Cloudflare активно используется для защиты веб-сайтов от различных угроз, таких как DDoS-атаки, ботнеты и нежелательные запросы. Однако, несмотря на свою эффективность, система защиты не является неприступной, и с помощью правильных инструментов можно обойти некоторые её механизмы. Один из таких инструментов – язык программирования Python. Используя библиотеки и подходы, оптимизированные для работы с HTTP-запросами, можно разработать скрипты, способные эффективно взаимодействовать с сайтом, защищённым Cloudflare.
Основные методы обхода защиты Cloudflare с помощью Python включают эмуляцию браузера с использованием таких библиотек, как requests, pyppeteer или selenium. Важно понимать, что Cloudflare использует различные технологии, включая JavaScript-обработку, капчи и проверки на основе поведения пользователей. Поэтому важно учитывать, что стандартные HTTP-запросы без выполнения JavaScript могут не пройти проверку, если защита использует проверки типа «Challenge» или «Browser Integrity Check».
Для эффективного обхода необходимо учитывать несколько факторов: управление cookies, заголовками HTTP-запросов, а также наличие уникальных параметров в URL или JavaScript-вычислений, которые могут потребовать выполнения кода на стороне клиента. Применение этих методов может существенно повысить вероятность успешного обхода защиты. Кроме того, важно следить за обновлениями в системах защиты, так как Cloudflare регулярно совершенствует свои алгоритмы, что требует адаптации методов обхода.
Анализ механизма защиты Cloudflare: основные методы блокировки
Ещё один важный аспект – это использование CAPTCHA. Cloudflare может требовать от пользователя пройти CAPTCHA-проверку, если система распознаёт подозрительное поведение или высокую частоту запросов. Этот метод направлен на предотвращение атак типа brute-force и скрейпинга. CAPTCHA может быть как традиционной (позволяющей выбрать объекты на изображениях), так и более сложной, в зависимости от уровня угрозы.
Также Cloudflare активно использует анализ IP-адресов для блокировки подозрительных источников. При подозрении на бот-трафик система может полностью заблокировать доступ с определённого IP-диапазона. Кроме того, система применяет алгоритмы, которые отслеживают аномалии в трафике, например, слишком частые запросы с одного источника или необычные паттерны трафика, характерные для DDoS-атак.
Метод «Challenge Passage» заключается в том, чтобы заставить клиента выполнить дополнительные проверки (например, ввести код или подтвердить свой запрос), если предыдущие этапы защиты не дали полной уверенности в том, что запрос поступает от реального пользователя. Это может быть необходимо при высоком уровне подозрений, когда другие способы не смогли решить проблему.
Наконец, Cloudflare активно использует различные алгоритмы для анализа реальной активности пользователя, включая временные метки и географическое расположение. Например, если запросы поступают в ночное время из региона, где обычно не зарегистрировано активности, это может стать сигналом для системы о том, что запрос потенциально является вредоносным. В таких случаях могут быть предприняты дополнительные шаги для проверки, такие как двухфакторная аутентификация.
Использование библиотеки requests для обхода CAPTCHA в Cloudflare
Cloudflare использует несколько типов защитных механизмов, включая JavaScript-челленджи, CAPTCHA и угрозу с реальной симуляцией запросов. Библиотека requests позволяет только работать с HTTP-запросами, поэтому нам нужно учитывать несколько аспектов, таких как куки, заголовки и управление сессиями.
Первым шагом в обходе является использование сессии. Сессии сохраняют куки и заголовки, что важно для взаимодействия с Cloudflare. Пример кода:
import requests
session = requests.Session()
response = session.get('https://example.com')
После выполнения первого запроса через сессию, мы можем получить куки, которые необходимы для последующих запросов. Обычно Cloudflare использует JavaScript-челленджи, которые необходимо решить на уровне браузера. Для bypass CAPTCHA в некоторых случаях можно использовать сторонние сервисы, такие как 2Captcha или AntiCaptcha, которые решают CAPTCHA в автоматическом режиме и возвращают токен, который мы затем отправляем в запросах.
