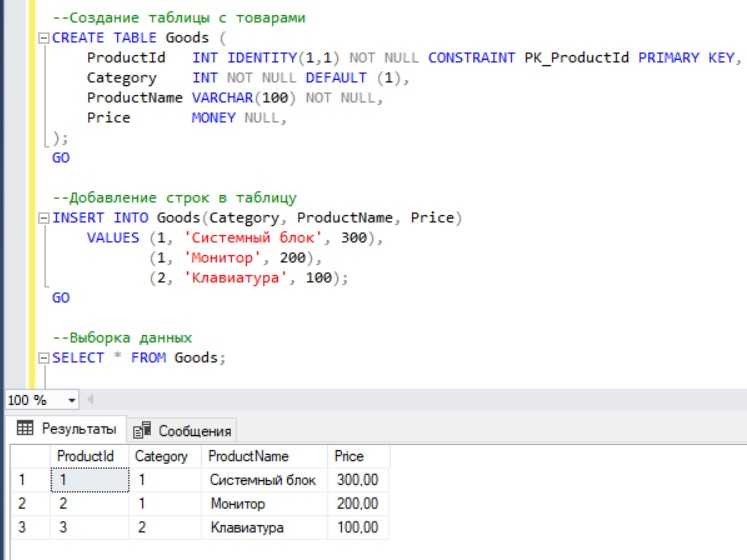
Сокрытие данных в базе данных – это не только задача безопасности, но и необходимость оптимизации работы с большими таблицами. Когда таблица достигает значительных размеров, становится сложно эффективно управлять ею, не потеряв производительность или доступность информации. Методы сокрытия позволяют снизить нагрузку на систему и сделать работу с такими таблицами более управляемой. Одним из наиболее популярных подходов является использование разделения таблицы (partitioning).
Разделение данных на части с помощью партиционирования позволяет снизить нагрузку на сервер, ускорить выполнение запросов и упростить администрирование. В зависимости от объема данных и используемой СУБД, можно применять различные виды партиционирования: по диапазону значений, по списку значений или по хеш-функции. Каждое из этих решений требует тщательной настройки индексов и поддержания целостности данных, что значительно повышает общую производительность системы.
Другим методом является использование шардирования, которое разделяет таблицу на несколько физически независимых частей, распределённых по различным серверам или экземплярам базы данных. Это позволяет не только скрывать данные, но и масштабировать систему, улучшая её отказоустойчивость. Шардирование, однако, требует высококвалифицированного подхода к проектированию и управления, чтобы избежать проблем с целостностью данных и сложностями при выполнении сложных запросов.
Для сокрытия данных на уровне доступности можно использовать механизмы обфускации или шифрования, которые изменяют или скрывают содержимое таблицы для тех пользователей, которые не имеют нужных прав. Это позволяет защитить чувствительную информацию, оставаясь при этом в рамках действующих стандартов безопасности и производительности.
Каждый из этих методов имеет свои особенности и ограничения, которые должны учитываться при проектировании архитектуры базы данных. При выборе подхода важно учитывать как требования безопасности, так и ожидания от производительности системы.
Использование шифрования данных для скрытия таблицы
Шифрование данных – эффективный метод защиты информации в базе данных и сокрытия ее от несанкционированного доступа. Для защиты таблиц от взлома или утечек, шифрование может быть использовано на уровне столбцов или всей таблицы.
При шифровании данных важен выбор алгоритма, который обеспечивает необходимый баланс между безопасностью и производительностью. Одним из наиболее популярных решений является использование симметричных и асимметричных алгоритмов шифрования.
- Симметричное шифрование (например, AES) предполагает использование одного ключа для шифрования и дешифрования данных. Оно обеспечивает высокую скорость обработки, но требует надежного управления ключами, так как утечка ключа может привести к компрометации данных.
- Асимметричное шифрование (например, RSA) использует пару ключей – публичный и приватный. Это решение менее эффективно с точки зрения производительности для больших объемов данных, но оно предоставляет высокий уровень безопасности при передаче данных между различными узлами.
