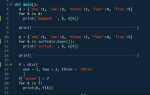
Современный backend-разработчик на Python обязан уверенно владеть как синтаксисом языка, так и основными библиотеками, активно применяемыми в серверной разработке. В первую очередь это FastAPI, Django и Flask – каждый из них решает специфические задачи, от микросервисов до комплексных монолитных систем. Навыки построения REST и GraphQL API, а также умение работать с асинхронным кодом (через asyncio) – неотъемлемые компоненты современного стека.
Глубокое понимание работы с базами данных критично. Разработчик должен уметь проектировать и оптимизировать схемы БД, писать сложные SQL-запросы, а также работать с ORM-библиотеками вроде SQLAlchemy или Django ORM. Знание PostgreSQL предпочтительно, учитывая его широкое распространение и функциональные возможности.
Инструменты контейнеризации и оркестрации, такие как Docker и Kubernetes, стали стандартом. Backend-специалист обязан уметь собирать образы, писать Dockerfile и docker-compose, а также развертывать сервисы в кластере. Понимание CI/CD – как минимум на уровне настройки пайплайнов через GitHub Actions или GitLab CI – требуется даже на этапе разработки.
Тестирование – основа стабильного backend. Знание pytest, умение писать unit- и integration-тесты, использовать mock-объекты, обеспечивают контроль качества и предотвращают регрессии. Помимо этого, умение работать с логированием и метриками (например, через Prometheus и Grafana) позволяет своевременно обнаруживать и устранять ошибки в продакшене.
И наконец, разработчик должен разбираться в вопросах безопасности: защита API от CSRF и XSS, правильная работа с CORS, хранение чувствительных данных и управление доступом через OAuth 2.0 или JWT – это не факультативные навыки, а необходимые требования к профессионалу.
Настройка маршрутов и обработка HTTP-запросов с использованием фреймворков
Бэкенд-разработчик на Python обязан уверенно настраивать маршруты и обрабатывать HTTP-запросы, используя возможности фреймворков, таких как FastAPI, Flask и Django. Важно понимать, как реализуются методы GET, POST, PUT, DELETE и как обрабатывать входящие параметры: query-параметры, path-переменные, заголовки и тело запроса.
В FastAPI настройка маршрутов осуществляется через декораторы @app.get(), @app.post() и аналогичные. Используются аннотации типов, что позволяет валидировать входные данные без лишнего кода. Для тела запроса применяются модели на базе Pydantic, что критично при работе с JSON API.
Во Flask маршруты регистрируются с помощью @app.route(), при этом параметры запроса извлекаются через request.args, request.form или request.get_json(). Flask не содержит встроенной валидации, поэтому её необходимо реализовывать вручную или с использованием сторонних библиотек, например, Marshmallow.
В Django маршруты описываются в urls.py с привязкой к конкретным view-функциям или классам. Для REST API обычно используется Django REST Framework, где маршрутизация осуществляется через path() или routers.DefaultRouter, а методы запросов обрабатываются в методах get(), post() и др. сериализаторы позволяют валидировать входные данные и формировать ответы в формате JSON.
Особое внимание следует уделять правильной обработке ошибок: возврату статусов 4xx/5xx, структурированным сообщениям об ошибках и логированию исключений. Также важно уметь работать с middleware, если требуется предварительная обработка запроса или модификация ответа.
Уверенное владение маршрутизацией и работой с HTTP-запросами в выбранном фреймворке – необходимое условие для разработки надёжных API и микросервисов.
Организация структуры проекта и управление зависимостями
Минимально жизнеспособная структура backend-проекта на Python должна включать директории app/ (исходный код), tests/ (тесты), migrations/ (если используется ORM), а также файл pyproject.toml для описания зависимостей и метаданных.
Рекомендуется придерживаться разделения ответственности по слоям: routers/ – для маршрутов, services/ – для бизнес-логики, repositories/ – для работы с базой данных, schemas/ – для Pydantic-моделей, core/ – для конфигурации, подключения к БД и middleware.
