функции окон, такие как `ROW_NUMBER()`, `RANK()` или `DENSE_RANK()`. Эти функции позволяют присваивать порядковые номера строкам на основе их значений в определённом порядке. С помощью этих функций можно легко получить несколько строк с одинаковыми максимальными значениями.
Как найти несколько строк с одинаковыми максимальными значениями в конкретном столбце?
Один из способов решения задачи — это использование оконных функций. Например, можно использовать `RANK()` или `DENSE_RANK()`. В запросе будет выбрано максимальное значение, и все строки, которые имеют это значение, будут отображены. Вот пример запроса: `SELECT * FROM table WHERE value = (SELECT MAX(value) FROM table)`.
Что делать, если значения в столбце могут быть одинаковыми, и нужно выбрать все строки с максимальными значениями?
Если значения в столбце могут быть одинаковыми и требуется выбрать все строки с максимальными значениями, можно использовать подзапрос. Например, запрос с подзапросом на `MAX()` позволяет получить все строки с максимальными значениями в нужном столбце. Пример: `SELECT * FROM table WHERE column = (SELECT MAX(column) FROM table)`. Этот запрос вернёт все строки с одинаковым максимальным значением.