При работе с HTML файлами может возникнуть необходимость извлечь изображение, встроенное в документ. Это может потребоваться в случае, если изображение не доступно через прямую ссылку или вы хотите извлечь его из кода для дальнейшей обработки. Существует несколько способов сделать это вручную, каждый из которых зависит от того, как изображение встроено в HTML.
Самый распространённый способ вставки изображений в HTML – это использование тега <img>. Внутри этого тега изображение указывается через атрибут src, который содержит путь к файлу. Для извлечения изображения из такого файла достаточно найти данный атрибут и извлечь указанный путь к изображению. В случае, если путь абсолютный, вам нужно будет просто скачать файл по этому адресу. В случае относительного пути, вы получите изображение из текущей директории или папки на сервере.
Иногда изображения могут быть встроены непосредственно в HTML код в виде данных, закодированных в base64. Такие изображения не требуют отдельного файла и отображаются прямо в коде. Чтобы извлечь такое изображение, нужно найти строку, которая начинается с data:image и заканчивается на ;base64. Это закодированное изображение можно декодировать с помощью соответствующих инструментов и сохранить в виде файла.
Если в HTML файле используется стиль для фона, содержащий изображение, то его путь будет указан в свойстве background-image. В таком случае вам нужно будет найти этот стиль, обычно он располагается в теге <style> или в отдельных CSS файлах, и извлечь URL изображения. Далее можно скачать его с указанного адреса.
Таким образом, извлечение изображений из HTML файла не требует особых навыков, но важно точно понимать, как и в каком виде изображение встроено в документ. Знание этих нюансов значительно ускоряет процесс получения нужных файлов.
Как найти теги <img> в коде HTML документа
Для извлечения изображений из HTML-документа необходимо научиться находить теги <img>. Это можно сделать с помощью различных методов, включая использование поисковых инструментов в текстовом редакторе, регулярных выражений или специализированных библиотек.
1. Использование поиска в текстовом редакторе
Большинство текстовых редакторов позволяют искать теги по имени. Для поиска тегов <img> в HTML-документе просто используйте комбинацию клавиш для поиска и введите <img (без закрывающего углового скобки). Это поможет вам быстро найти все теги изображения в коде.
2. Регулярные выражения
Регулярные выражения – это мощный инструмент для поиска шаблонов в строках. Для поиска всех тегов <img> используйте следующее регулярное выражение:
<img[^>]*>Это выражение ищет теги <img>, независимо от наличия атрибутов внутри тега. Если нужно получить только атрибуты, такие как src или alt, можно модифицировать регулярное выражение для извлечения этих данных.
3. Использование библиотек для парсинга HTML
Для более сложных задач парсинга HTML лучше использовать библиотеки, такие как BeautifulSoup (для Python) или Cheerio (для JavaScript). Эти инструменты позволяют безопасно и эффективно обрабатывать HTML-документы, извлекая все теги <img> и связанные с ними атрибуты.
Пример с BeautifulSoup (Python):
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
images = soup.find_all('img')
for img in images:
print(img['src'])4. Анализ структуры HTML-документа
Если документ сложный, полезно проанализировать структуру и искать только теги <img> в определённых разделах (например, в <div> с классом gallery). Для этого можно использовать XPath или CSS-селекторы в библиотеках парсинга HTML.
Точное и эффективное нахождение тегов <img> позволяет быстро собрать все изображения, используемые в веб-странице, что особенно важно для дальнейшего извлечения или обработки данных.
Определение локального пути или URL источника изображения
Для извлечения изображения из HTML важно точно определить путь к его источнику, который может быть локальным или сетевым. Понимание различий между этими путями помогает точно интерпретировать исходный код и корректно загружать ресурсы.
Локальный путь указывает на файл, расположенный в пределах текущего проекта или на компьютере. Например, если изображение лежит в папке images внутри основного каталога сайта, путь будет выглядеть так: images/logo.png. В таком случае важно учитывать, что путь задается относительно текущей директории, из которой загружается HTML-документ.
