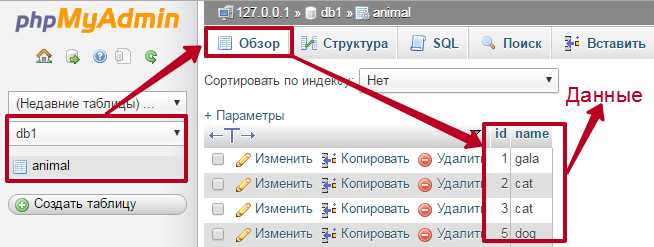
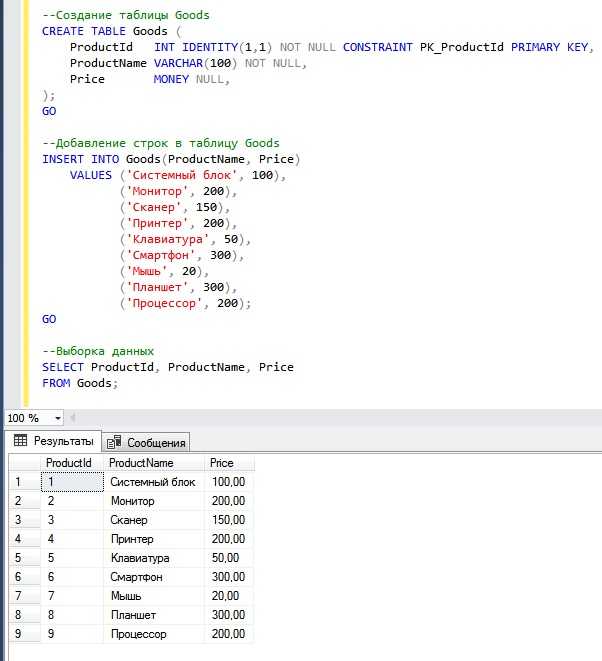
Для извлечения строк из таблиц SQL используется команда SELECT, которая является основным инструментом при работе с базами данных. Но для того чтобы запрос был эффективным и быстрым, важно учитывать структуру данных и правильно формулировать условия выбора. В этой статье мы рассмотрим ключевые моменты, которые помогут вам извлечь нужные строки с минимальными затратами времени и ресурсов.
SELECT позволяет работать с любыми строками таблицы, однако для точного извлечения данных необходимы дополнительные операторы. Одним из самых часто используемых является WHERE, который фильтрует данные по заданному условию. Применение WHERE ограничивает результат запроса, что особенно важно при работе с большими таблицами.
При извлечении строк из таблицы важно не только правильно составить условие, но и понимать структуру индексов базы данных. Индексы значительно ускоряют выборку, однако их неправильное использование может привести к снижению производительности. Важно помнить, что индексы оптимально использовать для колонок, которые часто участвуют в фильтрации и сортировке данных.
Чтобы извлечь строку по уникальному значению, например, по первичному ключу, можно использовать условие WHERE с точным значением. Пример запроса:
SELECT * FROM users WHERE user_id = 123;
Этот запрос вернёт строку, где значение user_id равно 123. Важно при этом использовать индексы для столбцов с уникальными значениями, что существенно ускоряет выполнение запроса, особенно на больших объёмах данных.