Для защиты целых таблиц, данные могут быть зашифрованы прямо в процессе их записи. Например, шифрование осуществляется на уровне приложений, прежде чем данные будут записаны в базу. В случае чтения, данные извлекаются и дешифруются только в приложении.
Для баз данных, поддерживающих встроенные механизмы шифрования, например, MySQL или PostgreSQL, существуют решения, которые позволяют шифровать данные непосредственно на уровне движка базы данных, без необходимости дополнительного вмешательства в приложение.
Рекомендации по внедрению шифрования
- Используйте шифрование на уровне таблиц для защиты чувствительных данных (например, персональных данных или финансовой информации).
- Для высоко нагруженных систем выбирайте алгоритмы с минимальным временем обработки данных, такие как AES-256.
- Не храните ключи шифрования в тех же местах, где хранятся зашифрованные данные. Используйте специализированные хранилища для ключей (например, HashiCorp Vault).
- Регулярно меняйте ключи шифрования, чтобы минимизировать риски, связанные с их возможной утечкой.
- Тестируйте производительность системы до и после внедрения шифрования, чтобы оценить влияние на скорость выполнения запросов.
Шифрование данных является одним из самых надежных методов защиты данных от взлома, но требует тщательной настройки и учета всех возможных рисков, связанных с управлением ключами и производительностью системы.
Настройка прав доступа для ограниченного отображения таблицы
Для обеспечения безопасности и предотвращения несанкционированного доступа к данным в базе данных важно правильно настроить права доступа. В SQL-системах это можно сделать с помощью ролевой модели управления доступом, назначения гранулярных прав на уровне объектов базы данных и использования механизмов фильтрации данных.
Основной принцип при настройке прав доступа – принцип наименьших привилегий. Пользователи и приложения должны иметь доступ только к тем данным, которые необходимы для их работы. Для этого можно использовать следующие методы:
1. Создание ролей с ограниченными правами
Роли в базе данных помогают управлять правами доступа. Создание роли с ограниченными правами позволяет назначать пользователям конкретный доступ к таблицам. Например, роль может иметь доступ только к чтению определённых колонок таблицы или только к строкам, соответствующим определённым критериям. Для этого в SQL можно использовать команду GRANT с указанием ограничений по доступу.
2. Применение представлений (views)
Использование представлений – эффективный способ сокрытия части данных. Создавая представление, можно ограничить доступ к определённым столбцам или строкам таблицы. Представление действует как виртуальная таблица, которая отображает только те данные, которые разрешены для пользователя. Например, представление может содержать только данные о клиентах из конкретного региона или только тех клиентов, чьи данные не являются конфиденциальными.
Пример создания представления:
CREATE VIEW limited_customers AS
SELECT customer_id, name, region
FROM customers
WHERE region = 'Moscow';Данный запрос создает представление, которое будет доступно только для пользователей, имеющих права на его использование, и будет содержать лишь ограниченные данные.
3. Использование фильтрации строк на уровне базы данных
Для дополнительного ограничения доступа можно применить механизмы фильтрации строк через политики безопасности (например, с помощью функций или триггеров). Это позволяет автоматически ограничить доступ к данным в зависимости от роли или других факторов, таких как IP-адрес или время суток. Например, можно создать триггер, который будет скрывать определённые строки в таблице в зависимости от текущей роли пользователя.
4. Применение оконных функций для сокрытия данных
Оконные функции позволяют работать с подмножествами данных, обеспечивая доступ только к нужным строкам на основе контекста пользователя. Например, используя оконную функцию ROW_NUMBER, можно скрывать определённые записи, возвращая только те, которые удовлетворяют заранее заданным условиям.
