Метод split() в Python применяется для разбиения строк на части по заданному разделителю. Он возвращает список подстрок, что делает его полезным для парсинга данных, обработки пользовательского ввода и анализа текстовых файлов.
Если не указать аргумент, split() по умолчанию делит строку по пробелам, игнорируя множественные пробелы и начальные/конечные пробельные символы. Это особенно удобно при обработке пользовательского ввода, где количество пробелов непредсказуемо:
» пример строки с пробелами «.split() вернёт [‘пример’, ‘строки’, ‘с’, ‘пробелами’].
Можно явно указать разделитель, например запятую, чтобы разбить CSV-строку: «яблоко,груша,слива».split(‘,’) даст [‘яблоко’, ‘груша’, ‘слива’].
С помощью второго аргумента – maxsplit – можно ограничить количество разбиений. Выражение «a:b:c:d».split(‘:’, 2) вернёт [‘a’, ‘b’, ‘c:d’], оставляя оставшуюся часть строки как есть после указанного числа разбиений.
Функция split() не изменяет исходную строку, так как строки в Python неизменяемы. Чтобы сохранить результат, его необходимо присвоить переменной.
Если строка не содержит указанный разделитель, метод вернёт список из одного элемента – исходной строки. Это позволяет безопасно применять split() без предварительной проверки наличия разделителя.
Для сложных сценариев, где разделители – это регулярные выражения, стоит использовать функцию re.split() из модуля re. Она поддерживает более гибкое разбиение, включая множественные и комбинированные символы-разделители.
Как разделить строку по пробелам с помощью split()
Метод split() без аргументов разделяет строку по всем последовательностям пробельных символов. Это включает пробелы, табуляции и переводы строк. Поведение метода основано на стандартной функции str.split(), встроенной в Python.
- Если в строке несколько пробелов подряд – метод автоматически исключает пустые элементы из результата.
- Тип возвращаемого значения – список (
list), содержащий подстроки без пробелов.
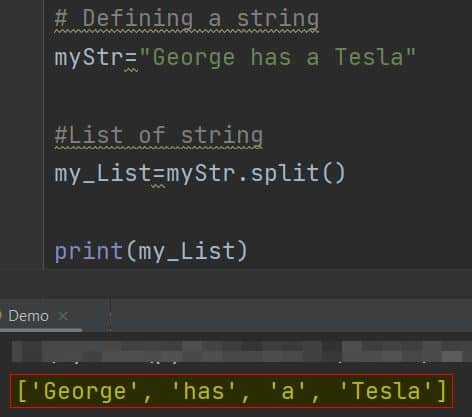
текст = "Python – мощный язык программирования"
результат = текст.split()
print(результат)Результат:
['Python', '–', 'мощный', 'язык', 'программирования']Если требуется ограничить количество разбиений, используется параметр maxsplit. Он указывает, сколько раз произойдёт разбиение слева направо.
текст = "один два три четыре"
результат = текст.split(maxsplit=2)
print(результат)Результат:
['один', 'два', 'три четыре']- Если указать
maxsplit=0, вернётся список с одной строкой – исходным значением. - Указание большого значения
maxsplitне вызывает ошибку – метод просто разбивает всё, что возможно.
Рекомендуется использовать split() без аргументов, когда необходимо разбить текст по любым пробельным символам, особенно если формат ввода непредсказуем.
Разделение строки по пользовательскому разделителю
Метод split() позволяет указать любой символ или последовательность символов в качестве разделителя. Это удобно при работе с нестандартными форматами данных, например, CSV-файлами с нестандартными разделителями или логами с разделителями вроде » | «.
Пример: строка «apple|banana|cherry» разделяется по символу «|» следующим образом:
text = «apple|banana|cherry»
result = text.split(«|»)
После выполнения переменная result содержит список: [«apple», «banana», «cherry»]. Метод не включает сам разделитель в результат.
Для строк с несколькими символами в качестве разделителя можно использовать последовательность, например:
log = «INFO — 2025-05-06 — Process started»
parts = log.split(» — «)
Результат: [«INFO», «2025-05-06», «Process started»].
Если разделитель отсутствует в строке, метод вернёт список с одним элементом – исходной строкой.
Рекомендуется использовать явное указание разделителя при парсинге строк с предсказуемым форматом. Это исключает ошибки при наличии лишних пробелов или других символов, часто встречающихся при использовании разделителя по умолчанию.
