При работе с большими объемами данных в SQL часто возникает необходимость найти и вывести совпадающие значения между разными таблицами или столбцами. В таких случаях важно выбрать правильный подход и использовать оптимальные операторы, чтобы избежать излишней нагрузки на базу данных. Это не только ускоряет выполнение запросов, но и повышает точность анализа данных.
Одним из основных методов для поиска совпадений является использование оператора JOIN. С помощью INNER JOIN можно получить только те записи, которые существуют в обеих таблицах, что идеально подходит для задач поиска совпадающих значений. При этом стоит помнить, что неправильное использование этого оператора может привести к дублированию данных, что важно учитывать при формулировке запросов.
Кроме того, для поиска дублирующихся значений внутри одной таблицы эффективным будет использование GROUP BY вместе с агрегатными функциями, такими как COUNT. Этот подход позволяет легко выявить значения, которые повторяются более одного раза. Важно тщательно продумывать критерии группировки, чтобы избежать лишних повторений и исключить ненужные записи.
Если нужно найти значения, которые не совпадают между двумя таблицами, можно воспользоваться LEFT JOIN и RIGHT JOIN, или даже использовать EXCEPT для фильтрации данных. Каждый из этих методов имеет свои особенности, и выбор подходящего зависит от структуры данных и цели запроса.
Использование оператора JOIN для нахождения совпадений
Оператор JOIN в SQL позволяет объединять данные из двух или более таблиц на основе логического условия. Для нахождения совпадений между значениями разных таблиц часто используется INNER JOIN, который возвращает только те строки, где есть соответствующие записи в обеих таблицах. Применяя этот оператор, можно легко выявить совпадающие значения по определённому полю.
Пример использования INNER JOIN для нахождения совпадений: допустим, у нас есть таблицы employees и departments, и нужно найти сотрудников, работающих в определённом отделе. Запрос будет выглядеть так:
SELECT employees.name, employees.department_id, departments.name FROM employees INNER JOIN departments ON employees.department_id = departments.id;
Этот запрос вернёт только тех сотрудников, которые имеют совпадение в поле department_id с полем id из таблицы departments.
Для более сложных ситуаций можно использовать несколько JOIN, чтобы находить совпадения сразу в нескольких таблицах. Например, если требуется узнать информацию о проектах, над которыми работают сотрудники, запрос может быть таким:
SELECT employees.name, projects.title FROM employees INNER JOIN project_assignments ON employees.id = project_assignments.employee_id INNER JOIN projects ON project_assignments.project_id = projects.id;
Кроме того, можно использовать LEFT JOIN, если нужно получить все строки из одной таблицы и только те строки из второй таблицы, которые имеют совпадения. Это полезно, если в одной из таблиц могут быть пустые значения, но нужно всё равно отобразить все записи из основной таблицы.
Применение оператора JOIN позволяет эффективно работать с большими объёмами данных, минимизируя количество запросов и повышая производительность системы. Важно правильно выбирать тип объединения в зависимости от того, какие результаты ожидаются: полный список всех данных, только совпадающие строки или комбинация из них.
Применение оператора IN для поиска повторяющихся значений
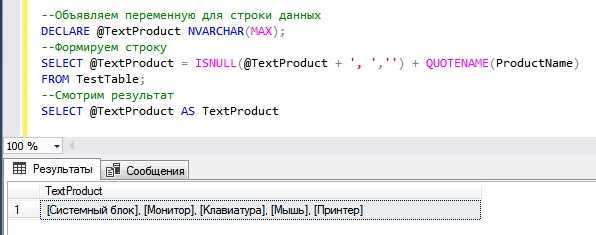
Оператор IN в SQL позволяет искать совпадения значений в указанном списке. Для поиска повторяющихся значений в одной таблице, IN может быть эффективным инструментом. Он позволяет задать несколько значений и проверить, содержатся ли они в одном столбце или в подзапросе.