5. Ручное управление правами доступа с использованием команд GRANT и REVOKE
Для контроля доступа на уровне столбцов и строк можно использовать команды GRANT и REVOKE. Они позволяют назначать и отбирать права доступа на уровне базы данных. Команда GRANT позволяет предоставлять доступ, например, только к чтению определённых столбцов, а команда REVOKE – отзывать эти права. Важно детально прописывать права для каждой роли, чтобы исключить возможность лишнего доступа.
Пример команды GRANT для предоставления прав на чтение только определённой колонки:
GRANT SELECT (name, region) ON customers TO user_role;6. Мониторинг доступа и аудит
Не менее важной частью управления доступом является мониторинг и аудит. Регулярное отслеживание запросов и действий пользователей позволяет оперативно выявлять попытки несанкционированного доступа или аномальные операции. Использование встроенных механизмов аудита в СУБД или сторонних решений поможет контролировать, кто и какие данные просматривает или изменяет.
Применяя все эти методы в сочетании, можно эффективно скрывать часть данных в таблицах и обеспечивать безопасность, сохраняя при этом необходимую гибкость в управлении доступом.
Применение маскировки данных для защиты содержимого таблицы
Маскировка данных представляет собой метод скрытия реальных значений в базе данных путем их преобразования в нечитабельный вид. Это позволяет защитить конфиденциальность данных, обеспечивая при этом доступ к частичной информации для пользователей и приложений. Применение маскировки данных в SQL таблицах эффективно снижает риски утечек и несанкционированного доступа при работе с чувствительными данными.
Маскировка данных может быть реализована несколькими способами в зависимости от требований безопасности и типа данных. Одним из основных методов является использование SQL-функций для замены или сокрытия данных на уровне запросов. Например, для сокрытия части значений телефонных номеров или номеров карт можно использовать функции, которые отображают только последние цифры, скрывая остальные. Это позволяет работать с данными, не раскрывая их полностью.
Функции маскировки в SQL часто предоставляются базой данных в виде встроенных инструментов. Например, в PostgreSQL можно использовать функцию pgcrypto, которая позволяет шифровать и дешифровать данные. В SQL Server аналогичные возможности предоставляет MASKED, с помощью которого можно настроить маски для различных типов данных, таких как email-адреса, номера кредитных карт или ИНН.
Для защиты данных на уровне таблицы можно применить маскировку на уровне столбцов. Это позволяет управлять доступом, показывая пользователю только разрешенную информацию. Например, в случае с персональными данными можно скрыть полные фамилии и имена, заменив их на псевдонимы или сокращения.
Важно учитывать, что маскировка данных не заменяет полноценное шифрование, поскольку она не предоставляет обратного пути для восстановления исходных значений. Поэтому данный метод используется в сочетании с другими мерами безопасности для обеспечения комплексной защиты данных.
Одним из эффективных способов маскировки является создание специализированных представлений (views), которые могут фильтровать и скрывать данные, оставляя только нужные атрибуты. Это подход особенно полезен в многопользовательских системах, где разные группы пользователей могут иметь доступ только к части информации.
Для увеличения гибкости маскировки данных можно использовать динамическую маскировку, которая позволяет настроить маски в зависимости от контекста запроса или ролей пользователей. Например, в системах, где разные сотрудники должны видеть разные уровни подробности данных, динамическая маскировка помогает обеспечить баланс между доступом и конфиденциальностью.
Создание представлений для скрытия реальных данных
Для создания представлений, скрывающих реальные данные, часто используются несколько подходов. Один из них – использование фильтрации и агрегации данных в представлении. Например, можно создать представление, которое ограничивает доступ к личной информации пользователей, оставляя только анонимизированные данные, такие как идентификатор пользователя, возраст или общее количество заказов, без указания фамилии или адреса. В этом случае запрос к данным будет возвращать только те столбцы, которые необходимы для работы конкретного пользователя или роли.
Также, представления могут быть использованы для выполнения преобразований данных. Например, можно объединить несколько таблиц в одно представление, скрывая избыточные или чувствительные данные, оставляя только ключевые значения. Например, объединяя таблицы с информацией о заказах и клиентах, представление может скрыть персональные данные клиента, но оставить информацию о суммах заказов или товарах, что делает данные доступными для анализа без риска утечек.
