Чувствительность к регистру в JavaScript означает, что идентификаторы, такие как переменные, функции, и имена объектов, различаются в зависимости от прописных и строчных букв. Это важная особенность, которая требует внимательности при написании кода. Например, переменные userName и username будут восприниматься как разные, даже если они представляют одно и то же понятие. Такой подход широко используется в JavaScript и является стандартом в большинстве современных языков программирования.
Этот принцип затрудняет использование имен, которые могут быть схожи по написанию, но различаются только регистром букв. Важно учитывать, что JavaScript различает не только переменные, но и ключевые слова, методы и даже свойства объектов. Например, доступ к свойствам объекта person через person.age и person.Age приведет к разным результатам, если они существуют по-разному. Это следует учитывать при проектировании именования в приложениях.
В практике разработки важно придерживаться консистентности в использовании регистра букв, чтобы избежать трудностей в отладке и поддержке кода. Рекомендуется выбирать четкие правила именования, такие как использование camelCase для переменных и функций, чтобы минимизировать риск ошибок, связанных с регистром.
Как регистр влияет на идентификаторы переменных в JavaScript
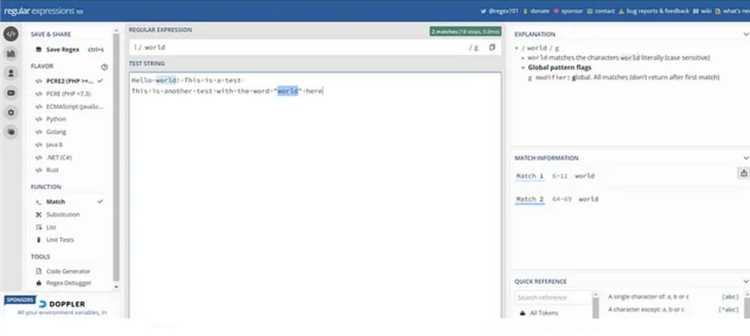
В JavaScript чувствительность к регистру имеет большое значение для идентификаторов переменных. Идентификаторы, такие как имена переменных, функций или классов, различаются не только по содержимому, но и по регистру символов. Например, переменные variable и Variable будут восприниматься как два разных объекта, даже если они содержат одинаковые символы, но имеют разные регистры.
Это означает, что при объявлении переменных необходимо строго соблюдать правила написания: даже небольшое изменение в регистре (например, использование заглавной буквы вместо строчной) приведет к созданию новой переменной. Пример:
let example = 10; let Example = 20; console.log(example); // 10 console.log(Example); // 20
В данном случае переменные example и Example существуют одновременно и хранят разные значения. Это поведение важно учитывать при работе с большими кодовыми базами, где возможно случайное использование одинаковых имен с различием в регистре.
Кроме того, использование разных регистров может привести к ошибкам, которые трудно обнаружить, особенно при взаимодействии с внешними библиотеками или API, где регистр часто имеет значение. Рекомендуется придерживаться конвенций именования, чтобы минимизировать риск подобных ошибок.
Важно помнить, что регистр также влияет на ключевые слова языка. Например, let и Let – это два разных идентификатора, но Let не является зарезервированным словом, и его можно использовать для создания переменной, в то время как let является ключевым словом, и попытка его использования в качестве имени переменной вызовет ошибку.
Для упрощения работы с кодом, особенно в крупных проектах, рекомендуется использовать единый стиль написания идентификаторов, например, camelCase для переменных и функций, и PascalCase для классов, что помогает избежать путаницы при чтении и поддержке кода.
Различие между строками с разным регистром: примеры и поведение

В JavaScript строки чувствительны к регистру. Это означает, что «abc» и «ABC» воспринимаются как два разных значения. При сравнении строк, символы в верхнем и нижнем регистре считаются различными. Рассмотрим несколько примеров для наглядности.
Пример 1:
let str1 = "Hello"; let str2 = "hello"; console.log(str1 === str2); // false
В этом примере строка «Hello» не равна строке «hello» из-за различия в регистре первой буквы. Оператор строгого сравнения (===) проверяет и регистр, и содержимое строк.