Не следует смешивать инфраструктурный код с бизнес-логикой. Каждый модуль должен быть изолирован: логика работы с БД не должна напрямую зависеть от фреймворка. Это позволяет упростить тестирование и переход между технологиями.
Для управления зависимостями рекомендуется использовать Poetry. Он позволяет зафиксировать версии в poetry.lock и работать в рамках виртуального окружения. Альтернатива – pip-tools с файлами requirements.in и requirements.txt. Использование virtualenv или venv обязательно для изоляции окружения.
Зависимости делятся на производственные и девелоперские. В pyproject.toml или requirements-dev.txt выносится всё, что не требуется в проде: линтеры (flake8, ruff), тестовые фреймворки (pytest), генераторы документации.
Импорты должны быть абсолютными с точки зрения корня проекта. Для этого в PYTHONPATH явно указывается корневая директория. Это устраняет проблемы с относительными импортами при запуске из разных точек входа.
В качестве точки входа предпочтительнее использовать main.py или cli.py, расположенные в корне. Они должны лишь инициировать запуск приложения, делегируя всю остальную логику в app/.
Каждая часть структуры должна иметь четкую цель и минимальные зависимости. Изменение одного компонента не должно касаться других. Это принцип инкапсуляции, обеспечивающий масштабируемость и сопровождение проекта.
Работа с базами данных через ORM и чистые SQL-запросы

Python-разработчик обязан уверенно использовать ORM-библиотеки (например, SQLAlchemy или Django ORM) для описания моделей и взаимодействия с СУБД на высоком уровне абстракции. Это упрощает миграции, обеспечивает кросс-СУБД совместимость и ускоряет разработку. Однако для сложных запросов или оптимизации производительности требуется знание чистого SQL.
При работе с ORM важно уметь:
- Настраивать связи между моделями: OneToOne, ForeignKey, ManyToMany
- Использовать аннотации, агрегации и подзапросы (Subquery, OuterRef)
- Избегать N+1 проблем с помощью select_related и prefetch_related
- Писать кастомные менеджеры и QuerySet’ы для инкапсуляции логики выборок
Знание SQL необходимо для:
- Анализа и оптимизации EXPLAIN-планов выполнения
- Написания триггеров, процедур и представлений при необходимости
- Создания индексов по составным и функциональным ключам
- Реализации сложных JOIN-запросов и оконных функций
Пример: ORM-запрос с аннотацией и агрегацией в Django:
Book.objects.values('author__name').annotate(total=Count('id')).order_by('-total')Эквивалентный SQL:
SELECT author.name, COUNT(book.id) AS total
FROM book
JOIN author ON book.author_id = author.id
GROUP BY author.name
ORDER BY total DESC;Навыки взаимодействия с БД включают также умение работать с транзакциями (atomic, savepoint), управлять уровнем изоляции, использовать пул соединений и профилировать запросы. Backend-разработчик должен не просто использовать ORM, а понимать, как она трансформирует запросы и влияет на производительность.
Реализация авторизации, аутентификации и управления сессиями
Backend-разработчик на Python должен уметь реализовать безопасную и масштабируемую систему аутентификации, авторизации и управления сессиями, используя современные подходы и инструменты.
- Использовать хеширование паролей через
bcryptилиargon2, исключив хранение паролей в открытом виде.hashlibиmd5– недопустимы. - Применять библиотеку
Passlibдля унифицированного хеширования с настройкой параметров безопасности (cost, salt). - Для аутентификации – реализовывать проверку учетных данных с учетом задержек (rate limiting, защита от brute-force) через
Redisилиfail2ban-подобные механизмы. - Авторизацию строить на ролевой модели (RBAC) или политике (ABAC), используя зависимости в FastAPI или декораторы в Flask для ограничения доступа к ресурсам.