Ограничение количества разбиений с помощью параметра maxsplit
Метод split() принимает необязательный параметр maxsplit, задающий максимальное количество разбиений строки. Это позволяет контролировать длину возвращаемого списка и сохранить остаток строки в последнем элементе.
Пример: пусть дана строка "apple,orange,banana,grape". Если применить split(',', 2), результат будет: ['apple', 'orange', 'banana,grape']. Первые два запятые становятся точками разбиения, а оставшаяся часть сохраняется без изменений.
Использование maxsplit полезно при обработке строк с переменным количеством разделителей, например, в логах или CSV, где важна только часть данных.
Рекомендуется:
- Указывать
maxsplit=1при разбиении строк ключ-значение, чтобы избежать потерь данных с дополнительными разделителями. - Проверять длину результата после
split()сmaxsplit, чтобы избежать выхода за границы при обращении по индексам.
Если параметр maxsplit не указан или равен -1, разбиения происходят до конца строки, как при обычном использовании split().
Обработка строк с несколькими подряд идущими разделителями
При разделении строки методом split() с указанием символа-разделителя, Python по умолчанию не игнорирует пустые элементы между несколькими подряд идущими разделителями. Это важно учитывать при обработке данных, например, при разборе логов или CSV-файлов с нестабильной структурой.
Пример: ‘one,,two,,,three’.split(‘,’) вернёт [‘one’, », ‘two’, », », ‘three’]. Пустые строки сохраняются, что может привести к неверной интерпретации данных, если ожидается строгое количество полей.
Для устранения пустых элементов используется генераторное выражение: [x for x in s.split(‘,’) if x]. Оно удалит все пустые строки: [‘one’, ‘two’, ‘three’].
Если нужно сохранить только значимые данные, но при этом не потерять пустые поля с пробелами, лучше использовать метод strip() внутри выражения: [x.strip() for x in s.split(‘,’) if x.strip()].
При работе с неоднородными разделителями или множеством пробелов используйте re.split() из модуля re. Пример: re.split(r'[,\s]+’, s) – разбивает строку по запятым и пробелам, независимо от количества подряд идущих символов.
Если разделитель – пробел и не указан явно: s.split() автоматически удаляет лишние пробелы и не возвращает пустые строки. Пример: ‘ a b c ‘.split() → [‘a’, ‘b’, ‘c’].
Для предварительной очистки строки используйте s.strip(), чтобы убрать начальные и конечные разделители, и только затем применять split(), особенно если важна точность в количестве элементов.
Применение split() к строкам с символами переноса строки
Метод split() эффективно разделяет строки, содержащие символы переноса строки (\n), позволяя обрабатывать текст построчно без дополнительных библиотек. Это особенно полезно при работе с данными, полученными из файлов или сетевых источников, где строки разделяются переводом строки.
По умолчанию split() разбивает строку по пробелам и символам перевода строки, если не задан аргумент. Однако для явного разделения по строкам рекомендуется использовать split('\n'), чтобы сохранить пустые строки между переносами и избежать потери данных.
Пример:
text = "Первая строка\nВторая строка\n\nЧетвёртая строка"
lines = text.split('\n')
print(lines)Результат: ['Первая строка', 'Вторая строка', '', 'Четвёртая строка']. Пустой элемент указывает на наличие двойного переноса, что может быть критично, например, при разметке текстов.
Если требуется игнорировать пустые строки, применяют генератор списков: [line for line in text.split('\n') if line].
Также возможно использование splitlines(), но он отличается от split('\n'): splitlines() удаляет символы переноса и автоматически обрабатывает \r\n и \r. Для строгой работы с \n следует предпочитать split('\n').
Рекомендовано: использовать split('\n') при анализе строго форматированных текстов и там, где важна точность позиционирования строк, включая пустые элементы.
Разница между split() и splitlines() при работе с текстовыми файлами
Функции split() и splitlines() в Python часто используются при обработке текстовых файлов, но их назначение и применение существенно различаются.
Метод split() разделяет строку по указанному разделителю и возвращает список строк. Он полезен, когда нужно разбить текст на части, используя определённый символ или строку. Например, при чтении CSV-файлов или других форматов с явными разделителями, split() позволяет точно контролировать, по какому символу или подстроке происходит разбиение.
Пример использования split() для обработки данных в CSV-файле:
with open('data.csv', 'r') as file:
for line in file:
columns = line.split(',')
print(columns)Метод splitlines() предназначен для разбиения строки на подстроки, основываясь на символах новой строки (например, \n). Этот метод автоматически обрабатывает различные типы разделителей строк (например, \r\n или \n в зависимости от операционной системы), что делает его удобным для работы с текстовыми файлами, где строки разделяются символами новой строки.
