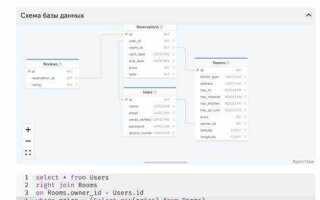
Извлечение всех данных из таблицы SQL – это базовая задача, с которой сталкиваются разработчики, аналитики и администраторы баз данных. Для этого используется запрос SELECT, который позволяет получить данные в нужном формате. Хотя запросы SELECT могут быть довольно простыми, важно понимать особенности и возможности этого инструмента для эффективного извлечения данных.
Для извлечения всех записей из таблицы используется запрос SELECT * FROM название_таблицы. Этот запрос возвращает все столбцы и строки из указанной таблицы. Однако стоит учитывать, что использование звездочки (*) может быть не всегда оптимальным, особенно если таблица содержит большое количество столбцов или если нужно извлечь только часть данных.
Если требуется извлечь конкретные столбцы, вместо звездочки указываются имена нужных полей. Например, SELECT имя, возраст FROM пользователи извлечет только данные о имени и возрасте пользователей. Такой подход позволяет сократить объем извлекаемых данных и повысить производительность запроса.
Иногда данные из таблицы нужно извлечь с дополнительной фильтрацией, например, по условию или с сортировкой. Для этого используются операторы WHERE, ORDER BY и другие. Например, SELECT * FROM пользователи WHERE возраст > 30 ORDER BY имя вернет всех пользователей старше 30 лет, отсортированных по имени.
Подключение к базе данных SQL через клиент
Для извлечения данных из базы данных SQL через клиент необходимо корректно настроить подключение. Это ключевой шаг, чтобы начать работу с базой данных и извлекать данные с помощью SQL-запросов.
1. Выбор клиента
Для подключения к SQL-базе данных можно использовать различные клиентские приложения. Наиболее популярные: MySQL Workbench для MySQL, pgAdmin для PostgreSQL, DBeaver для работы с несколькими СУБД. Выбор зависит от типа используемой базы данных.
2. Установка драйвера
Каждый клиент требует установку драйвера для корректного взаимодействия с базой данных. Для MySQL используется MySQL Connector, для PostgreSQL – psqlODBC, для SQL Server – ODBC Driver. Установите соответствующий драйвер на компьютере, следуя инструкциям на официальных сайтах.
3. Настройка подключения
После установки клиента необходимо указать параметры подключения:
- Хост – IP-адрес или доменное имя сервера, где размещена база данных.
- Порт – по умолчанию для MySQL это 3306, для PostgreSQL – 5432, для SQL Server – 1433.
- Имя базы данных – укажите название базы данных, к которой нужно подключиться.
- Пользователь – имя пользователя для подключения к базе данных.
- Пароль – пароль для указанного пользователя.
Заполните эти поля в интерфейсе клиента. Если параметры верны, соединение будет установлено автоматически.
4. Подключение к базе данных
Нажмите на кнопку подключения. Если все данные введены правильно, клиент создаст соединение с сервером базы данных, и вы сможете приступать к выполнению SQL-запросов для извлечения данных.
5. Проблемы подключения
Если подключение не удается, проверьте:
- Правильность введенных данных (IP, порт, имя пользователя, пароль).
- Сетевые настройки (например, если база данных находится на удаленном сервере, убедитесь, что порт открыт для внешних подключений).
- Наличие нужных драйверов и их правильную установку.
6. Безопасность подключения
Для повышения безопасности рекомендуется использовать зашифрованное соединение (SSL). В настройках клиента можно указать путь к сертификатам для включения SSL-соединения, что обеспечит защиту данных при передаче.