Как использовать SELECT для извлечения данных из таблицы
SELECT столбец_1, столбец_2, ... FROM таблица;
Если нужно извлечь все данные из таблицы, используется звездочка (*) вместо перечисления столбцов:
SELECT * FROM таблица;
Чтобы получить только строки, которые соответствуют определённым условиям, применяются операторы фильтрации. Например, для выборки строк, где значение в столбце «age» больше 18:
SELECT * FROM users WHERE age > 18;
Важно помнить, что условие в WHERE может быть не только числовым, но и строковым, логическим или датированным. Для работы с текстовыми значениями используют операторы сравнения, такие как =, LIKE или IN:
SELECT name FROM employees WHERE department = 'IT';
Для извлечения уникальных значений из столбца используется оператор DISTINCT. Это позволяет избавиться от повторяющихся данных:
SELECT DISTINCT country FROM customers;
В дополнение к базовым фильтрам можно применять сортировку результатов с помощью ORDER BY. Например, чтобы отсортировать данные по возрасту в порядке убывания:
SELECT name, age FROM users ORDER BY age DESC;
Для извлечения данных из нескольких таблиц используются объединения (JOIN). Пример выборки данных из двух таблиц с соединением по общему столбцу «id»:
SELECT users.name, orders.amount FROM users JOIN orders ON users.id = orders.user_id;
Используя агрегатные функции, такие как COUNT, SUM, AVG, MIN, MAX, можно проводить вычисления на данных. Например, для подсчёта количества пользователей в каждом городе:
SELECT city, COUNT(*) FROM users GROUP BY city;
Для ограничения числа строк, возвращаемых запросом, используется оператор LIMIT. Это полезно, если нужно получить только первые несколько записей:
SELECT * FROM products LIMIT 10;
Также можно комбинировать несколько условий с логическими операторами AND и OR, чтобы более точно настроить выборку:
SELECT name, salary FROM employees WHERE department = 'HR' AND salary > 50000;
Использование SELECT предоставляет гибкость для извлечения данных, но важно помнить, что для оптимальной работы с большими объёмами данных необходимо учитывать индексы и правильно строить запросы, чтобы избежать излишней нагрузки на сервер.
Фильтрация строк с помощью WHERE
Оператор WHERE используется для фильтрации строк в SQL-запросах. Он позволяет сузить выборку данных, указав условия, которым должны соответствовать строки. Например, можно извлечь только те записи, которые имеют определённое значение в одном или нескольких столбцах. Синтаксис оператора WHERE следующий:
SELECT столбцы FROM таблица WHERE условие;
Основные типы условий:
- Равенство: Для выборки строк с точным значением столбца используется оператор =. Например, WHERE age = 30 вернёт все строки, где возраст равен 30.
- Диапазоны: Оператор BETWEEN применяется для поиска значений в пределах диапазона. Например, WHERE price BETWEEN 10 AND 100 вернёт строки, где цена лежит в указанном диапазоне.
- Сравнение: Операторы >, <, >=, <= могут использоваться для извлечения данных, которые соответствуют заданным ограничениям. Например, WHERE salary > 50000 выберет всех сотрудников с зарплатой выше 50000.
- Паттерны: Оператор LIKE применяется для фильтрации строк по шаблону. Используются специальные символы, такие как % для любого количества символов и _ для одного символа. Пример: WHERE name LIKE ‘A%’ вернёт все имена, начинающиеся на букву A.
- NULL значения: Для проверки на отсутствие данных используется IS NULL или IS NOT NULL. Пример: WHERE email IS NULL вернёт строки, где значение в столбце email отсутствует.
Можно комбинировать несколько условий с помощью логических операторов AND и OR. Оператор AND требует выполнения всех условий, а OR – хотя бы одного. Пример комбинированного условия:
SELECT * FROM employees WHERE age > 30 AND salary > 50000;
Рекомендуется всегда проверять типы данных, с которыми работаете. Например, для строковых значений часто нужно использовать апострофы: WHERE name = ‘Иван’. Ошибки с типами данных могут привести к некорректным результатам.
Оператор WHERE позволяет значительно оптимизировать запросы, извлекая только те данные, которые необходимы для решения текущей задачи, и исключая лишние строки из результата.
Использование LIMIT для ограничения количества извлекаемых строк
Пример базового использования:
SELECT * FROM employees LIMIT 10;Этот запрос вернет только первые 10 строк из таблицы employees. Важно отметить, что порядок строк не гарантируется, если не указать оператор ORDER BY.