Для интеграции с 2Captcha можно использовать следующий код:
import requests
API_KEY = 'YOUR_2CAPTCHA_API_KEY'
captcha_url = 'https://2captcha.com/in.php'
captcha_answer_url = 'https://2captcha.com/res.php'
# Отправка CAPTCHA
captcha_payload = {
'key': API_KEY,
'method': 'userrecaptcha',
'googlekey': 'Google_Captcha_Site_Key',
'pageurl': 'https://example.com'
}
captcha_response = requests.post(captcha_url, data=captcha_payload).text
# Получение ответа на CAPTCHA
captcha_id = captcha_response.split('|')[1]
captcha_result_payload = {
'key': API_KEY,
'action': 'get',
'id': captcha_id
}
captcha_result = requests.get(captcha_answer_url, params=captcha_result_payload).text
После получения ответа на CAPTCHA, необходимо передать его в виде токена в запросы на сайт. Токен CAPTCHA будет вставлен в запрос с параметрами, которые требует сайт для успешной авторизации. Обратите внимание, что на некоторых страницах Cloudflare могут быть дополнительные защиты, такие как JavaScript-челленджи, которые нужно будет обрабатывать с использованием более сложных инструментов, например, Selenium или Playwright.
Важно помнить, что использование таких методов должно строго соответствовать законодательству и правилам использования сайта. Автоматизированный обход защиты без разрешения владельцев ресурса может привести к юридическим последствиям или блокировке IP-адресов.
Сетевые запросы через Python: как правильно работать с cookies и заголовками
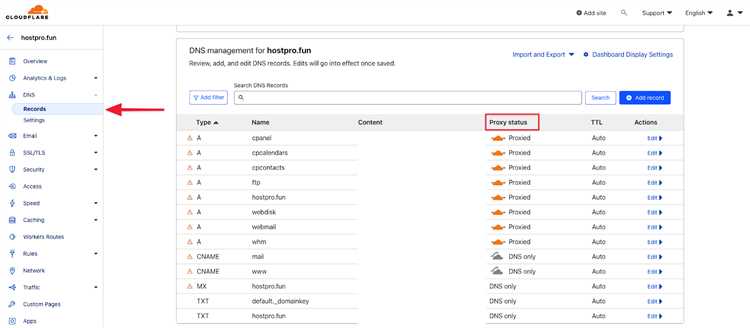
При работе с веб-ресурсами через Python важно учитывать правильную обработку cookies и заголовков, чтобы взаимодействие с сервером было успешным. Это ключевые элементы, влияющие на успешность выполнения запросов и обход защиты, такой как Cloudflare.
Заголовки HTTP-запросов (headers) передают серверу важную информацию о клиенте, а cookies позволяют поддерживать состояние сеанса между запросами. Чтобы корректно взаимодействовать с такими сервисами, как Cloudflare, необходимо учитывать несколько важных аспектов.
Работа с заголовками

Заголовки играют важную роль в имитации настоящего веб-браузера. Использование стандартных заголовков делает запросы менее подозрительными и помогает избежать блокировок со стороны защиты сайта.
- User-Agent: Этот заголовок идентифицирует тип браузера и операционную систему пользователя. При подделке User-Agent можно симулировать запросы от популярных браузеров.
- Accept: Указывает тип контента, который клиент готов принять. Это помогает серверу понять, какой формат ответа предоставить.
- Accept-Language: Важно для имитации языка клиента. Сервисы могут блокировать запросы, если язык отличается от ожидаемого.
- Connection: Заголовок управляет поведением соединения, например, сообщает серверу, следует ли его закрывать после завершения запроса.
- Referer: Используется для указания страницы, с которой пришел запрос. Если referer отсутствует или пустой, сайт может заблокировать запрос.
Для работы с заголовками в Python можно использовать библиотеку requests:
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Language': 'en-US,en;q=0.9',
'Connection': 'keep-alive',
'Referer': 'https://example.com'
}
response = requests.get('https://example.com', headers=headers)
Работа с cookies
Cookies – это данные, которые сервер отправляет на клиентскую сторону и которые сохраняются браузером. Эти данные могут быть использованы для поддержания сессии или передачи состояния между запросами. Для обхода защиты с помощью Cloudflare важно правильно работать с cookies, полученными в процессе взаимодействия с сервером.
- Сохранение cookies: После первого запроса с сервером можно сохранить cookies, чтобы использовать их в следующих запросах. Это позволяет избежать повторной аутентификации или других проверок.
