Процесс вставки данных в таблицу SQL может показаться простым, но когда речь идет о добавлении нескольких записей за один раз, важно понимать тонкости и особенности синтаксиса. В большинстве случаев для вставки нескольких строк в одну таблицу используется командa INSERT INTO, что позволяет значительно ускорить выполнение операций при работе с большими объемами данных.
Для добавления нескольких значений в таблицу можно использовать один запрос, включающий несколько групп значений в скобках. Это делает код более компактным и эффективным, чем выполнение нескольких отдельных запросов. Например, чтобы вставить три записи в таблицу, достаточно одного запроса:
INSERT INTO employees (name, position, salary)
VALUES ('Иванов', 'Менеджер', 50000),
('Петров', 'Разработчик', 75000),
('Сидоров', 'Аналитик', 60000);Однако важно помнить о некоторых нюансах. В первую очередь, количество значений в каждом наборе должно точно соответствовать числу столбцов, указанных в запросе. Это исключает возможность ошибок при вводе данных и повышает надежность работы с базой данных.
Использование одного запроса для нескольких записей не только ускоряет выполнение, но и снижает нагрузку на сервер, так как уменьшает количество соединений и времени на их обработку. При правильной настройке базы данных и оптимизации запросов, вставка нескольких строк за один запрос может существенно ускорить общую производительность системы.
Подготовка данных для вставки в таблицу
Перед тем как вставить несколько значений в таблицу SQL, важно правильно подготовить данные. Этот процесс включает проверку их соответствия структуре таблицы и формату, необходимому для корректной работы запроса.
1. Проверка типов данных: Каждое поле таблицы имеет свой тип данных (например, INTEGER, VARCHAR, DATE). Необходимо удостовериться, что данные, которые вы собираетесь вставить, соответствуют этим типам. Например, строки должны быть обернуты в одинарные кавычки, а числа не должны содержать лишних символов.
2. Форматирование дат: Если вы вставляете даты, используйте стандартный формат 'YYYY-MM-DD', чтобы избежать ошибок. Для более точного времени используйте формат 'YYYY-MM-DD HH:MM:SS'.
3. Удаление лишних пробелов: Пробелы в начале и конце строк могут привести к некорректной вставке данных. Перед подготовкой данных следует использовать функции для обрезки пробелов, такие как TRIM().
4. Использование значений по умолчанию: Если некоторые поля могут иметь значения по умолчанию, оставьте их пустыми. В запросах можно опускать такие столбцы, и база данных автоматически подставит нужные значения.
5. Подготовка множества значений: Для вставки нескольких строк данных можно использовать запрос с несколькими значениями в одном выражении. Например, для добавления нескольких записей используйте синтаксис:
INSERT INTO таблица (столбец1, столбец2, столбец3) VALUES (значение1, значение2, значение3), (значение4, значение5, значение6), (значение7, значение8, значение9);
6. Проверка на уникальность: Если в таблице есть уникальные ограничения, например, на столбец с первичным ключом, убедитесь, что в подготовленных данных нет дублирующих значений. Для этого можно использовать предварительный запрос для выборки существующих значений.
7. Обработка NULL-значений: При вставке данных важно учитывать, как база данных будет обрабатывать NULL значения. Если столбец может содержать пустые значения, убедитесь, что вы не вставляете неверные данные или оставляете их пустыми.
Тщательная подготовка данных не только уменьшит вероятность ошибок при вставке, но и повысит производительность базы данных, так как запросы будут выполняться быстрее и с меньшей вероятностью возникновения конфликтов.
Использование команды INSERT INTO для множественной вставки
Команда INSERT INTO позволяет добавить данные в таблицу SQL. Для вставки нескольких записей за один запрос можно использовать несколько значений в одном выражении. Это значительно ускоряет процесс вставки по сравнению с выполнением отдельных запросов для каждой записи.
Пример синтаксиса для множественной вставки данных:
INSERT INTO table_name (column1, column2, column3)
VALUES
(value1a, value2a, value3a),
(value1b, value2b, value3b),
(value1c, value2c, value3c);В этом примере добавляются три записи в таблицу table_name. Каждое значение в скобках представляет собой одну запись, где column1, column2 и column3 – это имена столбцов таблицы.