Для более гибкой работы с выборкой можно комбинировать LIMIT с OFFSET. Это полезно, если необходимо пропустить определенное количество строк перед извлечением данных.
Пример с OFFSET:
SELECT * FROM employees LIMIT 10 OFFSET 20;Этот запрос извлекает 10 строк, начиная с 21-й строки. OFFSET позволяет удобно реализовать постраничную навигацию.
Когда важно получить случайные строки, можно использовать ORDER BY RAND() вместе с LIMIT:
SELECT * FROM products ORDER BY RAND() LIMIT 5;Этот запрос вернет 5 случайных строк из таблицы products.
Основные рекомендации по использованию LIMIT:
- Используйте
LIMITдля ускорения работы с большими таблицами, сокращая объем передаваемых данных. - Применяйте
LIMITв сочетании сORDER BY, если важен определенный порядок извлекаемых данных. - Когда требуется выбрать данные для анализа или отображения на страницах, не забывайте о
OFFSETдля корректной навигации. - Будьте осторожны при использовании
ORDER BY RAND()на больших таблицах, так как это может сильно повлиять на производительность.
Как извлечь строку по уникальному идентификатору
Пример запроса:
SELECT * FROM users WHERE id = 42;
Звёздочка * означает выбор всех столбцов. Для повышения читаемости и производительности лучше явно указывать нужные поля:
SELECT name, email FROM users WHERE id = 42;
Если тип идентификатора – строковый (например, UUID), значение должно быть заключено в одинарные кавычки:
SELECT * FROM users WHERE id = ‘a1b2c3d4-e5f6-7890-abcd-1234567890ef’;
При работе с пользовательским вводом необходимо использовать подготовленные выражения или параметры запроса, чтобы исключить SQL-инъекции. Пример на PostgreSQL с использованием переменной:
PREPARE get_user (int) AS SELECT * FROM users WHERE id = $1;
EXECUTE get_user(42);
Если поле id индексировано или является первичным ключом, запрос выполняется быстро, даже в таблицах с миллионами записей. Проверяйте наличие индекса с помощью команды EXPLAIN:
EXPLAIN SELECT * FROM users WHERE id = 42;
Извлечение по идентификатору – это атомарная операция, возвращающая не более одной строки. При получении нескольких строк следует проверить уникальность значений в целевом столбце.
Применение оператора LIKE для поиска по шаблону
Оператор LIKE позволяет извлекать строки, соответствующие заданному шаблону. Он применяется в сочетании с ключевым словом WHERE и поддерживает два специальных символа: % и _. Символ % заменяет любое количество символов, включая ноль. Символ _ соответствует ровно одному произвольному символу.
Для поиска всех записей, где имя начинается на «А», используется запрос:
SELECT * FROM users WHERE name LIKE 'А%';
Чтобы найти строки, содержащие подстроку «иван» в любом месте поля, применяют:
SELECT * FROM users WHERE name LIKE '%иван%';
Если требуется найти строки, где третий символ – «а», подходит шаблон:
SELECT * FROM users WHERE name LIKE '__а%';
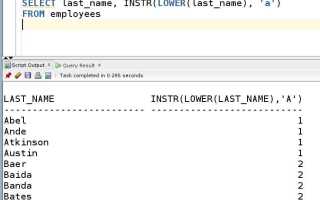
Сравнение с LIKE чувствительно к регистру в большинстве систем, кроме SQLite. Для нечувствительного поиска используйте ILIKE в PostgreSQL или функцию LOWER():
SELECT * FROM users WHERE LOWER(name) LIKE 'анна%';
Для повышения производительности избегайте начальных % в шаблоне, поскольку они препятствуют использованию индексов. Если необходим поиск по окончанию строки, как в запросе LIKE '%ова', целесообразно рассмотреть полнотекстовый поиск или выделение нужных данных в отдельное поле с индексом.
Извлечение строк с использованием логических операторов AND и OR
Операторы AND и OR позволяют формировать точные условия для выборки строк. AND объединяет условия, требуя их одновременного выполнения, OR – допускает выполнение хотя бы одного.