- Передача cookies: Важно передавать cookies в заголовках запросов, чтобы сервер видел, что запрос исходит от того же клиента, что и предыдущий.
Пример работы с cookies с помощью библиотеки requests:
import requests
session = requests.Session()
# Выполняем первый запрос, чтобы получить cookies
response = session.get('https://example.com')
# Далее можем использовать эти cookies в других запросах
response2 = session.get('https://example.com/dashboard')
# Полученные cookies
cookies = session.cookies.get_dict()
print(cookies)
Для более сложных сценариев, таких как получение cookies после выполнения JavaScript, можно использовать библиотеку selenium, которая позволяет взаимодействовать с веб-страницами так, как это делает реальный пользователь.
Рекомендации
- Регулярно обновляйте заголовки и cookies, чтобы имитировать различные запросы от разных пользователей.
- Не забывайте обрабатывать ошибки сети и времени ожидания, чтобы запросы не зависали или не прекращались неожиданно.
- Применяйте задержки между запросами, чтобы избежать подозрительных действий, которые могут привести к блокировке.
- Используйте прокси-серверы или смену IP-адресов, чтобы снизить риск блокировки со стороны серверов, защищенных Cloudflare.
Корректная работа с заголовками и cookies – это важный элемент для успешного обхода защиты сайтов и взаимодействия с ними с помощью Python. Правильное использование этих инструментов позволяет обойти многие ограничения и гарантирует надежное выполнение запросов.
Автоматизация взаимодействия с JavaScript-челленджами Cloudflare с помощью Selenium
Cloudflare использует различные JavaScript-челленджи для защиты веб-ресурсов от автоматических ботов. В таких случаях взаимодействие с системой требует выполнения скриптов и обработки динамически генерируемых данных. Selenium – один из самых популярных инструментов для автоматизации браузерных действий, который может быть использован для обхода таких защит.
Для автоматизации взаимодействия с JavaScript-челленджами Cloudflare через Selenium нужно правильно настроить выполнение JavaScript в браузере. Selenium позволяет эмулировать действия пользователя, такие как клики, прокрутка страницы и выполнение скриптов, что делает возможным преодоление таких защит.
Первый шаг – настроить Selenium для использования с браузером, который поддерживает выполнение JavaScript, например, Chrome или Firefox. Для этого потребуется установить соответствующие драйверы, такие как chromedriver или geckodriver. Затем необходимо импортировать необходимые библиотеки и запустить Selenium WebDriver:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument('--headless') # Для работы без интерфейса
driver = webdriver.Chrome(options=options)
После этого можно взаимодействовать с веб-страницей, как с обычным пользователем. Например, если на странице присутствует JavaScript-челлендж, который блокирует доступ, Selenium может эмулировать клики и ожидание выполнения скриптов:
driver.get('https://example.com') # Открытие страницы
# Ожидание загрузки JavaScript-челленджа
driver.implicitly_wait(10) # Время ожидания появления элементов
# Взаимодействие с элементами, например, клик на кнопку
button = driver.find_element_by_id('challenge-button')
button.click()
# Ожидание завершения выполнения скриптов
driver.implicitly_wait(10)
Важно отметить, что Cloudflare может использовать дополнительные механизмы защиты, такие как проверки на поведение пользователя или капчи, что усложняет процесс автоматизации. В этом случае нужно дополнительно использовать решения для распознавания капчи или настройки более сложного взаимодействия с элементами страницы.
Для более точного контроля над JavaScript-челленджами рекомендуется использовать WebDriverWait для явных ожиданий, чтобы гарантировать, что все элементы страницы загружены и готовы к взаимодействию. Например:
from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC # Ожидание загрузки элемента WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.ID, 'challenge-button')) )
Также стоит помнить, что частое использование автоматизации может привести к блокировке IP-адреса или возникновения других защитных механизмов. Для этого рекомендуется использовать прокси-серверы или смену IP-адресов для предотвращения обнаружения бота.
Автоматизация взаимодействия с Cloudflare с использованием Selenium требует внимательности и тщательной настройки. При правильной конфигурации этот инструмент может эффективно обходить многие типы JavaScript-челленджей, создавая возможность для более гибкой работы с защищенными веб-ресурсами.