Пример 2:
let str1 = "JavaScript"; let str2 = "javascript"; console.log(str1 === str2); // false
Здесь строки «JavaScript» и «javascript» также не равны, потому что JavaScript различает регистры символов в строках.
Если требуется сравнение без учета регистра, можно использовать методы, которые нормализуют регистр строк. Например, метод toLowerCase() или toUpperCase().
Пример 3:
let str1 = "Hello"; let str2 = "hello"; console.log(str1.toLowerCase() === str2.toLowerCase()); // true
В этом примере строки приводятся к одному регистру с помощью toLowerCase(), и результат сравнения становится истинным.
Еще один пример использования:
let str1 = "JavaScript"; let str2 = "JAVASCRIPT"; console.log(str1.toLowerCase() === str2.toLowerCase()); // true
Таким образом, для строк с разным регистром, чтобы провести их сравнение без учета регистра, важно привести обе строки к одному регистру. Это улучшает гибкость кода, особенно при работе с пользовательскими данными.
Также стоит отметить, что методы для изменения регистра могут быть полезны при поиске или фильтрации данных в строках, например:
let str = "Hello World";
console.log(str.toUpperCase().includes("WORLD")); // true
В этом примере метод toUpperCase() преобразует строку в верхний регистр перед поиском подстроки. Это гарантирует, что поиск будет нечувствителен к регистру.
Таким образом, при работе со строками важно учитывать их регистр. Использование методов для нормализации регистра является стандартной практикой для предотвращения ошибок при сравнении и поиске строк с разным регистром.
Проблемы при сравнении строк с разным регистром в JavaScript
В JavaScript строки чувствительны к регистру. Это означает, что сравнение строк с разными регистрами, например, «abc» и «ABC», всегда вернёт результат «false». Это может стать проблемой, когда необходимо провести сравнение без учета регистра символов, например, при поиске совпадений в пользовательском вводе или при валидации данных.
Одной из распространённых проблем является использование оператора строгого равенства (===), который не учитывает различия между строками с разным регистром. Для решения этой проблемы можно привести обе строки к одному регистру, например, используя методы toLowerCase() или toUpperCase(). Однако важно помнить, что эти методы могут привести к неожиданным результатам, если строки содержат символы, чье представление в разных регистрах отличается, например, в некоторых языках или алфавитах.
При использовании метода toLowerCase() для приведения строк к нижнему регистру следует учитывать локализацию, так как правила преобразования могут различаться в разных языках. Для более корректного сравнения строк в таких случаях стоит использовать localeCompare(), который поддерживает локализацию и позволяет учитывать правила языка при сравнении строк.
Кроме того, если задача заключается в сравнении строк, введённых пользователем, важно понимать, что чувствительность к регистру может вызвать трудности, особенно при проверке паролей или электронных почтовых адресов, где такой подход может быть нежелательным. Например, для паролей можно использовать метод приведения к одному регистру, но для email-адресов это делать не рекомендуется, поскольку большинство почтовых сервисов не чувствительны к регистру в адресах, но могут отличаться по доменам.
Для работы с такими случаями лучше применять методы, которые предоставляют более гибкие настройки для сравнения строк в зависимости от контекста задачи, что позволит избежать ошибок при обработке данных.
Как правильно использовать методы для работы с чувствительностью к регистру

В JavaScript методы работы с строками по умолчанию чувствительны к регистру. Это означает, что символы в верхнем и нижнем регистре воспринимаются как разные. Для правильной работы с чувствительностью к регистру следует учитывать несколько аспектов при использовании строковых методов.
- Методы сравнения строк: Например, метод
String.prototype.includes()не игнорирует регистр символов. Если нужно выполнить нечувствительное к регистру сравнение, рекомендуется использовать методы, которые приводят обе строки к одному регистру перед сравнением, например, с помощьюtoLowerCase()илиtoUpperCase(). - Использование
toLowerCase()иtoUpperCase(): Эти методы позволяют привести строки к одному регистру для упрощенного сравнения. Например, чтобы сравнить строки, игнорируя регистр, можно выполнить следующее:
let str1 = 'Hello';
let str2 = 'hello';
console.log(str1.toLowerCase() === str2.toLowerCase()); // true
- Регулярные выражения: Для работы с нечувствительным к регистру поиском используется флаг
i. Пример использования регулярных выражений для поиска без учета регистра:
let regex = /hello/i;
console.log(regex.test('Hello')); // true
console.log(regex.test('HELLO')); // true
- Метод
replace()с регистронезависимостью: Важно помнить, что методreplace()также чувствителен к регистру. Чтобы заменить все вхождения строки без учета регистра, используется флагiв регулярном выражении:
let text = 'Hello world';
let newText = text.replace(/hello/i, 'Hi');
console.log(newText); // Hi world
- Метод
match()с флагомi: Для поиска подстроки в строках с игнорированием регистра также применяется флагi.