Как составить запрос для извлечения всех данных из таблицы
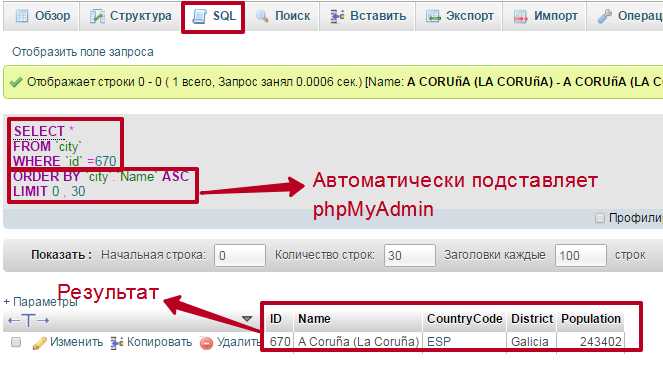
Для извлечения всех данных из таблицы в SQL используется оператор SELECT. Запрос для получения всех строк из таблицы выглядит следующим образом:
SELECT * FROM имя_таблицы;В данном случае, звездочка (*) указывает на то, что необходимо выбрать все столбцы в таблице. FROM указывает на таблицу, из которой извлекаются данные. Необходимо заменить имя_таблицы на название нужной таблицы.
Важно помнить, что такой запрос извлекает все строки и все столбцы таблицы, что может быть неэффективным для больших объемов данных. Если нужно получить только определенные столбцы, лучше указать их явно, перечислив через запятую:
SELECT столбец1, столбец2 FROM имя_таблицы;Если вы хотите добавить фильтрацию данных, используйте WHERE для ограничения выборки по определенным условиям. Например:
SELECT * FROM имя_таблицы WHERE условие;Этот запрос извлечет только те строки, которые соответствуют условию. Условие может быть любым выражением, например, сравнение значений в столбцах.
Для получения данных с сортировкой используйте ORDER BY:
SELECT * FROM имя_таблицы ORDER BY столбец ASC|DESC;Здесь ASC указывает на сортировку по возрастанию (по умолчанию), а DESC – по убыванию.
Таким образом, запрос для извлечения всех данных из таблицы может быть адаптирован в зависимости от конкретных требований, таких как выборка только нужных столбцов, фильтрация или сортировка данных.
Использование SELECT для получения всех строк таблицы
Чтобы извлечь все строки из таблицы SQL, используется базовый запрос SELECT. С помощью этого оператора можно получить весь набор данных, который хранится в указанной таблице, без фильтрации или дополнительных условий. Для выполнения такого запроса используется следующая структура:
SELECT * FROM имя_таблицы;
Здесь * обозначает выбор всех колонок, а имя_таблицы – это название конкретной таблицы, данные из которой необходимо извлечь. Такой запрос вернёт все записи без исключений.
Важно помнить, что запрос SELECT * FROM может быть ресурсоёмким, особенно если таблица содержит большое количество строк и колонок. В таких случаях рекомендуется избегать его использования в продуктивных системах, так как это может существенно нагрузить сервер.
Если необходимо выбрать только определённые столбцы, следует указать их явно, перечислив через запятую. Например:
SELECT колонка1, колонка2 FROM имя_таблицы;
Для повышения производительности можно ограничить количество извлекаемых данных с помощью оператора LIMIT, который позволяет указать максимальное количество строк для извлечения. Например:
SELECT * FROM имя_таблицы LIMIT 100;
Этот запрос вернёт только первые 100 строк таблицы. Такой подход полезен при тестировании или в случаях, когда нужно быстро получить часть данных.
В некоторых ситуациях полезно будет отсортировать результат запроса. Для этого применяется оператор ORDER BY. Например, чтобы отсортировать данные по возрастанию значений в определённой колонке:
SELECT * FROM имя_таблицы ORDER BY колонка ASC;
Здесь ASC указывает на сортировку по возрастанию, а DESC – по убыванию.
При работе с большими таблицами, помимо сортировки и ограничения количества строк, также можно применять индексы для ускорения выполнения запросов. Индексы значительно ускоряют поиск и сортировку данных, что особенно важно при извлечении всех строк из таблицы.
Как фильтровать данные с помощью WHERE при извлечении всех строк
Использование оператора WHERE позволяет ограничить результаты запроса, извлекая только те строки, которые соответствуют заданным условиям. Это существенно ускоряет работу с большими таблицами и делает выборку данных более точной.
Чтобы применить фильтрацию, указывайте условия в блоке WHERE после указания таблицы и полей, которые хотите извлечь.
Пример запроса:
SELECT * FROM employees WHERE salary > 50000;В данном случае будут возвращены все строки из таблицы employees, где значение поля salary больше 50,000.