Использование прокси-серверов для обхода гео-ограничений Cloudflare
Cloudflare активно использует гео-ограничения для защиты сайтов от атак и контроля трафика, что может затруднить доступ к некоторым ресурсам для пользователей из определенных стран. Чтобы обойти такие блокировки, часто применяются прокси-серверы, которые позволяют скрывать реальное местоположение пользователя и передавать запросы через серверы в других регионах.
Одним из самых эффективных методов обхода гео-ограничений является использование частных прокси. В отличие от публичных, частные прокси предоставляют стабильность и возможность выбора местоположения сервера, что позволяет легко адаптироваться к различным регионам. Такие прокси могут быть использованы для подмены IP-адреса, что даёт возможность доступить сайты, блокированные для определённых стран.
Ротация IP-адресов также играет ключевую роль в обходе защиты Cloudflare. При использовании большого количества прокси-серверов с частой сменой IP-адресов можно значительно уменьшить риск блокировки. Важно настроить систему так, чтобы запросы не приходили с одного и того же IP-адреса слишком часто, что может привлечь внимание системы защиты.
Для автоматизации процессов обхода можно использовать Python-библиотеки, такие как requests или http.client, в сочетании с сервисами прокси. Пример кода для настройки прокси-сервера с использованием библиотеки requests:
import requests
proxies = {
'http': 'http://username:password@proxyserver:port',
'https': 'https://username:password@proxyserver:port'
}
response = requests.get('http://example.com', proxies=proxies)
print(response.text)
Использование ресидентных прокси – ещё одна альтернатива, которая предполагает использование реальных IP-адресов пользователей для обхода блокировок. Эти прокси менее подвержены обнаружению и блокировке, так как их активность выглядит более естественно для систем защиты Cloudflare.
Важно помнить, что для успешного обхода защиты Cloudflare необходимо не только менять IP-адреса, но и имитировать поведение обычного пользователя. Для этого можно использовать заголовки HTTP, такие как User-Agent, Referer, и другие, которые помогут скрыть автоматизированный характер запросов.
Таким образом, использование прокси-серверов с настройкой ротации IP и правильными HTTP-заголовками представляет собой один из наиболее эффективных способов обхода гео-ограничений Cloudflare, минимизируя риск блокировки и обеспечивая стабильный доступ к ограниченным ресурсам.
Реализация обхода защиты Cloudflare с помощью Python: пошаговая инструкция
Для успешного обхода защиты Cloudflare потребуется выполнить следующие шаги:
- Установка необходимых библиотек
- Использование CloudScraper
- Эмуляция браузера с помощью Selenium
- Обход JavaScript-челленджей
- Использование прокси-серверов и User-Agent
- Обработка куки и сессий
- Параллельная обработка запросов
Первоначально необходимо установить библиотеки, которые помогут взаимодействовать с веб-сайтами, защищенными Cloudflare. Рекомендуемые библиотеки: requests, selenium, cloudscraper.
pip install requests selenium cloudscraperОдним из простых решений является использование библиотеки cloudscraper, которая автоматически обходит защиту Cloudflare. Эта библиотека взаимодействует с механизмом защиты и эмулирует поведение браузера.
import cloudscraper
scraper = cloudscraper.create_scraper()
response = scraper.get('https://example.com')
print(response.text)Если подход с cloudscraper не срабатывает, следующим вариантом является использование selenium для автоматизации работы с браузером. Это помогает пройти через JavaScript-челленджи, которые использует Cloudflare.
Для работы с Selenium потребуется установить драйвер для браузера (например, ChromeDriver) и настроить его взаимодействие с Python.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
options = webdriver.ChromeOptions()
options.add_argument('--headless') # Без открытия окна браузера
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
driver.get('https://example.com')
print(driver.page_source)
driver.quit()Cloudflare часто использует JavaScript для защиты от автоматических запросов. Чтобы пройти через эти челленджи, необходимо использовать методы, имитирующие поведение пользователя. Например, можно использовать selenium, который позволяет обрабатывать такие запросы, выполняя JavaScript код на странице.
В некоторых случаях защита Cloudflare может блокировать запросы на основе IP-адресов. Для обхода этого можно использовать прокси-серверы или изменить User-Agent в заголовках HTTP-запросов.
