Извлечение текста из HTML-документа – важная задача при обработке веб-страниц, и существует несколько эффективных способов сделать это без сложных инструментов. Наиболее распространёнными подходами являются использование регулярных выражений, библиотек для парсинга HTML, таких как BeautifulSoup и lxml, а также встроенных возможностей браузера. Каждый из этих методов имеет свои особенности, и выбор подходящего зависит от сложности документа и задачи.
Регулярные выражения – это первый инструмент, к которому прибегают многие разработчики для извлечения данных. Они позволяют быстро найти нужный текст в исходном HTML-коде. Однако этот метод подходит только для простых случаев, так как HTML часто содержит вложенные теги, а регулярные выражения плохо справляются с такими структурами. Для простых случаев, когда нужно извлечь текст без глубокого анализа структуры документа, регулярные выражения могут быть достаточно эффективными.
Для более сложных задач, связанных с извлечением текста из вложенных элементов, лучше использовать парсеры HTML. Библиотека BeautifulSoup на Python – один из наиболее популярных инструментов для этой задачи. Она автоматически корректно интерпретирует структуру HTML и позволяет легко извлекать текст, игнорируя теги. С помощью метода .get_text() можно получить весь текст из документа или из конкретного элемента, что упрощает обработку больших объёмов данных.
Использование таких инструментов, как lxml, ещё более эффективно при работе с большими объёмами данных благодаря своей скорости. Он позволяет выбирать элементы по XPath или CSS-селекторам, что даёт дополнительные возможности для точного извлечения нужного контента.
Использование Python и библиотеки BeautifulSoup для парсинга HTML
Для парсинга HTML в Python часто используется библиотека BeautifulSoup, которая предоставляет удобный интерфейс для извлечения данных из HTML-документов. Эта библиотека помогает эффективно работать с веб-страницами, извлекая нужную информацию, такую как текст, ссылки, изображения и другие элементы.
Пример использования:
from bs4 import BeautifulSoup
import requests
# Загружаем HTML-страницу
response = requests.get('https://example.com')
soup = BeautifulSoup(response.content, 'html.parser')
# Извлекаем все текстовые данные
text = soup.get_text()
# Извлекаем все ссылки
links = soup.find_all('a')
# Извлекаем заголовки h1
headings = soup.find_all('h1')
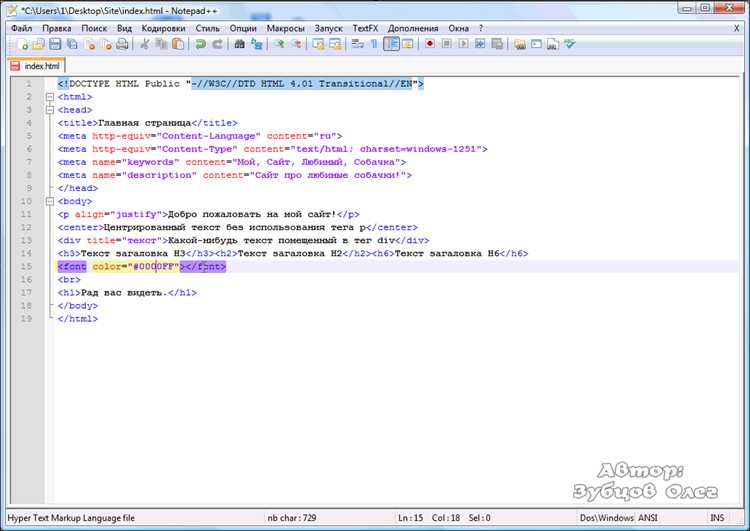
Для начала нужно установить библиотеку, если она еще не установлена:
pip install beautifulsoup4
С помощью метода get_text() можно извлечь весь текст из документа, удалив теги. Это полезно, когда требуется получить чистый текст без HTML-разметки.
Метод find_all() позволяет искать все элементы с заданным тегом или атрибутом. Например, для поиска всех ссылок на странице используется find_all('a'), что возвращает список всех тегов a в HTML.
Для более точного парсинга можно использовать различные методы, такие как find(), чтобы найти первый элемент с заданными характеристиками, или select(), чтобы искать элементы с помощью CSS-селекторов.
Пример поиска элемента с определенным классом:
div_with_class = soup.find('div', class_='my-class')
В этом примере find() ищет первый div с классом my-class. Если таких элементов несколько, используйте find_all() для получения списка всех таких элементов.