let str = 'JavaScript';
let result = str.match(/javascript/i);
console.log(result[0]); // JavaScript
Важно помнить, что игнорирование регистра полезно, когда нужно работать с вводом пользователя или данными, где регистр символов может варьироваться. Использование таких методов, как toLowerCase() или флагов в регулярных выражениях, позволяет сделать код более гибким и удобным для пользователя.
Решения для игнорирования регистра при поиске в строках
В JavaScript для выполнения поиска по строкам с игнорированием регистра можно использовать несколько подходов. Рассмотрим наиболее распространенные методы, которые позволяют избежать ошибок при сравнении строк с разным регистром символов.
Использование метода toLowerCase() или toUpperCase()
Один из самых простых способов – привести обе строки (и исходную, и строку поиска) к одному регистру. Для этого используют методы toLowerCase() или toUpperCase(). Это гарантирует, что поиск будет осуществляться без учета регистра символов.
Пример:
let str = "Hello World!";
let searchTerm = "hello";
let isMatch = str.toLowerCase().includes(searchTerm.toLowerCase());Этот метод подходит для большинства случаев, но следует учитывать, что он может быть менее эффективным при работе с большими объемами данных из-за необходимости создания новых строк в памяти.
Использование регулярных выражений
Регулярные выражения с флагом i позволяют игнорировать регистр символов при поиске. Это решение более компактное и мощное, особенно для сложных условий поиска.
Пример:
let str = "Hello World!";
let searchTerm = "hello";
let regex = new RegExp(searchTerm, "i");
let isMatch = regex.test(str);Такой подход удобен для более сложных задач, включая использование различных шаблонов поиска, но может быть менее читабельным для новичков.
Метод localeCompare()
Для более точного сравнения строк с учётом локали можно использовать метод localeCompare(). Он сравнивает строки с учётом их локализации и регистра. Если необходимо игнорировать регистр, можно передать опцию sensitivity: 'base'.
Пример:
let str1 = "Hello";
let str2 = "hello";
let result = str1.localeCompare(str2, undefined, { sensitivity: 'base' });Этот метод полезен, когда нужно учесть локализацию при поиске, что может быть важным в международных приложениях.
Использование встроенных методов String.prototype.match() и String.prototype.search()
Методы match() и search() с флагом i позволяют выполнить поиск по строке с игнорированием регистра. Эти методы часто используются, если необходимо найти первое совпадение в строке.
Пример:
let str = "Hello World!";
let searchTerm = "hello";
let isMatch = str.match(new RegExp(searchTerm, 'i')); // Возвращает массив совпадений или nullЗаключение
Выбор метода зависит от конкретной задачи. Для простых случаев можно использовать методы toLowerCase() или toUpperCase(), а для более сложных – регулярные выражения с флагом i или localeCompare() с настройками локализации. Каждое решение имеет свои плюсы и минусы, и важно выбирать подходящий инструмент в зависимости от размера данных, требований к производительности и точности поиска.
Что происходит с именами функций и методов в зависимости от регистра
В JavaScript имена функций и методов чувствительны к регистру, что означает, что функции с одинаковым набором символов, но разным регистром, считаются разными. Это важный аспект, который может повлиять на правильность работы программы, если не следить за регистрами букв в именах.
Например, в случае объявления функций:
function myFunction() { ... }
function MyFunction() { ... }Здесь myFunction и MyFunction будут рассматриваться как две разные функции. Если в коде используется myFunction, а фактически объявлена MyFunction, то произойдёт ошибка, так как JavaScript не сможет найти нужную функцию из-за различия в регистре букв.