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
proxies = {
'http': 'http://your_proxy:port',
'https': 'https://your_proxy:port'
}
response = requests.get('https://example.com', headers=headers, proxies=proxies)
print(response.text)Cloudflare может проверять куки и сессии, чтобы убедиться, что запросы исходят от реальных пользователей. Важно правильно управлять сессиями и куки для поддержания стабильного взаимодействия с защищенным сайтом.
session = requests.Session()
response = session.get('https://example.com', headers=headers)
cookies = response.cookies
print(cookies)Для ускорения обхода и обработки множества запросов можно использовать параллельную обработку с библиотеками, такими как concurrent.futures. Это позволит более эффективно обходить защиту на сайте, отправляя несколько запросов одновременно.
from concurrent.futures import ThreadPoolExecutor
def fetch_url(url):
return requests.get(url)
urls = ['https://example.com', 'https://example2.com']
with ThreadPoolExecutor() as executor:
results = executor.map(fetch_url, urls)
for result in results:
print(result.text)Учитывая динамичность защиты Cloudflare, важно тестировать различные методы обхода и использовать комбинированные подходы. Также стоит следить за актуальностью используемых библиотек, так как Cloudflare постоянно обновляет свои механизмы защиты.
Вопрос-ответ:
Как обойти защиту Cloudflare с помощью Python?
Обход защиты Cloudflare может быть сложной задачей, так как сервис активно использует различные методы для защиты от атак. Одним из основных способов является использование механизма обхода JavaScript, который требует выполнения некоторых вычислений на стороне клиента для подтверждения, что запрос не является атакой. В Python можно использовать библиотеки, такие как requests или selenium, для работы с такими страницами, а также для обработки cookies и заголовков, которые Cloudflare использует для проверки легитимности пользователей. Однако важно помнить, что использование таких методов без разрешения может нарушать правила и законы, регулирующие интернет-безопасность.
Какие библиотеки Python можно использовать для обхода защиты Cloudflare?
Для обхода защиты Cloudflare часто используют несколько популярных библиотек. Одна из них — это **requests**, которая позволяет отправлять HTTP-запросы и обрабатывать ответы. Однако если страница использует JavaScript для проверки, то для обхода защиты придется использовать более сложные инструменты, такие как **Selenium** или **Playwright**, которые могут эмулировать работу браузера, включая выполнение JavaScript. Еще одной полезной библиотекой является **cfscrape**, которая специально разработана для обхода Cloudflare, но ее поддержка может быть ограничена с течением времени.
Что делает защита Cloudflare, чтобы предотвратить автоматические запросы?
Cloudflare использует несколько технологий для защиты сайтов от автоматических запросов. Во-первых, это использование **JavaScript challenge**, который проверяет, может ли браузер выполнить определенные вычисления. Если запрос не проходит этот тест, сайт не будет доступен. Во-вторых, используются **cookies** и **IP-адреса**, чтобы отслеживать подозрительную активность, например, если запросы поступают с одного источника слишком часто. Также Cloudflare может внедрять капчи, которые требуют от пользователя подтверждения, что он не является ботом.
Можно ли использовать обход защиты Cloudflare для получения доступа к чужим данным?
Нет, использование обходных методов для получения доступа к чужим данным без разрешения является незаконным и нарушает правила и законы, такие как **защита личных данных** и **кибербезопасность**. Такие действия могут привести к серьезным правовым последствиям. Всегда следует помнить о необходимости уважать закон и этические нормы при работе с технологиями, особенно когда речь идет о безопасности и защите личных данных.
Как Cloudflare проверяет, что запрос сделан не ботом?
Cloudflare использует несколько механизмов для проверки запросов и отличия ботов от обычных пользователей. Один из таких методов — это выполнение **JavaScript challenge**, который генерирует уникальные вычисления, требующие выполнения в браузере. Кроме того, Cloudflare анализирует **IP-адреса** для выявления подозрительных аномалий, например, запросов с одного IP-адреса с высокой частотой. Также может использоваться **капча**, которая требует от пользователя подтверждения, что он не является ботом. Такие проверки помогают фильтровать автоматические запросы и защищать сайты от DDoS-атак и других угроз.