Еще одна важная техника – это использование представлений для ограничения доступа на уровне строк. Это можно достичь путем добавления условий в запросы представлений, таких как фильтрация по роли или уровню доступа пользователя. Например, сотрудник, работающий с заказами, может видеть только заказы из своего региона, в то время как руководитель – все заказы. Такая гранулярность доступа позволяет эффективно защищать данные от несанкционированного просмотра и обеспечения соответствия правилам безопасности.
Стоит отметить, что представления не защищают данные от прямого доступа. Если у пользователя есть права на доступ к таблицам, он может создать запрос, который будет напрямую обращаться к данным, минуя представления. Поэтому важно правильно настроить права доступа и ограничивать возможность создания и использования представлений только для определённых ролей.
Для улучшения производительности при работе с большими объемами данных, можно использовать материализованные представления. Эти объекты представляют собой сохранённые результаты запроса, что позволяет сократить время выполнения запросов, но в этом случае важно учитывать актуальность данных, поскольку материализованные представления не обновляются автоматически.
Использование аудита и журналирования для отслеживания доступа к таблице
Для отслеживания доступа к критически важной SQL-таблице необходимо включить детализированный аудит с фиксацией операций SELECT, INSERT, UPDATE и DELETE. В PostgreSQL это реализуется через расширение pgaudit, позволяющее логировать каждый запрос с указанием пользователя, времени и текста SQL-запроса. В Oracle используется AUDIT с возможностью фильтрации по конкретной таблице и типу действия.
В MySQL начиная с версии 5.6 доступно подключаемое аудиторское расширение AUDIT_PLUGIN, где можно настроить логирование по шаблонам событий. Необходимо явно указывать отслеживаемые команды, чтобы избежать перегрузки логов нерелевантными данными. Например, логировать только действия над таблицей transactions и игнорировать остальные запросы.
Формат журналирования должен быть структурирован: JSON или CSV с обязательными полями – имя пользователя, IP-адрес клиента, timestamp, операция, идентификатор сессии, а также текст запроса. Это позволяет эффективно анализировать активность с помощью SIEM-систем или собственных скриптов на Python с использованием регулярных выражений.
Важно настраивать ротацию журналов и ограничивать доступ к ним на уровне файловой системы. Логи должны храниться минимум 90 дней, а для финансовых или персональных данных – не менее 180. Также рекомендуется настроить автоматическое оповещение при попытке доступа к таблице вне регламентных окон или с неизвестных IP-адресов.
Для повышения уровня защиты используйте контроль целостности логов: контрольные суммы, цифровые подписи, или централизованную передачу логов через syslog на внешние защищённые хранилища, недоступные для серверной БД. Это предотвращает возможность их подмены злоумышленником при компрометации сервера.
Инкапсуляция данных через хранимые процедуры
Хранимые процедуры позволяют ограничить прямой доступ к таблицам, предоставляя интерфейс строго определённого функционала. Это критически важно при необходимости сокрытия крупной таблицы, содержащей чувствительные или структурно сложные данные.
Вместо выдачи прав на чтение таблицы, предоставляются права только на выполнение процедур. Пользователи получают доступ к данным строго в рамках предусмотренной логики: фильтрация, агрегация, валидация. Любые попытки обойти процедуру исключаются на уровне прав доступа.
Пример: вместо SELECT к таблице transactions, создаётся процедура get_user_transactions(@user_id), возвращающая только записи, соответствующие пользователю. Даже при знании имени таблицы, сторонний пользователь не может получить к ней доступ напрямую.
Хранимые процедуры облегчают контроль версий: при изменении структуры таблицы логика обращения к данным остаётся стабильной. Это минимизирует необходимость изменения клиентского кода, снижает риски утечек и ошибок при миграциях.