Пример использования splitlines() для обработки текста с построчным разбиением:
with open('data.txt', 'r') as file:
content = file.read()
lines = content.splitlines()
for line in lines:
print(line)Основное различие между split() и splitlines() заключается в том, что split() требует указания конкретного разделителя, а splitlines() автоматически разделяет строки по символам новой строки, без необходимости указывать их явно. Это делает splitlines() более удобным для работы с построчными данными, в то время как split() подходит для случаев, когда необходимо разделить строку по специфичному разделителю.
Разделение строки с удалением лишних пробелов
Функция split() в Python позволяет разделить строку на подстроки, но по умолчанию она оставляет пробелы между словами. Для удаления лишних пробелов можно использовать параметры функции или дополнительные методы. Рассмотрим, как эффективно разделить строку, исключив ненужные пробелы.
Если в строке имеются множественные пробелы между словами, то стандартный метод split() разделит строку по каждому пробелу, оставив пустые строки в результатах. Чтобы этого избежать, необходимо воспользоваться параметром split(), который удалит лишние пробелы.
split()без параметров автоматически удаляет начальные и конечные пробелы, но не избавляется от лишних пробелов внутри строки.- Для удаления всех лишних пробелов можно использовать регулярные выражения с
re.split()или предварительно привести строку к нужному виду с помощью методаstrip()иreplace().
Пример использования метода split() для удаления лишних пробелов:
text = " Пример строки с лишними пробелами "
result = ' '.join(text.split())
print(result)
В этом примере мы сначала разделяем строку с помощью split(), а затем используем ' '.join() для объединения элементов, что позволяет избавиться от лишних пробелов внутри строки.
Можно также использовать регулярные выражения для более гибкой обработки строки. Метод re.sub() позволяет заменить несколько пробелов на один, что также помогает удалить лишние пробелы.
import re
text = " Пример строки с лишними пробелами "
result = re.sub(r'\s+', ' ', text).strip()
print(result)
Здесь re.sub(r'\s+', ' ', text) заменяет все группы пробелов на один, а strip() удаляет начальные и конечные пробелы.
Для удаления пробелов в начале и конце строки можно использовать метод strip(), который не влияет на пробелы внутри текста:
text = " Пример строки с пробелами в начале и конце "
result = text.strip()
print(result)
Таким образом, для эффективного разделения строки с удалением лишних пробелов важно правильно комбинировать методы split(), join(), re.sub() и strip().
Использование split() при парсинге данных из CSV и логов
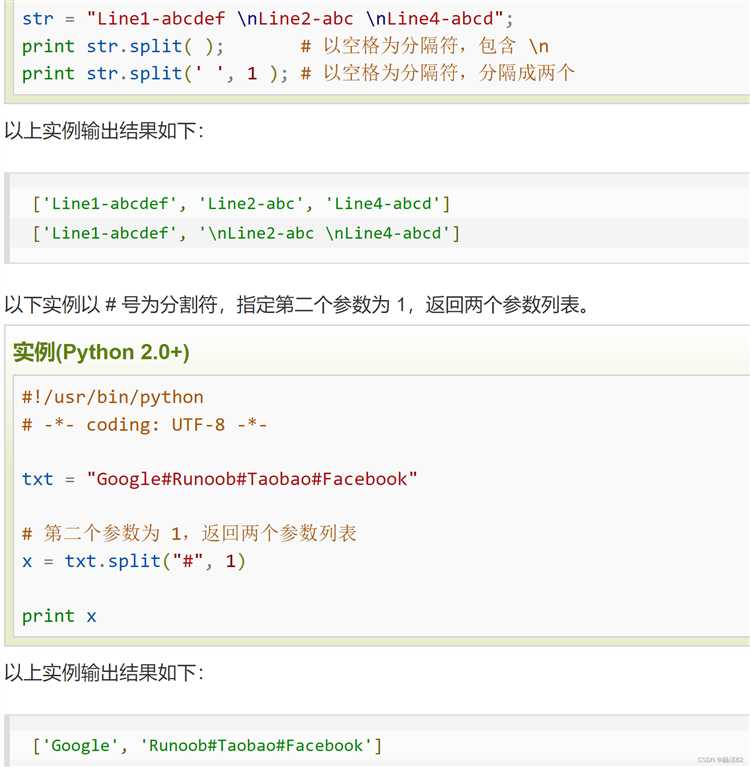
Для парсинга CSV-файлов с использованием split(), важно понимать, что данные обычно разделяются запятыми, но могут встречаться и другие разделители, такие как табуляция или точка с запятой. Допустим, у нас есть строка из CSV-файла:
"Иван, 25, Москва, Программист"
Используя split(), мы можем разделить её на отдельные элементы:
data = "Иван, 25, Москва, Программист"
fields = data.split(", ")
print(fields)
Результат:
['Иван', '25', 'Москва', 'Программист']
Важно учитывать, что при парсинге CSV-файлов часто встречаются кавычки, которые могут содержать запятые внутри значений. В таких случаях можно использовать специализированные библиотеки, например, csv, чтобы избежать неправильной обработки данных.