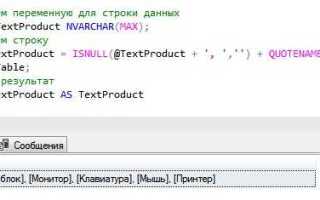
Для поиска повторений в одном поле можно использовать запрос, который проверяет, встречается ли каждое значение из набора несколько раз. Например, для поиска повторяющихся значений в столбце email таблицы users, запрос может выглядеть следующим образом:
SELECT email
FROM users
GROUP BY email
HAVING COUNT(email) > 1;Однако, если вам нужно найти совпадения значений между двумя или несколькими столбцами, оператор IN будет полезен. Например, чтобы найти пользователей, чьи email присутствуют в другом списке или таблице, используйте запрос с IN:
SELECT email
FROM users
WHERE email IN (SELECT email FROM subscriptions);Этот запрос вернёт все записи из таблицы users, чьи email находятся в списке, полученном из подзапроса таблицы subscriptions. Таким образом, оператор IN позволяет эффективно искать совпадения между двумя наборами данных.
Когда нужно вывести только те значения, которые повторяются несколько раз в одном столбце, можно использовать конструкцию с подзапросом в сочетании с IN:
SELECT email
FROM users
WHERE email IN (SELECT email FROM users GROUP BY email HAVING COUNT(email) > 1);Этот запрос находит все email, которые повторяются в таблице users. Подзапрос сначала группирует все значения по email и выбирает те, которые встречаются более одного раза. Главный запрос затем извлекает эти значения.
Использование IN может быть ограничено производительностью, если набор данных слишком большой. В таких случаях следует рассмотреть альтернативы, такие как EXISTS или JOIN, которые могут работать быстрее в зависимости от ситуации. Тем не менее, IN остаётся удобным для быстрого поиска совпадений среди небольших наборов данных.
Использование подзапросов для поиска совпадений в SQL
Для поиска совпадений с использованием подзапросов, обычно применяются следующие подходы:
- Подзапрос в предложении WHERE – позволяет искать значения, соответствующие результатам другого запроса.
Пример подзапроса, который находит всех сотрудников, работающих в тех же департаментах, что и заданный сотрудник:
SELECT employee_id, employee_name FROM employees WHERE department_id = ( SELECT department_id FROM employees WHERE employee_name = 'Иванов' );
Здесь подзапрос в WHERE возвращает идентификатор департамента, а основной запрос находит всех сотрудников, принадлежащих к этому департаменту.
- Подзапрос в предложении FROM – позволяет использовать результаты подзапроса как временную таблицу для дальнейших вычислений.
Пример подзапроса в FROM, который находит среднюю зарплату по каждому департаменту и сопоставляет ее с зарплатой сотрудников:
SELECT e.employee_name, e.salary, d.avg_salary FROM employees e JOIN ( SELECT department_id, AVG(salary) AS avg_salary FROM employees GROUP BY department_id ) d ON e.department_id = d.department_id WHERE e.salary > d.avg_salary;
В этом примере подзапрос в FROM создает таблицу, содержащую среднюю зарплату по департаментам, и затем основной запрос использует эту информацию для поиска сотрудников, чья зарплата выше средней по своему департаменту.
- Подзапрос с использованием EXISTS – используется для проверки существования записей, соответствующих условиям.
Подзапрос с EXISTS помогает находить записи, для которых существует соответствующий результат в другом запросе. Пример:
SELECT employee_name FROM employees e WHERE EXISTS ( SELECT 1 FROM projects p WHERE p.employee_id = e.employee_id AND p.project_status = 'Active' );
- Подзапрос с использованием IN – позволяет сравнивать значения с набором результатов, возвращаемых подзапросом.
Подзапрос с IN используется для поиска совпадений с множественными значениями. Пример:
SELECT employee_name FROM employees WHERE department_id IN ( SELECT department_id FROM departments WHERE location = 'Москва' );
Этот запрос находит всех сотрудников, работающих в департаментах, расположенных в Москве. Подзапрос в IN возвращает список департаментов, а основной запрос ищет сотрудников, чьи департамент идентичен одному из возвращаемых значений.
Использование подзапросов значительно расширяет возможности SQL-запросов, позволяя более гибко фильтровать данные и выполнять сложные операции с несколькими таблицами. Подзапросы могут улучшить производительность запросов, если они правильно оптимизированы, и помогают избежать избыточных соединений данных, когда это возможно.
Фильтрация дубликатов с помощью DISTINCT

Для удаления дубликатов в SQL используется ключевое слово DISTINCT. Оно позволяет выбрать только уникальные значения из столбца или нескольких столбцов, исключая повторяющиеся записи.