Рекомендация: использовать только процедуры с параметризованными входами, исключив SQL-инъекции. Запретить SELECT, INSERT, UPDATE, DELETE напрямую для пользователей. Все операции – только через процедуры.
Для дополнительной защиты можно внедрить проверку ролей внутри процедуры, контролируя бизнес-логику доступа. Это повышает уровень сокрытия данных даже в случае компрометации прав пользователя на выполнение процедуры.
Разделение таблицы на несколько частей для повышения конфиденциальности

Разделение одной SQL-таблицы на логически изолированные сегменты – эффективная стратегия для минимизации рисков утечки данных. Метод подразумевает физическое или логическое разнесение информации по нескольким таблицам с разными уровнями доступа.
- Декомпозиция по чувствительности: данные делятся по критериям конфиденциальности. Например, ФИО и контактные данные размещаются отдельно от паспортной информации и идентификаторов.
- Создание вспомогательных таблиц: вместо хранения всех атрибутов в одной таблице, данные распределяются на узкие таблицы, соединяемые по внешним ключам только при необходимости.
- Изоляция по функциональным доменам: данные сегментируются в зависимости от бизнес-логики: учетная информация, платежные данные, логи активности – каждая категория в отдельной таблице с отдельным набором политик доступа.
- Техническая реализация: рекомендуется использовать представления (VIEW) с ограничением видимых столбцов и строк, триггеры для логирования доступа и политики row-level security (RLS), доступные, например, в PostgreSQL.
Разделение таблицы усложняет несанкционированный доступ к полной информации, повышает управляемость правами доступа и снижает последствия потенциальных утечек. При правильной архитектуре можно обеспечить доступ к строго необходимым данным, не раскрывая полную структуру объекта.
Вопрос-ответ:
Можно ли скрыть таблицу от обычных пользователей, но оставить доступ администраторам?
Да, такая возможность существует. Обычно для этого применяют разграничение прав доступа с помощью систем управления ролями. В большинстве СУБД можно создать отдельную роль для администраторов и ограничить доступ к таблице для всех остальных ролей. Кроме того, можно использовать представления (view), которые не включают нужную таблицу, и выдавать доступ только к ним. Это позволяет контролировать, какие данные видят конкретные пользователи, не удаляя саму таблицу из базы.
Какие методы позволяют сделать таблицу «невидимой», не нарушая работу других частей приложения?
Для скрытия таблицы можно использовать несколько подходов. Один из самых распространённых — использование представлений и ограничение прав на прямой доступ к таблице. Также можно задействовать схемы: переместить таблицу в другую схему и ограничить к ней доступ. Ещё один способ — зашифровать содержимое таблицы, при этом предоставляя расшифровку только при выполнении определённых условий или авторизации. При правильно настроенных ограничениях приложение продолжает функционировать, используя лишь те данные, которые доступны через интерфейсы или представления.
Есть ли способ спрятать таблицу полностью, чтобы её нельзя было обнаружить даже с помощью SQL-запросов к системным таблицам?
Это более сложная задача. В большинстве стандартных СУБД пользователи с расширенными правами всё равно могут получить список всех таблиц, включая те, доступ к которым у них отсутствует. Однако можно попробовать обойти это, комбинируя ограничение прав, использование нестандартных схем именования и перемещение таблицы в отдельную схему с ограниченным доступом. Также существует практика использования обфускации — переименования таблиц и колонок в ничего не значащие имена, чтобы усложнить их идентификацию при обходе метаданных.
Может ли скрытие таблицы повлиять на производительность запросов?
Да, в некоторых случаях это возможно. Например, если используется сложная логика через представления или фильтрация на уровне строк (row-level security), то каждый запрос к таблице будет дополнительно обрабатываться. Это может вызвать увеличение времени выполнения запросов. Однако при грамотной настройке индексов и продуманной архитектуре базы такие потери можно минимизировать. Важно протестировать изменения перед внедрением на рабочем окружении.