Для эффективной работы с фильтрами стоит учитывать следующие аспекты:
- Типы данных: Убедитесь, что условие фильтрации соответствует типу данных поля. Например, нельзя сравнивать строковое значение с числовым.
- Логические операторы: Для комбинирования условий используйте операторы
AND,ORиNOT. Это позволяет создавать более сложные фильтры. - Использование диапазонов: Для работы с диапазонами значений применяйте операторы
BETWEENиIN. Они упрощают проверку на наличие значений в заданных интервалах. - Поиск в строках: Если нужно искать по части строки, используйте операторы
LIKEиILIKE(если база данных поддерживает чувствительность к регистру).
Примеры фильтрации:
- По диапазону значений:
SELECT * FROM products WHERE price BETWEEN 10 AND 100; - По множеству значений:
SELECT * FROM orders WHERE status IN ('completed', 'shipped'); - По подстроке в строковом поле:
SELECT * FROM customers WHERE name LIKE 'John%';
Правильное использование оператора WHERE улучшает производительность запросов и минимизирует объем извлекаемых данных, что особенно важно при работе с большими базами данных.
Оператор ORDER BY используется для сортировки данных, извлекаемых из таблицы SQL. Этот оператор позволяет организовать результаты запроса по одному или нескольким столбцам в порядке возрастания или убывания. Без сортировки данные могут быть представлены в произвольном порядке, что затруднит анализ и использование информации.
Основные аспекты использования ORDER BY:
- Упорядочивание данных: С помощью
ORDER BYможно сортировать результаты по любому полю. Для этого нужно указать имя столбца или его псевдоним в запросе. - Указание порядка сортировки: Сортировка может быть выполнена в двух направлениях:
ASC(по возрастанию) илиDESC(по убыванию). По умолчанию используетсяASC, если не указано иное. - Множественные критерии сортировки: Можно использовать несколько столбцов для сортировки. В этом случае сортировка будет происходить по первому столбцу, а при совпадении значений – по следующему столбцу.
Пример использования ORDER BY:
SELECT name, age FROM employees ORDER BY age DESC, name ASC;Этот запрос извлечет имена и возраст сотрудников из таблицы employees и отсортирует их сначала по возрасту (по убыванию), а затем по имени (по возрастанию), если возраст одинаков.
Рекомендации при использовании ORDER BY:
- Производительность: Сортировка данных может значительно замедлить выполнение запроса, особенно если таблица содержит большое количество записей. Для оптимизации можно использовать индексы на столбцы, по которым часто выполняется сортировка.
- Ручная сортировка: Если необходимо сложное упорядочивание, которое не поддерживает стандартная сортировка, можно использовать функции сортировки внутри SQL-запроса или выполнить сортировку на уровне приложения.
Знание правильного применения ORDER BY помогает не только улучшить восприятие данных, но и способствует оптимизации запросов и эффективному использованию ресурсов базы данных.
Как извлечь данные с учётом различных типов данных

При извлечении данных из SQL-таблицы важно учитывать типы данных, чтобы правильно обрабатывать результаты и избежать ошибок. SQL поддерживает несколько типов данных: числовые, строковые, даты и временные метки, а также типы для работы с большими объёмами данных, такие как BLOB и текстовые поля. В зависимости от типа данных могут потребоваться специальные подходы к извлечению и обработке.
Числовые данные, например, INT, FLOAT или DECIMAL, можно извлекать напрямую с помощью стандартных SELECT-запросов. Однако при извлечении данных с плавающей точкой следует учитывать возможные погрешности при вычислениях, особенно если значение содержит много знаков после запятой. Рекомендуется использовать функции округления (например, ROUND) для приведения данных к нужной точности.
Для строковых типов данных (VARCHAR, TEXT) важно помнить о возможных различиях в кодировках между базой данных и приложением. В некоторых случаях может понадобиться конвертация строк в нужную кодировку, чтобы избежать проблем с отображением символов. Для обработки строк часто применяются функции CONCAT для объединения, LENGTH для измерения длины строки и TRIM для удаления лишних пробелов.