Для извлечения клиентов из Москвы, совершивших покупку на сумму более 10 000 рублей:
SELECT * FROM customers
WHERE city = 'Москва' AND purchase_amount > 10000;Для получения списка заказов, оформленных либо в 2024 году, либо с приоритетом «Высокий»:
SELECT * FROM orders
WHERE YEAR(order_date) = 2024 OR priority = 'Высокий';При комбинировании AND и OR важно использовать скобки для управления порядком выполнения. Пример – все сотрудники из отдела продаж в Москве или Санкт-Петербурге:
SELECT * FROM employees
WHERE department = 'Продажи' AND (city = 'Москва' OR city = 'Санкт-Петербург');Нарушение порядка операций приведёт к неправильной выборке. Скобки всегда задают приоритет выполнения, аналогично арифметике.
Для сложных фильтров рекомендуется пошагово тестировать условия, чтобы убедиться в корректности логики. Используйте EXPLAIN для анализа плана выполнения запросов, особенно при работе с большими таблицами.
Как извлечь данные с сортировкой по определенному столбцу
Для получения отсортированных данных из таблицы SQL используется директива ORDER BY. Она позволяет упорядочить строки по одному или нескольким столбцам в заданном направлении – по возрастанию или убыванию.
- Сортировка по возрастанию (по умолчанию):
SELECT * FROM employees ORDER BY last_name; - Сортировка по убыванию:
SELECT * FROM employees ORDER BY salary DESC; - Множественная сортировка:
SELECT * FROM employees ORDER BY department_id ASC, salary DESC;
При сортировке по текстовым столбцам важно учитывать регистр. В большинстве СУБД сортировка чувствительна к регистру, но поведение можно изменить, применив функции:
- В PostgreSQL:
SELECT * FROM clients ORDER BY LOWER(name); - В MySQL:
SELECT * FROM clients ORDER BY name COLLATE utf8_general_ci;
Если необходимо ограничить количество строк после сортировки, добавляется LIMIT:
SELECT * FROM products ORDER BY price DESC LIMIT 5;Для более стабильных результатов при одинаковых значениях сортируемого столбца добавляют вторичный ключ сортировки. Это особенно важно при использовании пагинации:
SELECT * FROM orders ORDER BY order_date DESC, id ASC;Избегайте сортировки по столбцам, по которым нет индексов, при работе с большими таблицами – это снижает производительность. Создайте индекс на соответствующий столбец, если сортировка используется регулярно.
Как объединять таблицы с помощью JOIN для извлечения строк
JOIN применяется, когда данные находятся в разных таблицах и требуется объединение по логической связи. Используйте INNER JOIN, чтобы получить строки, у которых есть совпадающие значения в обеих таблицах. Например, при соединении users и orders по user_id:
SELECT users.name, orders.total FROM users INNER JOIN orders ON users.id = orders.user_id;
Если необходимо включить всех пользователей, даже тех, у кого нет заказов, используйте LEFT JOIN:
SELECT users.name, orders.total FROM users LEFT JOIN orders ON users.id = orders.user_id;
RIGHT JOIN возвращает все строки из правой таблицы и совпадающие из левой. Подходит, когда приоритет – правая таблица:
SELECT users.name, orders.total FROM users RIGHT JOIN orders ON users.id = orders.user_id;
При соединении более двух таблиц применяйте каскадные JOIN, явно указывая все условия объединения. Это предотвращает избыточные строки в результате и сохраняет читаемость запроса:
SELECT u.name, o.total, p.name FROM users u JOIN orders o ON u.id = o.user_id JOIN products p ON o.product_id = p.id;
Избегайте использования CROSS JOIN без фильтрации – он создаёт декартово произведение и быстро увеличивает объём данных. Всегда уточняйте условия ON, особенно при объединении таблиц с несколькими потенциальными связями.