Особенность ascii() – преобразование символов с кодами выше 127 в форму \uXXXX или \UXXXXXXXX. Например, вызов ascii('Привет') вернёт '\\u041f\\u0440\\u0438\\u0432\\u0435\\u0442'. Это полезно при работе с интернациональными данными, когда необходимо обеспечить читаемость или избежать проблем с кодировкой в терминале или логах.
Как ascii обрабатывает кириллические и другие не-ASCII символы

Функция ascii() в Python возвращает строковое представление объекта, в котором все не-ASCII символы экранируются с помощью escape-последовательностей. Это касается символов с кодами выше 127, включая кириллицу, китайские и другие юникодные символы.
Например, результат вызова ascii('Привет') будет '\\u041f\\u0440\\u0438\\u0432\\u0435\\u0442'. Каждый символ кириллицы заменён на соответствующую \\uXXXX-форму, отражающую его Unicode-код.
Функция полезна для отладки, когда важно видеть точные коды символов. Однако для отображения или сериализации текста предпочтительнее использовать repr() или методы кодирования, например str.encode('unicode_escape'), если нужно сохранить читаемость для человека.
При работе с многоязычными данными следует помнить: ascii() не нарушает содержимое объекта, но делает его представление нечитаемым для большинства пользователей. Использовать её стоит только в специфических технических сценариях.
ascii(), repr() и str() возвращают строковые представления объектов, но работают по-разному при обработке не-ASCII символов.
ascii()всегда экранирует все не-ASCII символы. Например:ascii("Привет")вернёт'\\u041f\\u0440\\u0438\\u0432\\u0435\\u0442'.repr()старается сохранить точное представление объекта, включая кавычки и управляющие символы. Если строка содержит не-ASCII символы, они будут отображены как есть, если текущая кодировка это позволяет. Например:repr("Привет")может вернуть'Привет'или'\\u041f\\u0440\\u0438\\u0432\\u0435\\u0442'в зависимости от среды выполнения.
Применение ascii для подготовки данных к логированию

Использование ascii() позволяет избежать проблем с кодировкой в системах, не поддерживающих Unicode. Например, при логировании пользовательских вводов с символами кириллицы функция возвращает строку, в которой все нестандартные символы экранированы в виде escape-последовательностей:
ascii("Ошибка №5: неверный ввод") вернёт '\u041e\u0448\u0438\u0431\u043a\u0430 \u21165: \u043d\u0435\u0432\u0435\u0440\u043d\u044b\u0439 \u0432\u0432\u043e\u0434'.
Такой подход позволяет избежать некорректного отображения символов при анализе логов и сохраняет точность данных. Для логирования предпочтительно использовать ascii(obj) вместо str(obj), если источник данных содержит непредсказуемые символы, например ввод пользователей, сетевые сообщения или содержимое файлов с неустановленной кодировкой.
При использовании логгеров (например, logging) можно встроить ascii() в форматирование сообщений:
logger.info("Получены данные: %s", ascii(data))
Это особенно важно в распределённых системах и микросервисах, где консистентность логов критична для отладки. Применение ascii() снижает риск отказа лог-систем из-за ошибок кодировки и упрощает последующий парсинг логов автоматическими средствами.
Особенности работы ascii с управляющими символами
Функция ord() в Python позволяет получить ASCII-код символа, а также применима к управляющим символам, которые занимают ключевую роль в обработке строк. Однако важно понимать, что управляющие символы (с кодами от 0 до 31) не отображаются как видимые знаки, а выполняют различные служебные функции в текстовых данных, например, управление курсором, перенос строк и другие манипуляции с отображением текста.
Для более безопасной работы с управляющими символами рекомендуется использовать методы, которые позволяют корректно обрабатывать их в различных контекстах. Это может включать в себя использование регулярных выражений или библиотек для работы с текстом, которые автоматически экранируют управляющие символы, если это необходимо.
Использование ascii в сочетании с кодировками и декодированием
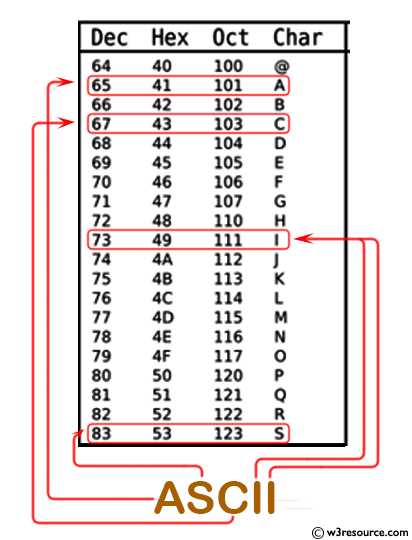
Функция ascii() в Python конвертирует объект в строку, представляющую его символы с использованием кодировки ASCII. Однако при работе с различными кодировками, такими как UTF-8 или Latin-1, важно учитывать, что символы, выходящие за пределы ASCII, могут не быть корректно обработаны, что требует применения методов декодирования и кодирования.
Для корректного преобразования между кодировками необходимо использовать методы encode() и decode(). Метод encode() преобразует строку в байты с указанной кодировкой, например, utf-8, а decode() выполняет обратное преобразование. Эти методы обеспечивают правильную обработку символов, не поддерживаемых стандартом ASCII, что важно для универсальности работы с различными языками и символами.
Когда вы пытаетесь использовать функцию ascii() с объектами, содержащими символы, не входящие в стандартный набор ASCII, они будут заменены на эквиваленты, начинающиеся с символа '\u' и указывающие на Unicode код точки. Однако для работы с кодировками важно помнить, что в случае попытки декодировать данные в кодировке, не соответствующей оригинальной кодировке, возникнут ошибки. Чтобы избежать таких ситуаций, перед декодированием всегда проверяйте кодировку исходных данных и используйте параметр errors для обработки возможных исключений, например, errors='ignore' или errors='replace'.
При работе с Unicode-строками, содержащими символы, не являющиеся частью ASCII, рекомендуется использовать кодировку UTF-8. Этот формат поддерживает все символы Unicode и при необходимости легко конвертируется в ASCII через функцию encode('ascii', 'ignore'), которая исключает символы, не относящиеся к ASCII.
Пример использования функции ascii() с декодированием и кодировкой:
text = "Привет, мир!"
encoded_text = text.encode('utf-8') # Кодируем строку в байты с UTF-8
ascii_representation = ascii(encoded_text.decode('utf-8')) # Декодируем и затем конвертируем в ASCII
В завершение, успешное использование функции ascii() в сочетании с кодировками и декодированием требует точного подхода к выбору кодировок и внимательного контроля над символами, выходящими за пределы стандартного набора ASCII. Это важно для корректной обработки данных и предотвращения ошибок при взаимодействии с текстами на разных языках.
Поведение ascii внутри f-строк и форматирования