Чтобы работать с аттрибутами элементов, используйте свойства объектов, возвращаемых BeautifulSoup. Например, чтобы получить значение атрибута href у ссылки:
link = soup.find('a')
href = link['href']
Парсинг HTML с использованием BeautifulSoup достаточно эффективен и гибок. Библиотека хорошо справляется с некорректно сформированными HTML-документами и может использоваться в сочетании с другими библиотеками, такими как requests, для автоматического получения и обработки данных с веб-страниц.
Извлечение текста с помощью регулярных выражений в Python
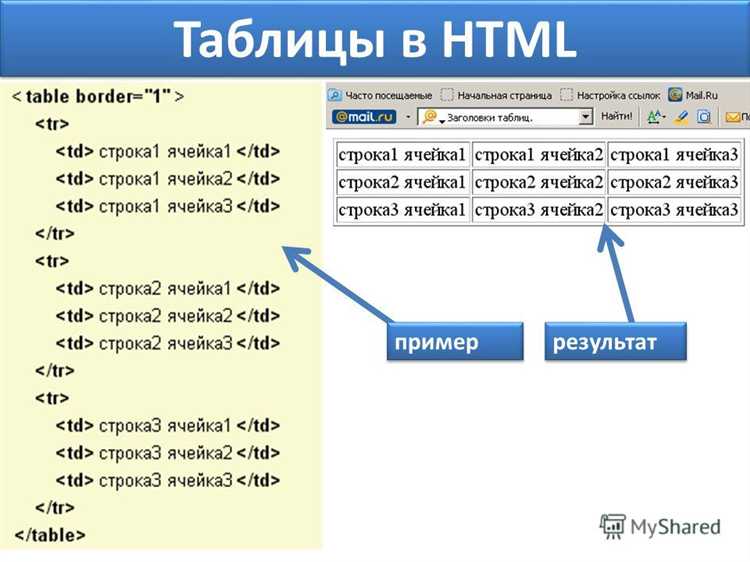
Для извлечения текста из HTML-документов с помощью Python, регулярные выражения могут быть удобным инструментом, особенно когда необходимо извлечь конкретные фрагменты текста по шаблону. Однако важно помнить, что регулярные выражения не предназначены для парсинга HTML в полном смысле этого слова, поскольку HTML может быть сложным и иметь вложенные теги. Но для простых задач регулярные выражения вполне подходят.
Для работы с регулярными выражениями в Python используется модуль re. Пример простого извлечения текста из HTML выглядит так:
import re
html_content = 'Это текст, который нужно извлечь.
'
pattern = r'>(.*?)<'
matches = re.findall(pattern, html_content)
for match in matches:
print(match)В этом примере регулярное выражение r'>(.*?)<' ищет любой текст, который находится между символами '>' и '<', что позволяет извлекать содержимое тегов. Использование findall возвращает все совпадения в виде списка строк, которые можно обработать дальше.
Важно понимать, что регулярные выражения не всегда могут корректно обработать сложную структуру HTML, такую как вложенные теги или атрибуты. Для более сложных случаев рекомендуется использовать специализированные библиотеки, такие как BeautifulSoup, которые могут справиться с иерархией элементов HTML.
Пример извлечения текста с помощью регулярных выражений может быть полезен, если структура документа простая, и задача ограничивается извлечением контента между тегами. Например, для извлечения заголовков можно использовать выражение:
pattern = r'.*? '
Этот шаблон найдет все заголовки <h1>–<h6>, но он будет извлекать весь HTML внутри этих тегов. Для более точного извлечения текста без тегов можно дополнительно использовать метод re.sub, чтобы удалить сами теги:
clean_text = re.sub(r'<.*?>', '', match)
Регулярные выражения позволяют эффективно извлекать текст с помощью шаблонов, но важно учитывать ограничения этого метода. Если HTML-документ имеет сложную структуру или несоответствия в теге, регулярные выражения могут вернуть неожиданные результаты. Поэтому для надежности в более сложных случаях лучше использовать более специализированные инструменты.
Применение JavaScript для парсинга HTML на веб-страницах

Для извлечения данных с веб-страниц JavaScript предоставляет мощные инструменты. С помощью стандартных методов DOM можно эффективно парсить HTML-структуру и извлекать необходимую информацию. Рассмотрим основные подходы и инструменты, доступные разработчикам.
Прежде чем приступить к парсингу, важно знать, что JavaScript работает непосредственно с DOM (Document Object Model) веб-страницы, который представляет собой структуру HTML-документа как дерево объектов.
Основные методы работы с DOM

- document.querySelector() – позволяет выбирать элементы на странице с помощью CSS-селекторов. Метод возвращает первый найденный элемент, соответствующий запросу.
- document.querySelectorAll() – аналогичен предыдущему, но возвращает все элементы, удовлетворяющие запросу, в виде коллекции.