Для абсолютных путей, которые начинаются с корневой папки проекта, путь может быть следующим: /images/logo.png. Такие пути всегда начинают с косой черты и позволяют указать ресурс, независимо от того, где находится сам файл HTML.
Если необходимо обратиться к файлу, который находится в другой директории, важно правильно указать количество и расположение точек и косых черт для перехода к нужной папке. Например, путь ../images/logo.png означает, что файл изображение находится на один уровень выше текущей папки в структуре каталогов.
URL источника изображения, в отличие от локального пути, представляет собой ссылку на ресурс, размещенный на сервере или в интернете. Пример такого пути: https://example.com/images/logo.png. URL указывает полный путь к изображению, включая протокол (http/https), доменное имя и путь на сервере.
При извлечении изображения из HTML важно учитывать, как будет обрабатываться путь: локально или через интернет. В случае использования URL необходимо удостовериться, что доступ к ресурсу открыт, а изображение доступно для загрузки. Локальные пути работают только на тех машинах, где присутствуют файлы, в то время как URL могут быть использованы на любых устройствах с интернет-соединением.
Извлечение base64-кодированных изображений из атрибута src
Base64-кодированные изображения часто используются в HTML-документах для встраивания изображений непосредственно в код страницы. Это позволяет избежать дополнительных HTTP-запросов, но при этом размер изображения увеличивается из-за кодирования в строку. Извлечение такого изображения требует декодирования строки base64 и сохранения результата в файл.
Чтобы извлечь base64-кодированное изображение из атрибута src, следуйте этим шагам:
- Найдите элемент
<img>в HTML-документе, который содержит изображение в формате base64. Атрибутsrcбудет начинаться сdata:image/, за которым идет кодировка. - Извлеките строку из атрибута
src. Она будет выглядеть какdata:image/png;base64,.... Важная часть – это часть послеbase64,, которая и является закодированным изображением. - Удалите префикс
data:image/png;base64,или аналогичный для других форматов изображений. Оставьте только саму строку base64. - Используйте инструмент или библиотеку для декодирования строки base64. Например, можно воспользоваться онлайн-сервисами или Python-скриптом.
Пример на Python:
import base64
base64_string = "iVBORw0KGgoAAAANSUhEUgAAAAUA..."
image_data = base64.b64decode(base64_string)
with open("output_image.png", "wb") as f:
f.write(image_data)
После выполнения этого кода изображение будет сохранено как файл output_image.png.
Важно помнить, что base64-кодировка увеличивает размер файла на 33%. В случае с большим количеством изображений, это может привести к значительному увеличению общего объема HTML-документа.
Сохранение изображения из URL с помощью браузера
Для сохранения изображения с URL через браузер можно использовать несколько методов в зависимости от того, какой браузер используется. Приведем конкретные шаги для самых популярных браузеров.
В Google Chrome и Mozilla Firefox процесс сохранения изображения схож. Для этого необходимо:
- Перейти по ссылке на изображение, которое нужно сохранить, или щелкнуть по изображению правой кнопкой мыши.
- Выбрать из контекстного меню опцию «Сохранить изображение как…» или «Сохранить как».
- Указать место на компьютере для сохранения и выбрать формат, если он отличается от стандартного (например, PNG, JPG).
Для Microsoft Edge процесс аналогичен. Важно помнить, что браузеры могут предложить выбор между форматами в зависимости от типа изображения и настроек.
Кроме того, если URL ссылается на файл, который не отображается как изображение напрямую (например, файл с расширением .jpg или .png, но представлен как ссылка), можно использовать встроенные инструменты разработчика для поиска прямого пути к изображению:
- Нажмите F12, чтобы открыть инструменты разработчика.
- Перейдите на вкладку «Network» или «Сеть».
- Обновите страницу и найдите запрос с типом «image» или фильтруйте по типу контента.
- Щелкните по запросу с изображением и скопируйте URL, который будет отображен в панели информации.
После этого URL можно вставить в адресную строку и сохранить изображение с использованием стандартных методов. Этот способ полезен, если изображение не загружается сразу, но его можно найти через сетевой запрос.