Для парсинга логов, где строки могут иметь различные форматы, split() также помогает извлекать полезную информацию. Например, если строки в логах разделяются пробелами или другими символами, можно использовать соответствующий разделитель. Рассмотрим лог, в котором данные разделены пробелами:
2025-05-06 14:30:12 ERROR Ошибка подключения к серверу
Чтобы извлечь информацию о времени и типе ошибки, можно воспользоваться следующим кодом:
log = "2025-05-06 14:30:12 ERROR Ошибка подключения к серверу"
parts = log.split(" ", 3)
print(parts)
Результат:
['2025-05-06', '14:30:12', 'ERROR', 'Ошибка подключения к серверу']
Здесь мы ограничили количество разделений до 3, чтобы сохранить сообщение об ошибке в одном элементе. Такая техника полезна, когда важно сохранить части строки, не разделяя их излишне.
При использовании split() для парсинга данных важно всегда учитывать формат данных и особенности разделителей. В случае с CSV можно столкнуться с проблемами, если строки содержат символы, используемые как разделители. Для логов важно точно понимать структуру строки, чтобы правильно извлечь нужные данные.
Вопрос-ответ:
Что делает функция split в Python?
Функция `split` в Python разделяет строку на части, используя указанный разделитель. Если разделитель не задан, строка будет разбита по пробелам. Например, строка `»Python is awesome»` будет разделена на список `[«Python», «is», «awesome»]` при использовании `split()`. Можно передать разделитель в качестве аргумента, например, `split(«,»)`, чтобы разделить строку по запятой.
Как работает функция split, если разделитель не указан?
Если в функцию `split()` не передается разделитель, то по умолчанию строка будет разбита по пробелам. Это включает как пробелы, так и другие виды пробельных символов (например, табуляцию или новую строку). Все последовательные пробелы будут восприниматься как один, и в результирующем списке не будет пустых строк. Например, строка `» Python is awesome «` будет разделена на список `[‘Python’, ‘is’, ‘awesome’]`.
Можно ли использовать split для разделения строки по нескольким разделителям?
Функция `split()` сама по себе не поддерживает использование нескольких разных разделителей одновременно. Однако можно использовать регулярные выражения с модулем `re`, чтобы разделить строку по нескольким разделителям. Пример: `re.split(‘[,;:]’, ‘a,b;c:d’)` разделит строку по запятой, точке с запятой и двоеточию. В результате получится список: `[‘a’, ‘b’, ‘c’, ‘d’]`.
Что будет, если строка не содержит разделителя, который я указал в функции split?
Если в строке нет указанного разделителя, то функция `split()` вернет саму строку в виде одного элемента списка. Например, если мы применим `split(«-«)` к строке `»Python»`, которая не содержит дефиса, результат будет: `[‘Python’]`.
Можно ли ограничить количество разбиений в функции split?
Да, можно ограничить количество разбиений, передав второй аргумент в функцию `split()`. Этот аргумент указывает, сколько максимальных разбиений должно быть выполнено. Например, в строке `»a-b-c-d»` вызов `split(«-«, 2)` вернет список `[‘a’, ‘b’, ‘c-d’]`, так как после двух разделений оставшаяся часть строки будет возвращена как один элемент.
Что такое функция split в Python и для чего она используется?
Функция `split()` в Python предназначена для разбиения строки на части (или подстроки) на основе разделителя. Это полезно, например, для обработки данных, представленных в виде строки, где элементы разделены пробелами, запятыми или другими символами. Если не указать разделитель, то строка будет разбита по пробелам. Функция возвращает список строк.