- При использовании JWT:
- Хранить
accessиrefreshтокены раздельно. - Применять короткий срок жизни
access token(5–15 минут), долгий – дляrefresh token. - Добавлять
jtiи хранить использованные токены в черном списке (blacklist).
- Хранить
- При использовании cookie-сессий:
- Включать флаги
HttpOnly,Secure,SameSite=Strict. - Шифровать содержимое cookie или использовать идентификаторы, ссылающиеся на серверное хранилище сессий (например, Redis).
- Включать флаги
- Обеспечить выход из системы (logout) с удалением refresh токена и/или инвалидацией серверной сессии.
- Применять CSRF-защиту при работе с cookie через токены и middleware.
В проектах на FastAPI использовать Depends и OAuth2PasswordBearer для интеграции аутентификации. В Django – модуль django.contrib.auth и кастомные AuthenticationBackend при необходимости.
Обязательна логика автоматического продления сессии (sliding expiration) и безопасного хранения токенов на клиенте (в случае SPA – не в localStorage, а через httpOnly-cookie).
Использование очередей и фоновая обработка задач
Celery позволяет определять задачи как обычные Python-функции с декоратором @task. Настоятельно рекомендуется указывать acks_late=True для задач, чтобы гарантировать переотправку при сбое исполнителя. Базовая структура включает worker-процессы, брокер сообщений и, при необходимости, отдельный планировщик (beat) для периодических задач.
Для мониторинга используется Flower или интеграция с Prometheus через кастомные метрики. Производительность масштабируется горизонтально за счет увеличения количества воркеров. Следует учитывать idempotent-характер задач – при повторном выполнении они не должны нарушать консистентность данных. Пример: перед созданием записи проверять уникальность ключа.
Альтернативы Celery – RQ (Redis Queue) и Dramatiq – проще в настройке, но ограничены функционально. В проектах с высокой нагрузкой применяют Kafka как брокер и Faust или AIOKafka для stream-процессинга. Эти подходы подходят для realtime-аналитики и событийных систем.
В Django предпочтительно выносить все задачи вне view-функций и вызывать их асинхронно. Flask требует отдельной интеграции, но структура схожа. Код задач должен быть независим от контекста HTTP-запроса и включать механизмы логирования и retries. Четкое разделение на синхронный слой (fast response) и асинхронный (resource-heavy logic) – основа стабильной архитектуры.
Логирование, мониторинг и отслеживание ошибок в продакшене
Для обеспечения стабильности и производительности приложения на Python в продакшене необходимо правильно настроить логирование, мониторинг и отслеживание ошибок. Эти инструменты позволяют оперативно выявлять и устранять проблемы, минимизируя их влияние на пользователей.
Логирование

Логирование – это основа для отслеживания работы приложения. Правильная настройка логирования помогает в поиске и устранении ошибок, а также в анализе производительности системы.
- Использование библиотеки logging: стандартная библиотека Python logging предоставляет гибкие механизмы для создания логов на разных уровнях (DEBUG, INFO, WARNING, ERROR, CRITICAL). Убедитесь, что настройки логирования соответствуют нуждам вашего проекта. Например, DEBUG логи не должны быть включены в продакшене.
- Структурированные логи: Используйте JSON формат для логов, чтобы облегчить их дальнейшую обработку и интеграцию с системами мониторинга и анализа. Пример: {«timestamp»: «2025-05-06T14:00:00Z», «level»: «ERROR», «message»: «Ошибка соединения с БД», «details»: {«host»: «db_server»}}
- Логирование ошибок и исключений: Для каждого необработанного исключения обязательно логируйте стек-трейс. Это помогает быстрее находить место возникновения ошибки и устранять её.
Мониторинг

Мониторинг позволяет отслеживать состояние системы в реальном времени, выявлять возможные сбои или ухудшение производительности.
- Инструменты мониторинга: Используйте системы мониторинга, такие как Prometheus, Grafana или Datadog. Эти инструменты позволяют настроить метрики для отслеживания состояния приложения, базы данных и серверов.