Пример использования: если в таблице employees содержатся дублирующиеся значения в столбце department_id, запрос с DISTINCT поможет выбрать только уникальные идентификаторы департаментов:
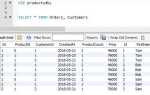
SELECT DISTINCT department_id FROM employees;
Этот запрос вернет список уникальных идентификаторов департаментов, игнорируя все повторяющиеся записи.
Если необходимо получить уникальные комбинации значений нескольких столбцов, можно указать их через запятую. Например, для выбора уникальных сочетаний department_id и job_title:
SELECT DISTINCT department_id, job_title FROM employees;
Важный момент: DISTINCT работает только на уровне строк. То есть, если в запросе указаны несколько столбцов, то для фильтрации дубликатов сравниваются все значения в этих столбцах. Если хотя бы одно из значений отличается, строка считается уникальной.
При использовании DISTINCT важно помнить, что этот оператор может повлиять на производительность запросов, особенно если таблица содержит большое количество данных. В таких случаях стоит обратить внимание на индексы и структуру данных, чтобы минимизировать нагрузку на базу данных.
В некоторых случаях для оптимизации можно комбинировать DISTINCT с другими операторами, такими как GROUP BY, чтобы сгруппировать данные по нужным признакам перед применением фильтрации.
Поиск дубликатов с использованием GROUP BY и HAVING
Для поиска дубликатов в базе данных часто используют конструкцию GROUP BY в сочетании с фильтром HAVING. Эта техника позволяет группировать строки по определённым полям и фильтровать группы, которые имеют более одного элемента, что и указывает на наличие дубликатов.
Пример простого запроса для поиска дубликатов по одному полю:
SELECT column_name, COUNT(*) FROM table_name GROUP BY column_name HAVING COUNT(*) > 1;
В этом запросе происходит следующее:
- GROUP BY группирует строки по значению в колонке column_name,
- COUNT(*) подсчитывает количество строк в каждой группе.
Если количество строк в группе больше одного, то это указывает на наличие дубликатов. Фильтр HAVING COUNT(*) > 1 исключает группы, которые содержат только одно значение.
Важно помнить, что для поиска дубликатов можно использовать несколько столбцов. В таком случае запрос будет выглядеть так:
SELECT column1, column2, COUNT(*) FROM table_name GROUP BY column1, column2 HAVING COUNT(*) > 1;
Здесь column1 и column2 образуют пару, которая будет анализироваться на предмет дубликатов. Если такая пара встречается более одного раза, то она будет выведена в результирующем наборе.
Также стоит учесть, что в отличие от оператора WHERE, который фильтрует строки до группировки, HAVING применяет фильтрацию после группировки. Это позволяет более гибко работать с агрегированными данными, например, выявляя только те группы, где есть дубликаты.
Для улучшения производительности при работе с большими наборами данных рекомендуется индексировать поля, по которым происходит группировка, чтобы ускорить выполнение запроса.
Использование условия EXISTS для нахождения совпадений

В SQL условие EXISTS позволяет проверять наличие строк, которые соответствуют заданному подзапросу. Это условие используется для поиска совпадений, когда необходимо определить, существует ли хотя бы одна строка, удовлетворяющая определённым критериям. Использование EXISTS часто применяется в случае, когда нужно быстро проверить наличие данных в связанных таблицах без возвращения самих данных.
Пример использования EXISTS для нахождения совпадений выглядит следующим образом:
SELECT * FROM orders o WHERE EXISTS ( SELECT 1 FROM customers c WHERE c.customer_id = o.customer_id );
В этом примере подзапрос проверяет, существует ли клиент с соответствующим customer_id в таблице customers. Если такой клиент найден, то запись из таблицы orders будет включена в результат.
Важно помнить, что EXISTS не возвращает данных из подзапроса, а лишь проверяет его наличие. Поэтому в подзапросе часто используют конструкцию SELECT 1, которая является более эффективной, чем выборка реальных столбцов. Это позволяет ускорить выполнение запроса.
Использование EXISTS также выгодно, когда подзапрос возвращает большое количество строк, так как база данных сразу завершает поиск при нахождении первого совпадения. Это может значительно ускорить выполнение запросов по сравнению с JOIN или IN, где нужно обработать все строки подзапроса.
Другим преимуществом EXISTS является его возможность работать с подзапросами, которые могут возвращать более одного результата. В отличие от IN, где список значений должен быть ограничен, EXISTS эффективно проверяет наличие хотя бы одного совпадения.