Модуль array в Python предоставляет компактную и эффективную альтернативу спискам, если требуется хранить элементы одного типа. Каждый массив создаётся с указанием типа данных, определяемого символьным кодом: например, ‘i’ для целых чисел, ‘f’ для чисел с плавающей точкой. Это позволяет экономить память и ускорять операции над данными по сравнению со стандартными списками.
Использование array.array особенно оправдано в задачах с большим объёмом числовых данных, когда важны производительность и предсказуемое поведение. В отличие от списков, массивы поддерживают только однородные типы, что снижает накладные расходы интерпретатора на хранение метаданных каждого элемента.
Создание массива требует указания типа и итерируемого объекта: array('i', [1, 2, 3]). Изменение элементов, срезы, методы append(), extend(), insert(), remove(), pop() и reverse() работают аналогично спискам, но с жёстким контролем типов. Это делает модуль array предпочтительным выбором для задач с требованиями к строгой типизации и низкому потреблению памяти.
Когда стоит использовать array вместо list
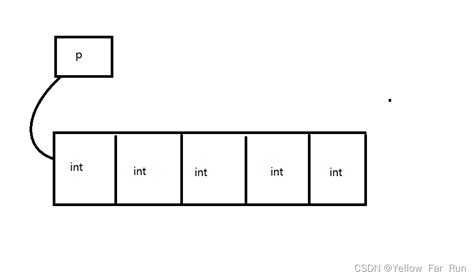
Модуль array следует применять в ситуациях, когда необходима высокая эффективность по памяти и скорости при работе с однотипными числовыми данными.
- Четкий тип данных: массивы требуют указания одного типа данных (например,
'i'для целых чисел), что исключает хранение разнородных объектов, снижая накладные расходы. - Экономия памяти:
array.arrayзанимает меньше памяти, чемlist, поскольку не хранит ссылки на объекты, а только сырые значения. - Ускоренная сериализация: массивы быстрее читаются и записываются в файл с помощью методов
tofile()иfromfile(), особенно при работе с бинарными данными. - Интеграция с C-модулями: при взаимодействии с расширениями на C или использованием
ctypesпредпочтительнее массивы, так как они предоставляют буферный интерфейс и могут быть напрямую переданы в нативный код. - Массовая инициализация: при создании больших числовых структур (например, массив из миллиона нулей)
arrayсправляется быстрее и эффективнее, чемlist.
Использование array оправдано, если вы заранее знаете тип элементов, работаете с большими объемами чисел и критичны к расходу памяти или скорости выполнения операций.
Создание массива с конкретным типом данных
'b'– знаковый байт (int, 1 байт)'B'– беззнаковый байт (unsigned int, 1 байт)'h'– знаковое целое (int, 2 байта)'H'– беззнаковое целое (unsigned int, 2 байта)'i'– знаковое целое (int, 4 байта)'I'– беззнаковое целое (unsigned int, 4 байта)'f'– число с плавающей точкой (float, 4 байта)'d'– число с плавающей точкой двойной точности (double, 8 байт)
Пример создания массива из целых 32-битных чисел:
from array import array
a = array('i', [10, 20, 30])
Тип элементов массива строго фиксирован. Попытка добавить значение другого типа приведёт к TypeError или OverflowError при несоответствии диапазону. Для проверки допустимого диапазона следует учитывать размерность типа. Например, для 'b' допустимы значения от -128 до 127.
Если данные поступают из внешнего источника, рекомендуется предварительно преобразовывать типы явно, например через int() или float(), чтобы избежать ошибок при инициализации массива.
Изменить тип элементов уже созданного массива невозможно. Для преобразования необходимо создать новый массив с другим типом и сконвертированными значениями:
from array import array
a = array('i', [1, 2, 3])
b = array('f', (float(x) for x in a))
При работе с большими объёмами данных тип следует подбирать строго под диапазон значений, чтобы минимизировать расход памяти.
