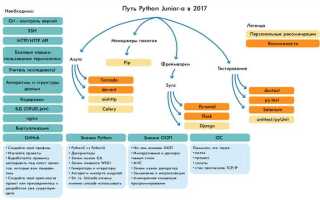
Для успешного старта в Python важно не только освоить основы синтаксиса, но и понять, какие инструменты и подходы делают разработку эффективной. Первое, с чем сталкивается новичок, – это правильный выбор версий Python и настройка рабочего окружения. Python 3.x является стандартом, и использование версии 2.x, несмотря на её долгую популярность, уже не рекомендуется.
Одним из важнейших этапов обучения является освоение основных библиотек, которые предоставляют готовые решения для многих задач. На старте необходимо познакомиться с такими модулями, как os, sys, math, datetime и json. Это базовые инструменты для работы с файловой системой, обработкой дат и временем, а также работы с JSON-данными, которые встречаются практически в каждом проекте.
Важным аспектом является понимание принципов объектно-ориентированного программирования (ООП). Концепции классов, объектов, наследования и инкапсуляции – это основа Python, которая помогает структурировать код и создавать масштабируемые приложения. Особенно стоит изучить стандартные практики проектирования и паттерны, такие как singleton, factory и observer.
Не менее важно научиться работать с инструментами для управления зависимостями. Это такие инструменты, как pip для установки пакетов и virtualenv для изоляции окружений. С помощью этих инструментов можно организовать удобную и безопасную работу над проектами, предотвращая конфликты версий библиотек.
Также ключевым моментом является умение работать с тестированием. Начинать следует с юнит-тестов, изучив библиотеку unittest, а затем переходить к более сложным фреймворкам, таким как pytest. Это поможет обеспечить качество кода и быстрее находить ошибки в процессе разработки.
Как настроить рабочее окружение с помощью venv и pip

Для работы над проектами на Python рекомендуется использовать виртуальные окружения. Это позволяет изолировать зависимости проекта и избежать конфликтов между пакетами, установленными для разных проектов. Для настройки такого окружения можно использовать два инструмента: venv и pip.
Первым шагом является создание виртуального окружения с помощью venv. В терминале выполните команду:
python -m venv название_окруженияПосле выполнения этой команды будет создана папка с указанным именем, внутри которой будет находиться изолированное окружение Python, включающее собственный интерпретатор Python и набор стандартных библиотек. Чтобы активировать окружение, используйте одну из следующих команд, в зависимости от операционной системы:
- Для Windows:
название_окружения\Scripts\activate - Для macOS и Linux:
source название_окружения/bin/activate
После активации окружения в командной строке появится его название, что позволит вам точно понимать, что работаете именно в нем.
Когда окружение активировано, можно устанавливать необходимые зависимости с помощью pip. Например, чтобы установить пакет requests, выполните команду:
pip install requestsЭто установит пакет только в рамках активированного виртуального окружения. Если нужно установить несколько пакетов, лучше создать файл requirements.txt, который будет содержать список всех зависимостей. Для создания этого файла выполните команду:
pip freeze > requirements.txtЗатем для установки зависимостей на другом компьютере или в другом окружении используйте команду:
pip install -r requirements.txtЧтобы деактивировать виртуальное окружение, достаточно выполнить команду:
deactivateТаким образом, используя venv для создания изолированных окружений и pip для управления зависимостями, можно эффективно работать над проектами, не опасаясь конфликтов библиотек и версий.
Чем отличаются списки, кортежи и множества на практике
Списки – это изменяемые коллекции, которые позволяют добавлять, удалять и изменять элементы. Это делает их удобными для работы с динамическими данными. Списки поддерживают порядок элементов, что позволяет обращаться к ним по индексу. Однако, из-за их изменяемости, они могут быть медленнее в сравнении с другими типами коллекций в ситуациях, когда требуется постоянство данных.
- Можно изменять содержимое (добавлять, удалять, изменять элементы).
- Поддерживают порядок элементов и доступ через индекс.
- Подходят для работы с коллекциями данных, которые часто меняются.
- Пример:
my_list = [1, 2, 3]
Кортежи – это неизменяемые коллекции. Если нужно создать постоянный набор данных, который не должен изменяться, кортежи – лучший выбор. Из-за своей неизменяемости они обычно быстрее списков, что делает их предпочтительными для работы с фиксированными данными. Также кортежи могут использоваться в качестве ключей в словарях, чего не могут списки.
- Невозможно изменять содержимое (после создания).
- Быстрее списков для работы с неизменяемыми данными.
- Могут использоваться в качестве ключей в словарях (судя по их хэшируемости).