- Мониторинг производительности: Отслеживайте метрики, такие как загрузка процессора, использование памяти, время отклика и количество запросов. Важным моментом является анализ пиковых нагрузок и корректировка настроек масштабирования.
- Мониторинг зависимостей: Важно следить за состоянием всех сторонних сервисов, таких как базы данных, очереди сообщений, внешние API. Используйте инструменты для проверки их доступности и производительности.
Отслеживание ошибок
Отслеживание ошибок важно для быстрого реагирования на сбои в продакшене и минимизации их воздействия на пользователей.
- Использование Sentry или аналогичных сервисов: Эти сервисы позволяют автоматически отслеживать и классифицировать ошибки в приложении. Они обеспечивают детализированные отчеты с трассировками стека, чтобы разработчики могли быстро диагностировать проблему.
- Обработка ошибок в коде: При обработке исключений используйте подходы, которые позволяют избежать потери данных и дают возможность пользователю продолжить взаимодействие с системой. В случае критичных ошибок отправляйте уведомления разработчикам и системным администраторам.
- Тестирование на стадии разработки: Применение статического анализа, юнит-тестов и интеграционных тестов позволяет заранее выявить и исправить потенциальные ошибки, прежде чем они попадут в продакшен.
Практические рекомендации
- Не забывайте настроить уведомления для критичных ошибок, чтобы оперативно реагировать на проблемы.
- Логи и метрики должны быть доступны только авторизованным пользователям, чтобы предотвратить утечку конфиденциальной информации.
- Используйте распределенные системы логирования и мониторинга для больших приложений и микросервисных архитектур.
- Рекомендуется хранить логи в централизованных системах, таких как ELK (Elasticsearch, Logstash, Kibana), чтобы обеспечить удобный поиск и анализ.
- Регулярно проводите ревизию настроек мониторинга, чтобы не упустить важные события.
Написание и запуск автоматических тестов для серверной логики
Использование библиотеки unittest – стандартная библиотека для написания тестов в Python. Она предоставляет удобные инструменты для организации тестов и проверки результатов. Основные элементы библиотеки – это классы, наследующиеся от unittest.TestCase, и методы, начинающиеся с префикса test_. Тесты следует писать в отдельных модулях, чтобы облегчить их поддержку и масштабируемость проекта.
Mock-объекты для изоляции тестируемых компонентов помогают протестировать серверную логику, не зависимую от внешних сервисов (например, базы данных или API). Для этого можно использовать библиотеку unittest.mock. С помощью Mock можно имитировать поведение внешних зависимостей, проверяя логику без необходимости в реальных подключениях или ресурсах.
Тестирование через API с использованием библиотеки requests или pytest позволяет проверить взаимодействие серверной логики с клиентом. Важно учитывать создание тестовых данных и подготовку тестовой среды, например, с помощью Docker, чтобы каждый запуск тестов был изолирован и не зависел от состояния внешней системы.
Покрытие тестами всех важных участков кода необходимо для того, чтобы быть уверенным в корректной работе приложения. Важно тестировать как положительные, так и отрицательные сценарии – ошибки, исключения и некорректные данные. Логика обработки исключений должна быть проверена в отдельных тестах, чтобы убедиться, что приложение правильно реагирует на ошибки.
Интеграционные и нагрузочные тесты необходимы для оценки взаимодействия различных компонентов системы и её производительности при реальных нагрузках. Интеграционные тесты проверяют работу сервера в целом, включая работу с базой данных и сторонними сервисами. Нагрузочные тесты можно запускать с использованием библиотек, таких как locust или pytest-benchmark.
Запуск тестов в CI/CD-пайплайне позволяет автоматизировать процесс проверки кода при каждом изменении. Настройка интеграции с такими инструментами, как Jenkins, GitLab CI или GitHub Actions, помогает запускать тесты при каждом пуше в репозиторий, что ускоряет выявление ошибок на ранних стадиях разработки.