- getElementById() – ищет элемент по уникальному идентификатору (ID). Это один из самых быстрых методов для поиска элемента.
- getElementsByClassName() – находит все элементы с указанным классом. Метод возвращает HTMLCollection, который можно перебрать в цикле.
- getElementsByTagName() – выбирает все элементы с заданным тегом, также возвращая HTMLCollection.
Извлечение текста и атрибутов
- textContent – свойство, которое позволяет получить или изменить текстовое содержимое элемента.
- innerHTML – возвращает или изменяет HTML-содержимое внутри элемента, включая вложенные теги.
- getAttribute() – извлекает значение атрибута элемента, например,
hrefу ссылки илиsrcу изображения.
Пример извлечения данных

Допустим, на странице есть несколько элементов <div class="product">, и нужно извлечь названия продуктов. Это можно сделать так:
const products = document.querySelectorAll('.product');
products.forEach(product => {
const title = product.querySelector('.title').textContent;
console.log(title);
});
В этом примере мы выбираем все элементы с классом product, затем для каждого элемента извлекаем текст внутри дочернего элемента с классом title.
Работа с динамическим контентом
Если данные на странице загружаются динамически (например, через API), то для парсинга можно использовать MutationObserver. Этот объект позволяет отслеживать изменения в DOM-дереве в реальном времени.
Пример:
const observer = new MutationObserver(mutations => {
mutations.forEach(mutation => {
if (mutation.type === 'childList') {
console.log('Данные обновлены!');
}
});
});
observer.observe(document.body, { childList: true, subtree: true });
Советы и рекомендации
- Используйте querySelector и querySelectorAll для простоты и гибкости в поиске элементов.
- Для работы с большими объемами данных избегайте повторных запросов к DOM, кешируйте результаты.
- Обратите внимание на производительность, особенно при работе с большим количеством элементов или динамическим контентом.
JavaScript предоставляет широкий набор инструментов для парсинга HTML, и в зависимости от задачи можно выбрать наиболее подходящие методы для извлечения данных.
Основы работы с библиотекой lxml для быстрого извлечения текста
Библиотека lxml предоставляет мощные инструменты для работы с HTML и XML документами. Ее отличает высокая производительность и удобство для извлечения данных. Для начала работы необходимо установить библиотеку с помощью команды:
pip install lxml
После установки можно приступать к разбору HTML-контента. В отличие от стандартного Python-модуля BeautifulSoup, lxml использует более быстрые алгоритмы для парсинга и поиска элементов, что особенно важно при работе с большими объемами данных.
Пример базового кода для извлечения текста из HTML документа:
from lxml import html
# Загружаем HTML
with open('example.html', 'r', encoding='utf-8') as file:
content = file.read()
# Парсим HTML
tree = html.fromstring(content)
# Извлекаем текст из всего документа
text = tree.text_content()
print(text)
В этом примере мы используем метод html.fromstring() для парсинга HTML. После этого метод text_content() возвращает весь текст, извлеченный из HTML документа, включая текст, расположенный внутри тегов.
Чтобы извлечь текст из конкретных элементов, можно воспользоваться XPath-запросами. Например, для получения текста из всех заголовков <h1>:
headers = tree.xpath('//h1/text()')
for header in headers:
print(header)
XPath-запрос //h1/text() находит все элементы <h1> и извлекает их текстовое содержимое. Это удобный способ работать с элементами, которые могут встречаться в разных частях документа.
Для более точного извлечения данных можно использовать фильтрацию по атрибутам. Например, если нужно извлечь текст из элементов с определенным классом:
elements = tree.xpath('//*[contains(@class, "target-class")]/text()')
for element in elements:
print(element)
Здесь мы используем XPath-запрос, который ищет все элементы, содержащие класс "target-class", и извлекает их текстовое содержимое. Это позволяет извлекать текст только из определенных частей документа, что полезно при анализе сложных страниц.
Также стоит отметить, что lxml поддерживает удобную работу с регулярными выражениями. Например, для извлечения текста, который соответствует определенному шаблону, можно использовать метод re:
import re
text_elements = tree.xpath('//p/text()')
filtered_text = [text for text in text_elements if re.search(r'\d{3}-\d{2}-\d{4}', text)]
for text in filtered_text:
print(text)
Этот пример ищет текст, который соответствует формату номера социального страхования в США. С помощью регулярных выражений можно легко фильтровать текстовые данные по нужным критериям.