- Пример:
my_tuple = (1, 2, 3)
Множества – это коллекции, которые не поддерживают порядок и не допускают дублирования элементов. Это идеальный тип данных, когда важна уникальность элементов. Множества полезны для выполнения операций, таких как объединение, пересечение или разность, и могут быть значительно быстрее, чем списки, при проверке наличия элемента.
- Не поддерживают порядок элементов.
- Не содержат дубликатов.
- Подходят для операций с уникальными элементами, например, нахождения пересечений или объединений.
- Пример:
my_set = {1, 2, 3}
В зависимости от задачи выбирайте подходящий тип коллекции:
- Для коллекций с изменяемыми данными – используйте списки.
- Для фиксированных данных – используйте кортежи.
- Для хранения уникальных элементов и выполнения математических операций – выбирайте множества.
Как читать и записывать файлы разных форматов в Python

В Python для работы с файлами различных форматов существует множество стандартных библиотек. В зависимости от типа файла, подход к чтению и записи может варьироваться. Рассмотрим, как работать с текстовыми файлами, CSV, JSON и бинарными файлами.
Для чтения и записи текстовых файлов используется встроенная функция open(), которая поддерживает работу с текстовыми и бинарными файлами. Важно понимать, что при открытии файла необходимо указать режим доступа: чтение (‘r’), запись (‘w’), добавление (‘a’) или бинарный режим (‘rb’, ‘wb’).
Пример чтения текстового файла:
with open('example.txt', 'r') as file:
content = file.read()
print(content)Пример записи в текстовый файл:
with open('example.txt', 'w') as file:
file.write('Hello, Python!')Для работы с CSV файлами используется модуль csv. Он позволяет эффективно работать с данными в формате CSV, как с текстовыми файлами, представляющими таблицы.
Чтение CSV файла:
import csv
with open('data.csv', 'r') as file:
reader = csv.reader(file)
for row in reader:
print(row)Запись данных в CSV файл:
import csv
data = [['Name', 'Age'], ['Alice', 30], ['Bob', 25]]
with open('output.csv', 'w', newline='') as file:
writer = csv.writer(file)
writer.writerows(data)Для работы с JSON файлами используется стандартная библиотека json, которая позволяет легко сериализовать и десериализовать данные в JSON формат.
Чтение JSON файла:
import json
with open('data.json', 'r') as file:
data = json.load(file)
print(data)Запись данных в JSON файл:
import json
data = {"name": "Alice", "age": 30}
with open('output.json', 'w') as file:
json.dump(data, file, indent=4)Для работы с бинарными файлами используется стандартная библиотека Python для работы с байтами. При этом важно понимать, что данные в бинарном файле не поддаются расшифровке в виде обычного текста.
Чтение бинарного файла:
with open('example.bin', 'rb') as file:
content = file.read()
print(content)Запись в бинарный файл:
data = b'\x00\x01\x02\x03'
with open('output.bin', 'wb') as file:
file.write(data)Знание специфики работы с различными типами файлов – это ключевая часть работы любого Python-разработчика. Важно правильно выбирать режимы работы с файлами, учитывать особенности форматов и понимать, как эффективно работать с данными внутри файлов.
Что такое PEP8 и как оформить код согласно этому стандарту

Основные рекомендации PEP8:
Отступы: Код должен использовать отступы в 4 пробела. Не используйте табуляцию. Это помогает поддерживать одинаковый стиль и предотвращает проблемы с совместимостью между различными редакторами кода.
Длина строк: Строки не должны превышать 79 символов. Для удобства чтения разбивайте длинные строки на несколько частей. Это делает код более компактным и читаемым на экранах с меньшим разрешением.
Пробелы: Пробелы не используются внутри скобок. Например, правильно будет написать list[1, 2, 3], а не list[ 1, 2, 3 ]. Также важно добавлять пробелы после запятой в списках и аргументах функций, например: def func(a, b):, а не def func(a,b):.
Именование: Имена переменных, функций и методов должны быть в нижнем регистре с использованием нижнего подчеркивания для разделения слов, например, my_variable, calculate_area. Классы именуются в стиле CamelCase, то есть каждое новое слово начинается с заглавной буквы, например, MyClass.
Комментарии: Комментарии должны объяснять «почему» что-то сделано, а не «что» сделано. Однострочные комментарии начинаются с символа # и должны быть отделены пробелом от кода. Многострочные комментарии заключаются в тройные кавычки и используются, когда требуется более подробное описание.
Импорты: Все импорты должны быть расположены в начале файла и разделены на три группы: стандартные библиотеки, сторонние библиотеки и локальные модули. Каждая группа должна быть разделена пустой строкой.
Пустые строки: Внутри функции или метода не рекомендуется оставлять пустые строки, кроме как для разделения логических блоков. Между методами или классами рекомендуется использовать одну пустую строку для улучшения читаемости.