С типами данных для работы с датами (DATE, DATETIME, TIMESTAMP) связаны определённые особенности. Если нужно извлечь только дату без времени, можно использовать функцию DATE() в MySQL или CAST в SQL Server для приведения к типу DATE. Для работы с диапазонами дат часто применяются операторы BETWEEN или функции, такие как DATE_ADD и DATE_SUB, для вычисления значений на основе текущей даты.
Когда нужно извлечь данные с учётом временных зон, важно использовать функции, которые учитывают часовые пояса, например, CONVERT_TZ в MySQL. Также стоит помнить, что для некоторых приложений корректная обработка временных меток важна при учёте перехода на летнее время или при изменении часового пояса.
В случае работы с BLOB или типами данных для хранения больших объектов (например, изображения или файлы) важно понимать, как правильно извлекать и сохранять данные. Для этого часто используется потоковый подход, где данные извлекаются по частям, что предотвращает перегрузку памяти при обработке больших файлов.
При извлечении данных из таблицы всегда следует проверять типы данных в схеме базы данных, чтобы правильно интерпретировать и обработать результаты. Также полезно использовать типы данных, оптимизированные для хранения определённых значений, чтобы обеспечить максимально эффективную работу с базой данных и минимизировать риск ошибок.
Обработка больших объёмов данных при извлечении
При извлечении данных из SQL-баз данных, работа с большими объёмами информации требует особого подхода. Наиболее эффективные методы включают использование пагинации, оптимизацию запросов и разделение на более мелкие блоки.
Пагинация данных помогает избежать перегрузки памяти, разбивая запросы на более мелкие части. Вместо того, чтобы извлекать все записи за один запрос, можно запрашивать данные по частям, например, с использованием оператора LIMIT в сочетании с OFFSET. Это позволяет контролировать размер выборки и минимизировать нагрузку на систему.
Для улучшения производительности важно использовать индексы. Они ускоряют поиск и выборку данных, особенно при работе с большими таблицами. Правильный выбор индексов для столбцов, которые часто используются в WHERE или JOIN, существенно уменьшает время выполнения запросов.
Если данные содержат несколько связанных таблиц, рекомендуется использовать технику «ленивой загрузки» (lazy loading), когда связанные данные извлекаются только по мере необходимости. Это помогает снизить нагрузку на сеть и процессор, избегая предварительного извлечения всех данных.
Другим важным аспектом является использование кэширования. Для повторяющихся запросов или данных, которые не меняются часто, можно использовать кэш, чтобы избежать избыточных запросов к базе данных. Это снижает нагрузку и ускоряет извлечение данных.
Разделение на партиции также может быть эффективным методом при работе с большими таблицами. Используя партиционирование, можно хранить данные в нескольких сегментах, что значительно ускоряет операции выборки и обновления. Например, таблицы могут быть разделены по дате или по диапазону значений в ключевом столбце.
Наконец, важно внимательно отслеживать время выполнения запросов и анализировать возможные узкие места с помощью инструментов профилирования. Это позволяет выявить и устранить неэффективные запросы, что в свою очередь ускоряет обработку больших объёмов данных.
Как сохранить извлечённые данные в файл (CSV, JSON и другие форматы)
CSV – это текстовый формат, где данные разделены запятыми. Этот формат широко используется из-за своей простоты и совместимости с различными инструментами, такими как Excel и Python. Для сохранения данных в CSV, можно использовать следующий код на Python с использованием библиотеки csv:
import csv
# Подключение к базе данных и извлечение данных
cursor.execute("SELECT * FROM your_table")
rows = cursor.fetchall()
# Сохранение в CSV
with open('data.csv', mode='w', newline='') as file:
writer = csv.writer(file)
writer.writerow([description[0] for description in cursor.description]) # Заголовки столбцов
writer.writerows(rows)
В приведенном примере данные извлекаются с помощью SQL-запроса и сохраняются в файл data.csv. Обратите внимание на строку, где добавляются заголовки столбцов.