Пример 1: Без использования ascii в f-строке:
value = '© Python'
print(f'The symbol is {value}')
Пример 2: С использованием ascii:
value = '© Python'
print(f'The symbol is {ascii(value)}')
Рекомендация: Используйте ascii() внутри f-строк в ситуациях, когда нужно гарантировать корректное отображение символов, особенно если вы работаете с непечатаемыми или расширенными символами Unicode, которые могут не поддерживаться в некоторых системах или IDE.
Вопрос-ответ:
Что делает функция `ascii()` в Python?
Функция `ascii()` в Python используется для преобразования объекта в строковое представление, при этом все символы, которые не могут быть отображены в ASCII, заменяются на их эквиваленты в виде escape-последовательностей. Это полезно, когда необходимо безопасно вывести строку, содержащую символы, которые могут не поддерживаться в стандартных ASCII-шрифтах.
Как работает функция `ascii()` с нестандартными символами?
Когда функция `ascii()` сталкивается с символами, которые не входят в стандартный набор ASCII (например, с символами Юникода), она заменяет их на escape-последовательности. Например, символы с диакритическими знаками или смайлики будут представлены в виде `\uXXXX`, где `XXXX` — это код символа в шестнадцатеричной форме. Это позволяет избежать проблем с отображением таких символов в некоторых средах.
Можно ли использовать `ascii()` для преобразования целых объектов, например, списков или словарей?
Да, функция `ascii()` может применяться к любым объектам в Python, не только к строкам. При применении к сложным объектам, таким как списки, кортежи или словари, она вернёт строковое представление этих объектов, преобразуя все символы, не входящие в стандартный ASCII, в escape-последовательности. Это делает вывод таких объектов безопасным для использования в средах, которые поддерживают только ASCII.
Что произойдет, если использовать функцию `ascii()` с символами, которые уже являются ASCII?
Если в строке или объекте содержатся только символы, поддерживаемые ASCII, функция `ascii()` просто вернёт исходную строку без изменений. Она применяет преобразование только к тем символам, которые выходят за пределы стандартного ASCII. Таким образом, если все символы строки находятся в пределах ASCII, результат будет идентичен исходной строке.
Какую роль играет функция `ascii()` при работе с текстами на других языках, например, с русским?
При работе с текстами на других языках, например, с русским, функция `ascii()` заменяет все символы, которые не являются частью латинского алфавита, на их escape-последовательности. Например, русские буквы будут преобразованы в строки вида `\uXXXX`, где `XXXX` — это шестнадцатеричный код символа в Юникоде. Это позволяет отображать текст, содержащий нелатинские символы, в средах, которые поддерживают только ASCII, но делает такой текст менее читаемым для человека.