Вопрос-ответ:
Какие основные навыки необходимы backend-разработчику на Python?
Backend-разработчик на Python должен обладать хорошими знаниями языка Python, включая работу с фреймворками, такими как Django или Flask. Он должен разбираться в принципах разработки серверной части, таких как REST API, а также уметь работать с базами данных, например, PostgreSQL или MySQL. Важно понимать основы работы с многозадачностью и асинхронностью в Python, а также иметь опыт с системами контроля версий, например, Git. Знания в области тестирования, контейнеризации (например, с Docker) и понимание принципов DevOps также будут полезны.
Какие фреймворки для Python должны быть знакомы backend-разработчику?
Основные фреймворки, с которыми должен быть знаком backend-разработчик на Python, — это Django и Flask. Django является более крупным и комплексным фреймворком, который включает в себя множество встроенных решений, таких как система авторизации и администрирования. Flask, наоборот, предоставляет минималистичный подход, позволяя разработчику гибко выбирать компоненты для проекта. В зависимости от задачи, выбор фреймворка может варьироваться, но оба фреймворка являются основными для большинства backend-разработок на Python.
Какие базы данных важно знать backend-разработчику на Python?
Backend-разработчик на Python должен хорошо разбираться в работе с реляционными базами данных, такими как PostgreSQL и MySQL. Знание SQL-запросов и принципов работы с транзакциями, индексами и нормализацией данных — обязательное требование. Также полезно иметь представление о NoSQL базах данных, таких как MongoDB, особенно если проект предполагает работу с неструктурированными данными. Важно уметь работать с ORM (Object-Relational Mapping), такими как SQLAlchemy или Django ORM, для упрощения взаимодействия с базой данных.
Почему знание асинхронности важно для backend-разработчика на Python?
Асинхронность в Python позволяет обрабатывать большое количество запросов одновременно, что особенно важно для высоконагруженных приложений. Знание асинхронных библиотек, таких как asyncio или библиотеки для асинхронных веб-серверов, как FastAPI, помогает эффективно использовать ресурсы сервера, увеличивая производительность и снижая время отклика. Это особенно важно при работе с API, микросервисами и другими типами сервисов, где требуется высокая скорость и отзывчивость системы.
Какие технологии и инструменты могут быть полезны backend-разработчику на Python?
Backend-разработчику на Python могут быть полезны различные инструменты для тестирования (например, PyTest или UnitTest), для работы с контейнерами (Docker), а также для автоматизации развёртывания (CI/CD с использованием Jenkins, GitLab CI или Travis CI). Знание систем контроля версий, таких как Git, обязательно. Также важно понимать принципы работы с серверными веб-серверами, например, Nginx или Gunicorn, а также уметь работать с различными типами кэширования (Redis или Memcached) для ускорения работы приложения. Навыки работы с облачными сервисами, такими как AWS, Azure или Google Cloud, тоже могут быть полезными.
Какие основные навыки нужны backend-разработчику на Python?
Для того чтобы стать успешным backend-разработчиком на Python, важно освоить несколько ключевых навыков. Во-первых, необходимо хорошо знать сам Python, включая его синтаксис и особенности работы с библиотеками и фреймворками, такими как Django или Flask. Также нужно разбираться в базах данных, как реляционных (например, PostgreSQL, MySQL), так и нереляционных (например, MongoDB). Работа с API, опыт работы с REST и знание принципов построения архитектуры приложений — важные аспекты для разработчика. Не менее важно умение тестировать код, использовать инструменты для автоматизации, а также работать с системами контроля версий, такими как Git. Знание принципов безопасности, таких как защита от SQL-инъекций и безопасное хранение паролей, также критично. Кроме того, важно иметь представление о контейнеризации и работе с Docker, а также о CI/CD процессах, чтобы код автоматически тестировался и деплоился на сервер.»