Также стоит учитывать, что методы объектов работают по тому же принципу. Рассмотрим следующий пример:
const obj = {
someMethod() { ... },
SomeMethod() { ... }
}В данном случае someMethod и SomeMethod будут восприниматься как два разных метода, и попытка вызова метода с неверным регистром приведет к ошибке.
Рекомендация: Всегда следите за правильным использованием регистра букв при вызове функций и методов. Это помогает избежать ошибок, связанных с несуществующими именами, особенно в больших проектах с множеством разных функций.
Особое внимание стоит уделить: стандартам именования, принятым в проекте. Например, в JavaScript часто используется стиль camelCase для функций и методов, при котором первая буква маленькая, а каждая последующая – заглавная. Нарушение этого стиля может привести к путанице и ошибкам.
Как JavaScript обрабатывает чувствительность к регистру в массивах и объектах
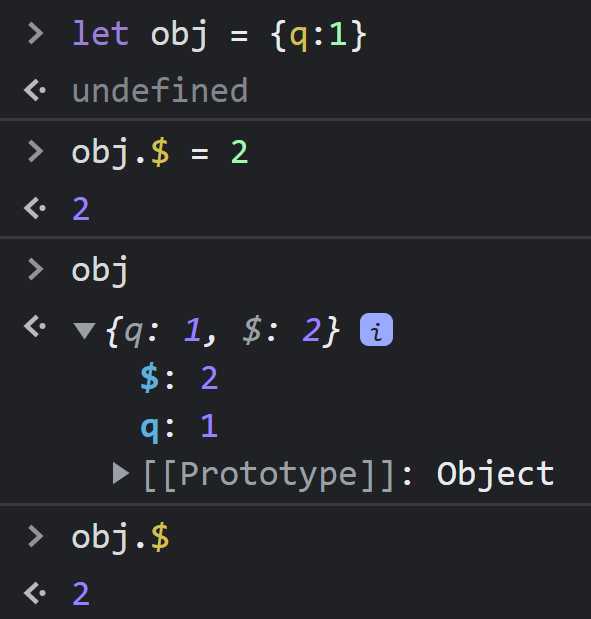
В JavaScript регистр символов играет важную роль при работе как с массивами, так и с объектами. Примеры различий в обработке чувствительности к регистру можно встретить при доступе к элементам массива и свойствам объектов. Для начала важно понимать, что в языке JavaScript переменные, массивы и объекты рассматриваются как чувствительные к регистру.
При работе с массивами чувствительность к регистру проявляется при индексации элементов. Индексы массива, как и переменные, имеют точное соответствие символов. Например, массив, созданный с элементами ‘a’, ‘B’ и ‘c’, будет рассматриваться как массив с тремя элементами, где ‘a’ и ‘A’ – это два различных значения. Это означает, что попытка доступа к массиву через индекс, отличающийся по регистру от исходного, приведет к ошибке или возврату неопределённого значения.
Пример с массивом:
let arr = ['a', 'B', 'c']; console.log(arr[0]); // 'a' console.log(arr[1]); // 'B' console.log(arr['a']); // undefined
В случае с объектами чувствительность к регистру аналогична. Свойства объекта с разным регистром символов считаются отдельными свойствами. Это важно при определении ключей для объектов. Например, если задать два свойства с ключами, отличающимися только регистром, они будут восприниматься как разные. При обращении к таким свойствам также нужно учитывать точный регистр символов.
Пример с объектом:
let obj = { "name": "John", "Name": "Doe" };
console.log(obj.name); // 'John'
console.log(obj.Name); // 'Doe'
console.log(obj.name === obj.Name); // false
Часто при работе с объектами и массивами возникает необходимость проверять существование элементов с учетом регистра. Если необходимо игнорировать регистр, можно применить методы, преобразующие строку в нижний или верхний регистр, например, `toLowerCase()` или `toUpperCase()`. Это позволяет сравнивать строки без учета их начальной формы.
Пример игнорирования регистра при поиске в объекте:
let obj = { "name": "John", "Name": "Doe" };
let searchKey = "NAME".toLowerCase();
console.log(obj[searchKey]); // 'Doe'
Рекомендация: всегда проверяйте регистр при обращении к свойствам объектов или элементам массива, чтобы избежать ошибок, связанных с неправильным доступом. В большинстве случаев, если требуется работать с данными без учёта регистра, используйте методы для нормализации данных, приводя их к единому формату.