Следование этим простым, но важным правилам помогает не только улучшить качество кода, но и сделать его более понятным и поддерживаемым в будущем. Это особенно важно при работе в команде, где стиль кодирования играет большую роль в удобстве совместной разработки.
Как отлаживать код с помощью встроенных инструментов
pdb можно запустить с помощью команды import pdb; pdb.set_trace(). Эта строка при выполнении кода остановит программу и откроет интерактивную консоль, где можно вводить команды для проверки значений переменных или перехода к следующему шагу. Например, команды n (next) и c (continue) помогут шагать по коду или продолжить выполнение программы до следующей точки останова.
Для более сложных сценариев отладки можно использовать интегрированные среды разработки (IDE) с графическими интерфейсами для отладки, такие как PyCharm или VS Code. В этих редакторах можно ставить точки останова, шагать по коду, отслеживать значения переменных и даже изменять их в процессе выполнения программы. Эти возможности позволяют сделать процесс отладки более наглядным и удобным.
Какие библиотеки использовать для работы с API и JSON
requests – это наиболее популярная библиотека для отправки HTTP-запросов. Она поддерживает все типы запросов, такие как GET, POST, PUT, DELETE и другие. Также она автоматически обрабатывает большинство аспектов работы с HTTP, включая параметры URL, заголовки и аутентификацию. Для работы с JSON в requests достаточно использовать метод .json(), который автоматически десериализует ответ в Python-словарь.
Пример использования:
import requests
response = requests.get('https://api.example.com/data')
data = response.json() # Преобразование JSON-ответа в Python-объект
Для более детального контроля над HTTP-запросами можно использовать http.client. Эта стандартная библиотека предоставляет более низкоуровневый доступ к HTTP-соединениям, что может быть полезно для реализации собственных методов аутентификации, работы с сокс-прокси или в специфичных случаях, когда нужно минимизировать зависимости.
Для работы с JSON можно использовать стандартную библиотеку json, которая предоставляет функции для сериализации (преобразования объектов Python в строку JSON) и десериализации (преобразования строки JSON в объекты Python). Библиотека json встроена в Python, и обычно её достаточно для простых задач по обработке данных в формате JSON.
Пример работы с json:
import json
# Преобразование Python-объекта в JSON
data = {'name': 'John', 'age': 30}
json_string = json.dumps(data)
# Преобразование JSON-строки в Python-объект
parsed_data = json.loads(json_string)
Если вам нужно взаимодействовать с API, которое активно использует JSON, и вы хотите ускорить процесс, можно использовать requests-json. Эта библиотека расширяет функциональность requests, автоматически добавляя поддержку работы с JSON-ответами. В отличие от стандартного requests, вам не нужно явно вызывать .json(), так как это делается автоматически.
Пример использования requests-json:
import requests
import requests_json
session = requests_json.Session()
response = session.get('https://api.example.com/data')
data = response.json()
Каждая из этих библиотек имеет свои особенности и области применения. requests подходит для большинства стандартных случаев, а для низкоуровневой работы с HTTP или оптимизации производительности стоит обратить внимание на http.client и другие более специализированные инструменты.
Как писать тесты с unittest и pytest для своего кода
Для проверки корректности работы кода важно писать тесты, и Python предлагает два популярных инструмента для этой цели – `unittest` и `pytest`. Оба фреймворка позволяют эффективно и быстро находить ошибки в коде, но их подходы и особенности немного различаются.
При использовании `unittest`, тесты пишутся в виде классов, которые наследуются от `unittest.TestCase`. Каждый тестовый метод должен начинаться с `test_`, чтобы фреймворк мог его автоматически обнаружить. Вот пример простого теста:
import unittest
class TestMyFunction(unittest.TestCase):
def test_addition(self):
result = 1 + 1
self.assertEqual(result, 2)
if __name__ == "__main__":
unittest.main()В этом примере используется метод `assertEqual`, который проверяет, что результат сложения равен 2. Для других проверок существуют методы вроде `assertTrue`, `assertFalse`, `assertRaises` и другие, которые позволяют тестировать различные условия.
С другой стороны, `pytest` предоставляет более лаконичный способ написания тестов. Здесь нет необходимости создавать классы, тесты могут быть функциями. Это делает код проще и легче для восприятия. Пример:
def test_addition():
result = 1 + 1
assert result == 2Здесь мы используем стандартное утверждение `assert`, что делает синтаксис чище. `pytest` автоматически найдет все функции, начинающиеся с `test_`, и выполнит их.
Кроме того, `pytest` поддерживает более сложные возможности, такие как фикстуры, параметризация тестов и более гибкое управление тестовыми сессиями. Фикстуры позволяют подготавливать тестовые данные или конфигурацию, которые могут быть использованы несколькими тестами:
import pytest
@pytest.fixture
def sample_data():
return [1, 2, 3]
def test_sum(sample_data):
assert sum(sample_data) == 6Здесь `sample_data` – это фикстура, которая предоставляет данные для теста. Она передается в тестовую функцию как аргумент.