Основные моменты, которые стоит учитывать при множественной вставке:
- Количество значений в каждой строке должно соответствовать количеству столбцов в запросе.
- Типы данных в значениях должны совпадать с типами данных соответствующих столбцов таблицы.
- В случае вставки значений по умолчанию или NULL, эти значения нужно указать явно.
- Запрос может быть ограничен максимальным количеством символов или количеством записей в зависимости от настройки базы данных.
Для улучшения производительности рекомендуется использовать множественную вставку, когда необходимо добавить много записей. Однако, если вставка данных происходит в таблицу с ограничениями или триггерами, важно учитывать их поведение, чтобы избежать ошибок.
Также следует помнить, что базы данных могут иметь различия в поддержке синтаксиса множественной вставки. Например, MySQL и PostgreSQL поддерживают множественные значения в одном запросе, в то время как другие СУБД могут требовать использования нескольких команд INSERT INTO.
Синтаксис и примеры вставки нескольких строк
Для вставки нескольких строк в таблицу SQL можно использовать команду INSERT INTO с перечислением значений для каждой строки. Это позволяет значительно ускорить процесс добавления данных, особенно при работе с большими объемами информации.
Стандартный синтаксис для вставки нескольких строк выглядит следующим образом:
INSERT INTO таблица (колонка1, колонка2, колонка3)
VALUES
(значение1, значение2, значение3),
(значение4, значение5, значение6),
(значение7, значение8, значение9);Каждая строка данных обрабатывается в виде отдельного набора значений в скобках, разделенных запятыми. Важно соблюдать порядок значений, который должен соответствовать порядку колонок в таблице.
Пример для таблицы employees, где нужно вставить несколько записей:
INSERT INTO employees (first_name, last_name, age, department)
VALUES
('Иван', 'Иванов', 28, 'IT'),
('Петр', 'Петров', 34, 'HR'),
('Мария', 'Сидорова', 25, 'Marketing');Если данные, которые вставляются, не предполагают конкретных значений для всех колонок, можно пропустить их, если они допускают NULL значения или имеют дефолтные значения. Например:
INSERT INTO employees (first_name, last_name)
VALUES
('Алексей', 'Смирнов'),
('Ольга', 'Кузнецова');При этом для колонок age и department будет использоваться значение по умолчанию или NULL, если такие значения предусмотрены в схеме таблицы.
Этот метод вставки нескольких строк значительно повышает производительность по сравнению с многократными отдельными запросами INSERT.
Как обрабатывать ошибки при вставке нескольких значений
При вставке нескольких значений в таблицу SQL важно грамотно обрабатывать возможные ошибки, чтобы минимизировать потери данных и обеспечить стабильную работу приложения. Наиболее частые ошибки возникают из-за нарушения ограничений (например, уникальности или внешних ключей), недостатка прав доступа или неправильных данных в запросах.
Одним из популярных способов обработки ошибок является использование транзакций. Если вставка нескольких строк сопровождается ошибкой, транзакция может быть откатана, что предотвратит частичную вставку данных и сохранит целостность таблицы. Например, в MySQL можно использовать конструкцию START TRANSACTION для начала транзакции, а затем COMMIT для ее завершения. В случае ошибки используется ROLLBACK для отката изменений.
При вставке нескольких значений важно учитывать, что некоторые базы данных (например, PostgreSQL) могут игнорировать строки, нарушающие уникальные ограничения, если используется конструкция ON CONFLICT DO NOTHING. Это позволяет избежать ошибок, не нарушая целостности данных, однако не всегда бывает оптимально, если необходимо узнать, какие именно строки вызвали конфликты.
В случае работы с ошибками можно также использовать обработчики ошибок, чтобы отлавливать специфичные исключения, такие как IntegrityError в Python при работе с библиотеками, например, psycopg2 для PostgreSQL. В таких случаях можно обработать исключение, логировать ошибку или уведомлять пользователя о том, что не все данные были вставлены.
Важным аспектом является использование ограничений, таких как NOT NULL, CHECK или FOREIGN KEY, чтобы предотвратить вставку некорректных данных с самого начала. Однако, если ошибка все же произошла, важно предоставлять достаточно информации о том, какой именно столбец или строка вызвала проблему, чтобы упростить диагностику.