Добавление и удаление элементов из массива
Для работы с массивами в Python используется модуль array. Добавление нового элемента осуществляется методом append(), который помещает значение в конец массива. Например: arr.append(42). Тип добавляемого значения должен соответствовать типу элементов массива, иначе возникнет исключение TypeError.
Чтобы вставить элемент в конкретную позицию, применяется метод insert(index, value). Он сдвигает последующие элементы вправо. Пример: arr.insert(2, 10) добавит число 10 на третью позицию. Производительность метода зависит от размера массива, так как требуется перестройка всех последующих элементов.
Удаление значения по индексу выполняется с помощью pop(index). Если индекс не указан, удаляется последний элемент. Пример: arr.pop(0) удалит первый элемент. Метод возвращает удалённое значение.
Для удаления первого вхождения определённого значения используется remove(value). Если такого значения нет, будет вызвано исключение ValueError. Эффективнее проверять наличие значения заранее: if value in arr: arr.remove(value).
Очистить массив можно методом array.clear(), доступным начиная с Python 3.3. Для более ранних версий применяется del arr[:], что аналогично очистке, но выполняется вручную.
Обход массива и доступ к элементам
Модуль array в Python предоставляет массивы с элементами одного типа, что делает доступ и обход эффективными. Для обращения к элементу используется индекс: arr[0] – первый, arr[-1] – последний. Индексация всегда начинается с нуля.
При необходимости последовательного доступа к элементам используют цикл for:
import array
arr = array.array('i', [10, 20, 30, 40])
for value in arr:
print(value)
Если требуется доступ и к индексу, и к значению, применяют enumerate:
for index, value in enumerate(arr):
print(f'Индекс: {index}, Значение: {value}')
Для прямого изменения элемента: arr[2] = 99. Это заменит третий элемент на 99. Проверка диапазона индексов обязательна – попытка обращения за пределы вызовет IndexError.
Срезы позволяют получить часть массива: arr[1:3] вернёт подмассив с элементами на позициях 1 и 2. Срезы возвращают новый массив того же типа.
Обратный обход реализуется через срез arr[::-1] или цикл for i in reversed(arr), оба способа подходят для чтения. Для изменения элементов в обратном порядке предпочтителен reversed(range(len(arr))) в сочетании с индексом.
Преобразование массива в список и обратно
Массивы из модуля array поддерживают преобразование в списки с помощью метода tolist(). Этот метод возвращает новый объект типа list, содержащий все элементы массива в том же порядке. Например: array('i', [1, 2, 3]).tolist() вернёт [1, 2, 3].
Обратное преобразование осуществляется созданием массива с помощью конструктора array.array(), в который передаётся код типа и сам список. Пример: array('i', [1, 2, 3]). Важно обеспечить соответствие типа данных в списке формату массива, иначе возникнет ошибка TypeError или OverflowError.
Если список содержит значения с плавающей точкой, использовать нужно код типа 'f' или 'd'. Для целых чисел – 'b', 'h', 'i' и др., в зависимости от диапазона значений. Например, список [0.5, 1.5] корректно преобразуется в array('f', [0.5, 1.5]), но вызов array('i', [0.5, 1.5]) приведёт к исключению.
Рекомендуется явно указывать код типа при каждом преобразовании списка в массив, особенно при работе с внешними источниками данных. Это предотвращает ошибки при несовпадении ожидаемого и фактического формата чисел.
Чтение и запись массива в бинарный файл
Для работы с массивами в бинарном формате в Python удобно использовать модуль array, который предоставляет методы для записи и чтения данных в/из бинарных файлов. Это полезно при необходимости сохранить данные с минимальными потерями по размеру и без преобразования типов данных в строковый формат.