Скачивание изображения из HTML вручную через исходный код страницы
Для скачивания изображения из HTML-страницы вручную через исходный код, нужно следовать нескольким ключевым шагам. Этот процесс полезен, когда изображения не предоставляют ссылки для скачивания или скрыты в сложных элементах веб-страницы.
Первый шаг – открыть исходный код страницы. В большинстве браузеров для этого достаточно щелкнуть правой кнопкой мыши на странице и выбрать «Просмотреть исходный код» или нажать клавишу Ctrl + U.
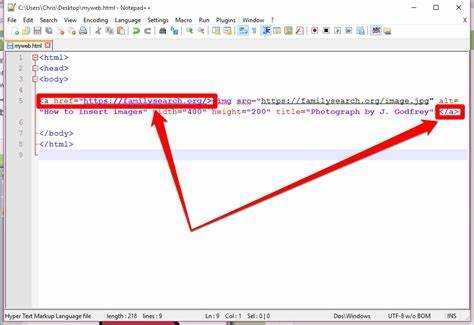
Далее, нужно найти ссылку на нужное изображение. Обычно изображения в HTML вставляются с помощью тега <img>. Пример:
<img src="https://example.com/image.jpg" alt="Описание изображения">
Основные моменты, на которые стоит обратить внимание:
- src – это атрибут, содержащий путь к изображению. Он может быть абсолютным (например,
https://example.com/image.jpg) или относительным (например,/images/photo.jpg). - alt – описание изображения, которое не влияет на скачивание, но полезно для понимания содержимого изображения.
Как только ссылка на изображение найдена, скопируйте URL, указанный в атрибуте src.
После этого откройте новый вкладку в браузере и вставьте скопированный URL в адресную строку. Если изображение доступно, оно загрузится в браузере. Для его сохранения достаточно щелкнуть правой кнопкой мыши по изображению и выбрать «Сохранить изображение как…».
В случае, если изображение является фоном или используется через CSS (например, в свойстве background-image), процесс немного изменяется:
- Найдите стиль, который указывает на путь к изображению, например:
background-image: url('https://example.com/background.jpg');. - Скопируйте URL изображения и вставьте его в адресную строку браузера, как описано выше.
При работе с динамическими веб-страницами, где изображение может загружаться через JavaScript, придется использовать дополнительные инструменты, такие как инструменты разработчика (например, в Google Chrome это Ctrl + Shift + I для открытия Developer Tools). В разделе «Network» можно отследить запросы, которые приводят к загрузке изображений.
Важный момент: если изображение защищено авторскими правами или доступно только по подписке, его скачивание без разрешения может нарушать закон.
Ручная расшифровка и сохранение base64 изображения в файл
Первым шагом является извлечение строки base64. Обычно она начинается с префикса вида «data:image/png;base64,» или другого формата в зависимости от типа изображения (например, «data:image/jpeg;base64,»). Важно удалить эту префиксную часть, оставив только кодированную строку.
Далее нужно преобразовать строку base64 обратно в двоичные данные. Это можно сделать с помощью различных программных языков или утилит. В Python, например, для расшифровки можно использовать встроенную библиотеку base64. Пример кода:
import base64
# Строка base64 без префикса
base64_string = "your_base64_string_here"
# Декодирование base64 строки в байты
image_data = base64.b64decode(base64_string)
# Сохранение изображения в файл
with open("image.png", "wb") as file:
file.write(image_data)Если используется другая среда, важно учитывать аналогичные методы декодирования, например, в JavaScript это можно выполнить с использованием встроенных функций для работы с файловыми данными.
После декодирования изображения в байты, данные можно сохранить в файл с нужным расширением. Расширение зависит от исходного формата изображения, который был кодирован в base64. Важно корректно определить формат изображения, чтобы избежать ошибок при его открытии.
Некоторые редакторы и онлайн-утилиты также позволяют выполнить эти действия без написания кода. Однако вручную это даёт полный контроль над процессом и позволяет обрабатывать изображения в соответствии с конкретными требованиями.
Проверка корректности сохранённого изображения
После сохранения изображения из HTML-файла важно убедиться в его целостности и правильности. Для этого следует выполнить несколько этапов проверки.