Для повышения производительности и уменьшения количества ошибок можно также использовать пакетные вставки с ограниченным количеством строк, чтобы при возникновении ошибки обработать только неудачные строки, не затрагивая остальные. В большинстве СУБД поддерживается возможность выполнения множества вставок за одну операцию с помощью конструкции INSERT INTO ... VALUES (...), (...), ..., что снижает нагрузку на сервер и ускоряет процесс.
Автоматическая генерация значений при вставке данных
Для автоматической генерации значений при вставке данных в таблицу SQL используются встроенные механизмы базы данных, такие как автоинкрементируемые поля и функции для генерации случайных или вычисляемых значений.
Одним из самых распространенных способов является использование свойства AUTO_INCREMENT для числовых столбцов. Это свойство автоматически увеличивает значение при каждом вставляемом ряду, что удобно для создания уникальных идентификаторов. Например, в MySQL для создания столбца с автоинкрементом достаточно указать следующее:
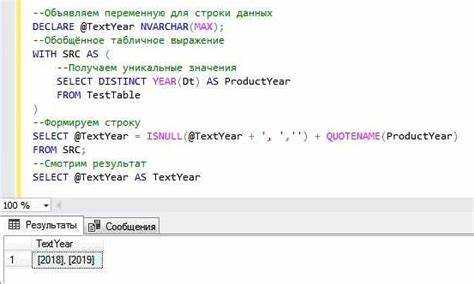
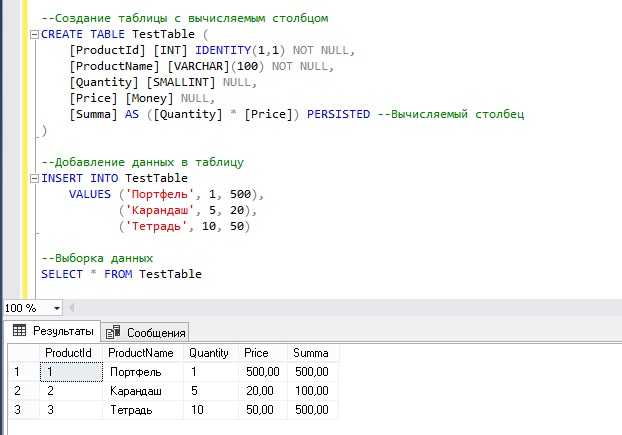
CREATE TABLE users (
id INT AUTO_INCREMENT,
name VARCHAR(255),
PRIMARY KEY (id)
);При вставке данных в таблицу, значение в поле id будет автоматически увеличиваться:
INSERT INTO users (name) VALUES ('Алексей');Другим примером автоматической генерации является использование функций для вычисления значений на основе других данных. Например, можно автоматически вставить текущую дату в столбец с помощью функции NOW():
INSERT INTO orders (order_date, user_id)
VALUES (NOW(), 1);Для генерации случайных значений можно использовать функции вроде RAND() в MySQL, которая возвращает случайное число. Это полезно, когда нужно автоматически вставить случайные данные в таблицу:
INSERT INTO products (name, price)
VALUES ('Продукт ' || FLOOR(RAND() * 100), FLOOR(RAND() * 100));В PostgreSQL аналогичная функция называется RANDOM(). Эти методы позволяют значительно ускорить процесс вставки данных, особенно в тестовых или больших объемах данных, где требуется случайный набор значений.
Не менее важным аспектом является использование генераторов UUID для создания уникальных идентификаторов в системах, где важно исключить риск коллизий. В PostgreSQL можно использовать встроенную функцию gen_random_uuid():
INSERT INTO users (id, name)
VALUES (gen_random_uuid(), 'Иван');Генерация значений на уровне базы данных помогает минимизировать ошибки и повысить производительность, особенно в случаях массовой вставки или при интеграции с другими системами, где важна автоматизация.
Вставка данных с использованием SELECT для выборки значений
Вставка данных в таблицу SQL с помощью SELECT-запроса позволяет добавить записи, извлекая информацию из других таблиц или представлений. Этот метод полезен, когда необходимо перенести данные из одной таблицы в другую или обновить существующие записи, основываясь на выборке.