JSON – формат, который подходит для сохранения структурированных данных, таких как массивы или объекты. Это идеальный вариант, если необходимо сохранить данные в виде, удобном для обработки в JavaScript или других языках программирования. Для сохранения в JSON используется библиотека json:
import json
# Извлечение данных из базы
cursor.execute("SELECT * FROM your_table")
rows = cursor.fetchall()
# Сохранение в JSON
with open('data.json', mode='w') as file:
json.dump(rows, file, default=str) # default=str для правильного сохранения данных времени
Этот код сохраняет извлеченные данные в файл data.json. Обратите внимание, что метод json.dump() преобразует данные в JSON-формат и записывает их в файл.
Excel – ещё один популярный формат для сохранения данных, который позволяет удобно работать с таблицами в программах вроде Microsoft Excel. Для работы с Excel можно использовать библиотеку pandas, которая позволяет извлекать и сохранять данные в различных форматах, включая Excel. Пример кода:
import pandas as pd
# Извлечение данных в pandas DataFrame
cursor.execute("SELECT * FROM your_table")
columns = [description[0] for description in cursor.description]
df = pd.DataFrame(cursor.fetchall(), columns=columns)
# Сохранение в Excel
df.to_excel('data.xlsx', index=False)
Этот код сохраняет данные в файл data.xlsx, избегая записи индексов строк, что делает файл более чистым для анализа.
XML – формат, который часто используется для обмена данными между различными системами. Он более сложен в синтаксисе, чем JSON, но может быть полезен для более структурированных данных. Для работы с XML можно использовать библиотеку xml.etree.ElementTree:
import xml.etree.ElementTree as ET
# Извлечение данных из базы
cursor.execute("SELECT * FROM your_table")
rows = cursor.fetchall()
# Создание корневого элемента
root = ET.Element("root")
# Добавление данных
for row in rows:
item = ET.SubElement(root, "item")
for col, value in zip(cursor.description, row):
sub_elem = ET.SubElement(item, col[0])
sub_elem.text = str(value)
# Сохранение в XML
tree = ET.ElementTree(root)
tree.write("data.xml")
В этом примере каждый ряд из базы данных сохраняется как отдельный элемент item в XML-файле, с подэлементами для каждого столбца.
Каждый формат имеет свои преимущества в зависимости от задач. Для обработки больших объемов данных лучше использовать CSV или Excel, так как эти форматы поддерживаются большинством аналитических и статистических инструментов. JSON подходит для обмена данными между веб-серверами, а XML используется для обмена данными между различными системами с более сложной структурой.
Вопрос-ответ:
Как извлечь все данные из таблицы SQL?
Для извлечения всех данных из таблицы SQL можно использовать запрос `SELECT * FROM имя_таблицы;`. Это запрос возвращает все строки и столбцы из указанной таблицы. Однако стоит учитывать, что в случае очень больших таблиц такой запрос может занять много времени и потребовать значительных ресурсов.
Что означает использование символа * в запросе SELECT?
Символ * в запросе SQL означает выбор всех столбцов в таблице. Когда вы пишете `SELECT * FROM таблица`, это означает «выбрать все столбцы из таблицы». Если вы хотите извлечь только определённые столбцы, то нужно указать их имена вместо символа *.
Можно ли извлечь данные только из нескольких столбцов таблицы?
Да, для извлечения данных только из нескольких столбцов можно указать имена этих столбцов в запросе. Например: `SELECT столбец1, столбец2 FROM имя_таблицы;`. Такой запрос вернёт данные только из выбранных столбцов, что может быть полезно для улучшения производительности при работе с большими таблицами.
Как извлечь данные из таблицы, применяя фильтрацию?
Для фильтрации данных в SQL используется оператор `WHERE`. Например, запрос `SELECT * FROM таблица WHERE условие;` позволяет выбрать только те строки, которые удовлетворяют определённому условию. Например, `SELECT * FROM сотрудники WHERE возраст > 30;` вернёт всех сотрудников старше 30 лет.
Какие ограничения стоит учитывать при извлечении всех данных из большой таблицы?
При извлечении всех данных из большой таблицы стоит учитывать, что запросы могут занимать много времени и использовать значительные ресурсы системы, особенно если таблица содержит миллионы строк. Это может привести к замедлению работы базы данных. Для улучшения производительности можно использовать ограничение числа возвращаемых строк с помощью оператора `LIMIT`, либо извлекать данные порциями, используя пагинацию.