Как извлечь текст из HTML-страницы с помощью CURL и PHP
Для извлечения текста из HTML-страницы с использованием CURL и PHP, первым шагом необходимо настроить CURL для получения содержимого веб-страницы. После этого можно применить различные методы обработки HTML-кода для извлечения нужного текста.
Вот пошаговое руководство:
- Инициализация CURL: Сначала инициализируем CURL-сессию для получения HTML-кода страницы. Для этого используем функцию
curl_init(). - Установка параметров: Устанавливаем параметры сессии CURL с помощью функции
curl_setopt(). Убедитесь, что включены опции для получения содержимого в виде строки.
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, "http://example.com");
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
$htmlContent = curl_exec($ch);
curl_close($ch);
Теперь у вас есть переменная $htmlContent, содержащая HTML-код страницы.
- Парсинг HTML с помощью регулярных выражений: Для извлечения текста можно использовать регулярные выражения, чтобы выбрать нужные элементы. Например, чтобы извлечь текст между тегами
<p>, можно применить следующий код:
preg_match_all('/(.*?)<\/p>/', $htmlContent, $matches);
$texts = $matches[1];
Это извлечет все параграфы из страницы и сохранит их в массив $texts.
- Использование библиотеки DOM: Для более сложного парсинга удобно использовать DOM-методы. С помощью PHP можно загрузить HTML в DOM-объект и манипулировать его элементами.
$dom = new DOMDocument;
libxml_use_internal_errors(true);
$dom->loadHTML($htmlContent);
$xpath = new DOMXPath($dom);
$nodes = $xpath->query('//p');
$texts = [];
foreach ($nodes as $node) {
$texts[] = $node->textContent;
}
Этот код извлекает текст всех параграфов <p> с использованием DOMXPath, что позволяет работать с более сложными структурами HTML.
Использование этих методов позволяет извлекать текст с веб-страниц с учетом различных структур HTML, сохраняя гибкость в обработке данных.
Инструменты командной строки для извлечения текста из HTML
Для извлечения текста из HTML с помощью командной строки существует несколько эффективных инструментов. Каждый из них имеет свои особенности и позволяет решать задачи в зависимости от требований к результату.
Одним из самых популярных инструментов является lynx. Это текстовый веб-браузер, который также позволяет извлекать текст с веб-страниц. Для извлечения текста достаточно запустить команду:
lynx -dump http://example.com
lynx -dump http://example.com > output.txt
Другим полезным инструментом является wget, который используется для загрузки содержимого веб-страниц. Для извлечения текста можно воспользоваться командой:
wget -qO- http://example.com | lynx -stdin -dump
Это решение позволяет сначала скачать HTML-страницу с помощью wget, а затем передать её в lynx для извлечения текста.
Если нужно извлечь текст без использования дополнительных утилит, можно воспользоваться html2text. Эта утилита конвертирует HTML в текстовый формат, автоматически удаляя все HTML-теги. Для использования достаточно ввести команду:
html2text http://example.com
Инструмент поддерживает различные опции, такие как сохранение результатов в файл или конвертация с локальных файлов.
Для более сложных операций с HTML и извлечения данных по заданным критериям можно использовать pup – инструмент для парсинга HTML с использованием CSS-селекторов. Пример использования:
curl -s http://example.com | pup 'h1 text{}'
Этот инструмент позволяет извлекать только определенные элементы на странице, например, заголовки, ссылки или параграфы, что может быть полезно для сбора структурированной информации.
Каждый из этих инструментов имеет свои преимущества в зависимости от задач. Важно выбирать тот, который лучше всего соответствует требованиям проекта и удобен для автоматизации процесса извлечения текста из HTML.
Вопрос-ответ:
Какие методы позволяют извлечь текст из HTML?
Для извлечения текста из HTML можно использовать несколько методов. Один из самых простых — это парсинг с помощью библиотек, таких как BeautifulSoup (для Python). Эта библиотека позволяет легко извлекать текст из HTML-страниц, удаляя все теги и оставляя только чистый текст. Также можно использовать регулярные выражения для поиска и извлечения нужных элементов, хотя этот метод требует большей осторожности, чтобы не пропустить важные данные или не допустить ошибок.
Почему лучше использовать библиотеки для извлечения текста, а не регулярные выражения?
Регулярные выражения можно использовать для извлечения текста, но этот метод не всегда удобен, особенно когда HTML-код сложный и содержит множество вложенных тегов. Библиотеки, такие как BeautifulSoup, учитывают структуру HTML, что значительно упрощает процесс извлечения текста и предотвращает ошибки, связанные с некорректной обработкой вложенных элементов. Такие библиотеки автоматически разбирают и очищают HTML, что делает код более читаемым и безопасным для работы с различными веб-страницами.