Для выполнения такой операции используется конструкция INSERT INTO ... SELECT. Синтаксис выглядит следующим образом:
INSERT INTO target_table (column1, column2, ...)
SELECT column1, column2, ...
FROM source_table
WHERE condition;При этом важно соблюдать несколько правил:
- Соответствие типов данных: Количество и типы столбцов в
SELECTдолжны совпадать с теми, которые указаны вINSERT INTO. - Соответствие порядка столбцов: Порядок столбцов в SELECT должен точно соответствовать порядку столбцов в таблице назначения.
- Условия для выборки: Использование
WHEREпозволяет фильтровать данные, что полезно для выборки только нужных значений.
Пример простого запроса для вставки данных из одной таблицы в другую:
INSERT INTO employees_archive (id, name, position)
SELECT id, name, position
FROM employees
WHERE status = 'active';Этот запрос вставит все активные записи из таблицы employees в таблицу employees_archive. Убедитесь, что условия выборки WHERE status = 'active' применяются к данным, которые должны быть вставлены.
Иногда необходимо провести преобразование данных перед вставкой. Это можно сделать, например, с помощью функций SQL. Например, можно изменить формат даты или вычислить новые значения:
INSERT INTO sales_report (report_date, total_sales)
SELECT CURRENT_DATE, SUM(amount)
FROM transactions
WHERE transaction_date >= '2025-01-01'
GROUP BY product_id;В этом примере данные из таблицы transactions агрегируются с помощью SUM, и результат вставляется в таблицу sales_report.
Также возможно вставить данные из нескольких таблиц с использованием JOIN. Пример:
INSERT INTO order_summary (order_id, customer_name, total_amount)
SELECT o.id, c.name, SUM(oi.price * oi.quantity)
FROM orders o
JOIN customers c ON o.customer_id = c.id
JOIN order_items oi ON o.id = oi.order_id
GROUP BY o.id, c.name;В этом запросе данные о заказах, клиентах и товарах объединяются с помощью JOIN и агрегируются по сумме, после чего вставляются в таблицу order_summary.
Использование INSERT INTO ... SELECT является мощным инструментом для работы с данными в SQL, позволяя эффективно переносить и преобразовывать данные между таблицами.
Вставка данных с ограничениями на уникальность
Для создания такого ограничения используется конструкция CONSTRAINT UNIQUE при создании таблицы или при добавлении новых столбцов. Пример создания таблицы с ограничением на уникальность:
CREATE TABLE users (
id INT PRIMARY KEY,
email VARCHAR(255) UNIQUE
);В этом примере столбец email не может содержать повторяющиеся значения. Попытка вставить два одинаковых email приведет к ошибке.
При вставке данных, если значение в столбце, для которого установлено ограничение на уникальность, уже существует в базе, будет вызвана ошибка. Чтобы избежать таких ситуаций, можно использовать команду INSERT IGNORE или ON DUPLICATE KEY UPDATE (в зависимости от СУБД), чтобы обновить данные при нарушении уникальности:
INSERT INTO users (id, email)
VALUES (1, 'user@example.com')
ON DUPLICATE KEY UPDATE email='user@example.com';В случае с INSERT IGNORE операция вставки будет проигнорирована, если уникальность нарушена:
INSERT IGNORE INTO users (id, email)
VALUES (2, 'user@example.com');Особое внимание стоит уделить вставке нескольких значений за один запрос. Например, при использовании множества значений в одном запросе (через INSERT INTO … VALUES) SQL также будет проверять уникальность каждого значения в столбце с ограничением:
INSERT INTO users (id, email)
VALUES
(3, 'newuser@example.com'),
(4, 'user@example.com');Если второе значение повторяет существующее в таблице, возникнет ошибка из-за нарушения уникальности. Для обработки таких ситуаций можно снова использовать ON DUPLICATE KEY UPDATE или предварительно проверить данные на дубликаты перед вставкой.
При работе с большими объемами данных важно учитывать, что вставка с нарушением уникальности может повлиять на производительность. В таких случаях рекомендуется использовать индексы для столбцов с ограничениями на уникальность, чтобы ускорить проверку дубликатов.