Какие инструменты и библиотеки помогают работать с регистрами строк

Работа с регистрами строк в JavaScript – важная задача, особенно когда требуется манипулировать текстом в разных форматах. Для упрощения работы с такими операциями существуют разнообразные инструменты и библиотеки, которые значительно повышают производительность и удобство программирования.
Рассмотрим несколько популярных вариантов.
- String.prototype.toLowerCase() и String.prototype.toUpperCase() – стандартные методы JavaScript, которые позволяют преобразовывать строки в нижний или верхний регистр. Эти методы просты и эффективны, но они не позволяют работать с локалями и могут быть недостаточны в некоторых случаях.
- Intl.Collator – встроенный объект для сравнения строк с учетом локализации. Он позволяет корректно работать с регистрами в разных языках и культурных контекстах. Использование
Intl.Collatorпозволяет избежать проблем с сортировкой и сравнением строк в различных регистрах. - lodash – библиотека с множеством полезных утилит, включая методы для работы с регистрами строк. Например,
_.capitalize()делает первую букву строки заглавной, а остальную – строчной, что удобно при форматировании текстовых данных. - underscore.string – еще одна библиотека, расширяющая возможности работы со строками. Она включает методы для трансформации регистра, такие как
_.capitalize(),_.camelize()и другие, что полезно при обработке данных, поступающих из разных источников. - string.prototype.trim() – метод для удаления пробелов в начале и в конце строки, часто используемый в комбинации с методами изменения регистра. Важно отметить, что он может быть полезен при очистке строк перед изменением их регистра.
- case – библиотека, предоставляющая функции для работы с разными регистрами строк, такими как
case.sentence()илиcase.title(), которые позволяют преобразовывать строки в стиль предложения или заголовка соответственно. Это особенно полезно при генерации текстов для UI.
Использование этих инструментов и библиотек помогает не только сэкономить время на реализации стандартных операций, но и гарантирует, что ваша программа будет работать корректно с учетом всех нюансов локалей и форматов. Выбор конкретного инструмента зависит от задачи: для простых преобразований часто достаточно встроенных методов JavaScript, а для более сложных случаев, связанных с локализацией или стилем текста, стоит обратить внимание на внешние библиотеки.
Вопрос-ответ:
Что значит чувствительность к регистру в JavaScript?
Чувствительность к регистру в JavaScript означает, что язык различает символы в верхнем и нижнем регистрах. Например, переменная с именем «variable» будет отличаться от переменной с именем «Variable». Это важно учитывать при работе с именами переменных, функциями и другими элементами кода, чтобы избежать ошибок.
Какие элементы в JavaScript чувствительны к регистру?
В JavaScript чувствительность к регистру распространяется на все идентификаторы, такие как переменные, функции, классы и свойства объектов. Например, функция «myFunction» и «MyFunction» будут восприниматься как две разные функции, так как регистр букв имеет значение.
Как чувствительность к регистру влияет на написание кода в JavaScript?
Чувствительность к регистру требует внимательности при написании кода. Например, если вы случайно напишете «let variable» вместо «let Variable», это будет восприниматься как создание новой переменной, а не изменение уже существующей. Такие ошибки могут привести к непредсказуемому поведению программы, если разработчик не заметит их на этапе написания кода.
Что произойдет, если в JavaScript используются одинаковые имена переменных с разным регистром?
Если в JavaScript использовать одинаковые имена переменных с разным регистром, это приведет к созданию разных переменных. Например, переменные «name» и «Name» будут независимыми, и изменение одной не повлияет на другую. Это может привести к ошибкам, особенно если переменные должны быть связаны.
Можно ли избежать ошибок из-за чувствительности к регистру в JavaScript?
Одним из способов избежать ошибок из-за чувствительности к регистру является соблюдение четкой и последовательной кодовой практики, например, использование одинаковых стилей именования для переменных и функций, таких как camelCase. Это помогает избежать путаницы и снижает вероятность ошибок, связанных с регистром.