Для параметризации тестов в `pytest` используется декоратор `@pytest.mark.parametrize`, который позволяет запустить тест с разными наборами входных данных:
@pytest.mark.parametrize("a, b, expected", [(1, 2, 3), (2, 3, 5), (3, 4, 7)])
def test_addition(a, b, expected):
assert a + b == expectedЭтот подход позволяет избежать дублирования кода и ускоряет тестирование при наличии нескольких входных данных.
Когда речь идет о выборе между `unittest` и `pytest`, важно учитывать, что `unittest` более формален, он ориентирован на написание более структурированных тестов. `pytest`, в свою очередь, предоставляет более гибкие возможности и работает с более легким синтаксисом, что делает его более удобным для быстрого написания тестов. В любом случае, оба фреймворка полезны и позволяют добиться высокого качества кода через тестирование.
Вопрос-ответ:
Какие языки программирования должен знать начинающий Python-разработчик?
Для начинающего Python-разработчика основное внимание следует уделить самому Python. Однако будет полезно знакомство с основами других языков программирования, таких как JavaScript или C, чтобы расширить кругозор и понять различные парадигмы разработки. Знание SQL для работы с базами данных тоже полезно. В целом, важно развивать умение решать задачи, используя разные инструменты, а не привязываться к конкретному языку.
Какие библиотеки Python стоит изучить в первую очередь?
Для новичка в Python полезно освоить библиотеки, которые решают самые распространенные задачи. Например, `NumPy` и `Pandas` — для работы с данными, `Matplotlib` — для визуализации данных, `Flask` или `Django` — для создания веб-приложений. Эти инструменты помогут вам быстро начать решать практические задачи и улучшить навыки программирования.
Какие трудности могут возникнуть у начинающего Python-разработчика и как их преодолеть?
Основные трудности начинающего программиста — это понимание структуры кода и логики программирования. Иногда бывает сложно понять, как работать с данными, решать алгоритмические задачи или организовывать проект. Чтобы преодолеть эти трудности, важно регулярно практиковаться, решать задачи на онлайн-платформах, читать документацию и обращаться за помощью к сообществу. По мере накопления опыта эти проблемы будут уходить.
Как выбрать подходящий текстовый редактор или IDE для Python?
Для начинающего Python-разработчика можно начать с простых текстовых редакторов, таких как VS Code или Sublime Text. Они легкие, настроить их достаточно просто, и они имеют поддержку Python. Если вы хотите больше функций, стоит обратить внимание на IDE, такие как PyCharm, который предоставляет мощные инструменты для отладки и работы с проектами. Важно, чтобы инструмент был удобен и помогал вам сосредоточиться на написании кода.
Как ускорить свой прогресс в обучении Python и не забросить изучение?
Чтобы не забросить обучение, нужно ставить себе конкретные цели и делить процесс на маленькие шаги. Регулярная практика — это ключевой момент. Разработайте план, по которому будете учить новые темы, и решайте задачи на разных платформах, например, на LeetCode или Codewars. Также полезно работать над реальными проектами, чтобы почувствовать результат и применить полученные знания на практике.
Какие базовые навыки нужно освоить начинающему Python-разработчику?
Для начинающего Python-разработчика важно освоить несколько ключевых аспектов. Прежде всего, необходимо уверенно работать с синтаксисом языка: понимать базовые конструкции, такие как циклы, условия, функции и переменные. Далее, стоит изучить основные библиотеки Python, такие как `os`, `sys`, `math`, а также научиться работать с типами данных (списки, кортежи, множества, словари). Важно также освоить работу с файлами и научиться писать скрипты для автоматизации простых задач. Для полноценной работы с Python, полезно разобраться в принципах объектно-ориентированного программирования, а также научиться работать с виртуальными окружениями и пакетами через `pip` и `venv`. Без этих знаний будет сложно продолжить углубленное изучение языка.
Какую роль в развитии Python-разработчика играет опыт работы с фреймворками?
Работа с фреймворками в Python — это не обязательный этап для начинающего разработчика, но со временем это становится важной частью профессионального роста. Фреймворки, такие как Django, Flask (для веб-разработки) или PyTorch, TensorFlow (для машинного обучения), значительно ускоряют разработку, поскольку они предоставляют готовые решения для множества распространенных задач. Опыт работы с фреймворками поможет разобраться в принципах разработки более сложных приложений, улучшить качество кода и ускорить процесс его написания. Для новичка важно не торопиться осваивать фреймворки сразу, а сосредоточиться сначала на укреплении фундаментальных знаний, а уже потом переходить к изучению инструментов, которые облегчают создание более сложных проектов.