1. Проверка расширения файла
Каждое изображение имеет свой формат, который определяется расширением файла. После сохранения нужно убедиться, что файл имеет правильное расширение, соответствующее типу изображения (например, .jpg, .png, .gif). Ошибки в расширении могут повлиять на возможность его открытия в различных приложениях.
2. Проверка содержимого файла
Откройте изображение с помощью стандартных программ для просмотра картинок. Если изображение не открывается или отображается с ошибками (например, только чёрный экран, искаженные цвета), это сигнализирует о проблемах с сохранением. Часто это связано с повреждением данных во время процесса сохранения или неправильной кодировкой.
3. Сравнение с исходным изображением
Если возможно, сравните сохранённое изображение с оригиналом. Это можно сделать, просмотрев как исходное изображение, так и сохранённое рядом на экране. Любые визуальные отклонения, такие как потеря качества, искажения или изменения цветов, могут указывать на ошибки при сохранении.
4. Проверка размера файла
Размер изображения должен быть сопоставим с его качеством и разрешением. Слишком маленький или слишком большой размер файла может свидетельствовать о неправильной конвертации или сохранении. Например, сохранённый файл с расширением .jpg при низком качестве будет значительно меньше оригинала в формате .png с высоким разрешением.
5. Использование инструментов для проверки целостности файла
Для более глубокого анализа можно использовать специальные программы для проверки целостности файлов изображений. Такие инструменты анализируют структуру данных изображения и выявляют любые повреждения или несоответствия стандартам форматов.
6. Проверка метаданных
Изображения могут содержать метаданные, такие как EXIF, которые могут быть полезны для анализа. Для этого используйте программы для чтения метаданных, чтобы убедиться, что они корректно сохранены и не изменены. Это особенно важно для фотографий, содержащих информацию о времени съемки, модели камеры и других параметрах.
7. Проверка отображения на разных устройствах
После проверки на компьютере, стоит также проверить отображение изображения на других устройствах (например, на мобильном телефоне или в браузере). Это поможет выявить проблемы с совместимостью или ошибками, которые могут возникать при отображении на разных экранах и разрешениях.
Вопрос-ответ:
Что такое извлечение изображения из HTML файла вручную и как это можно сделать?
Извлечение изображения из HTML файла вручную — это процесс поиска и сохранения изображений, встроенных в веб-страницу. Для этого необходимо открыть HTML файл, найти теги, содержащие изображения, такие как ``, и извлечь ссылку на изображение из атрибута `src`. После этого можно скачать изображение, используя ссылку или открыть его в браузере для сохранения.
Какие инструменты понадобятся для извлечения изображений из HTML файла вручную?
Для извлечения изображений вручную достаточно базовых инструментов, таких как текстовый редактор для просмотра и редактирования HTML файла, а также веб-браузер для проверки изображений. Если изображения находятся на внешних серверах, потребуется доступ к интернету для их загрузки. В некоторых случаях, можно использовать инструменты разработчика в браузере для удобного поиска нужных тегов и ресурсов.
Какие сложности могут возникнуть при извлечении изображений из HTML файла вручную?
При извлечении изображений вручную могут возникнуть несколько трудностей. Во-первых, изображения могут быть встроены через CSS или JavaScript, что усложняет их поиск. Во-вторых, ссылки на изображения могут быть относительными, а не абсолютными, что требует дополнительного анализа для правильной загрузки. Также если HTML файл большой, вручную найти все изображения может быть трудоемко и занять много времени.
Какие альтернативы существуют для извлечения изображений из HTML файлов, если вручную это сделать неудобно?
Если извлечение изображений вручную слишком трудоемко, можно использовать автоматические инструменты. Одним из таких инструментов является использование специальных скриптов на Python, таких как BeautifulSoup, которые могут быстро пройти по всем тегам и извлечь все изображения. Также существуют браузерные расширения и программы, которые позволяют скачивать все изображения с веб-страницы за один раз, что может быть значительно удобнее, чем вручную искать каждый ресурс.