Чтобы записать массив в бинарный файл, используйте метод tofile(), который записывает все элементы массива в файл в их исходном бинарном представлении. Пример записи массива целых чисел в файл:
import array
# Создание массива типа 'i' (целые числа)
arr = array.array('i', [1, 2, 3, 4, 5])
# Запись массива в файл
with open('data.bin', 'wb') as f:
arr.tofile(f)Метод tofile() записывает данные в файл в том же формате, в котором они хранятся в памяти. Важно, что открытие файла должно происходить в бинарном режиме (‘wb’).
Для чтения массива из бинарного файла используется метод fromfile(), который загружает данные из файла и преобразует их в массив указанного типа. Пример чтения данных из бинарного файла:
import array
# Чтение массива из файла
arr = array.array('i')
with open('data.bin', 'rb') as f:
arr.fromfile(f, 5) # Чтение 5 элементов
print(arr)Метод fromfile() принимает два аргумента: объект файла и количество элементов, которые нужно прочитать. Важно точно указать количество элементов, иначе могут возникнуть ошибки или некорректное чтение данных.
При работе с большими массивами рекомендуется использовать методы для поэтапного чтения и записи, чтобы избежать переполнения памяти. Для этого можно читать или записывать данные блоками, обрабатывая части массива по очереди. Например:
import array
# Запись больших массивов блоками
arr = array.array('i', range(1000000))
with open('large_data.bin', 'wb') as f:
for i in range(0, len(arr), 10000):
arr[i:i+10000].tofile(f)Такой подход минимизирует потребление памяти при работе с большими объемами данных и позволяет эффективно обрабатывать массивы.
Использование массива для хранения чисел с плавающей точкой

Для создания массива, содержащего числа с плавающей точкой, используется следующий синтаксис:
import array
arr = array.array('d', [1.23, 3.45, 6.78, 9.01])В этом примере создается массив arr типа ‘d’, который может хранить числа с плавающей точкой. Отличие массива от стандартных списков в том, что массивы требуют меньше памяти и работают быстрее при обработке больших объемов данных. Это особенно заметно при работе с большими массивами чисел, например, при обработке данных из научных вычислений или анализа данных.
Основные преимущества использования массива для чисел с плавающей точкой:
- Меньшее потребление памяти: массивы с типом ‘d’ занимают меньше памяти по сравнению с обычными списками Python, что особенно важно при хранении и обработке больших объемов данных.
- Повышенная производительность: операции над массивами работают быстрее, чем над списками, поскольку массивы используют более компактное представление данных в памяти.
- Типизация: использование массива гарантирует, что в нем будут храниться только данные нужного типа (в данном случае — числа с плавающей точкой), что исключает ошибки типа, характерные для обычных списков.
Важно помнить, что массивы из модуля array не поддерживают все возможности стандартных списков Python. Например, в массиве нельзя хранить элементы разных типов, что может быть ограничением при необходимости работы с разнородными данными. Однако если требуется работать только с числами с плавающей точкой, использование массива будет оптимальным выбором.
Для добавления новых элементов в массив можно использовать метод append(), например:
arr.append(12.34)Для изменения элементов массива применяется индексирование:
arr[0] = 5.67Кроме того, можно легко преобразовать массив в список с помощью метода tolist():
list_arr = arr.tolist()При необходимости работы с большими объемами данных рекомендуется использовать массивы, так как они обеспечивают экономию памяти и большую скорость обработки по сравнению с обычными списками, что важно для выполнения сложных вычислений и анализа больших наборов числовых данных.
Сравнение модуля array с numpy при работе с числами
Модуль array и библиотека numpy предназначены для работы с массивами чисел, но они значительно различаются по функционалу и производительности. Оба инструмента могут использоваться для создания и манипуляции массивами, однако их особенности и области применения стоит учитывать при выборе решения.
Модуль array является встроенным в Python и предоставляет базовые возможности для создания массивов с элементами одного типа, что снижает потребление памяти по сравнению с обычными списками Python. Массивы, созданные с помощью array, требуют указания типа данных (например, ‘i’ для целых чисел или ‘f’ для чисел с плавающей точкой), что обеспечивает оптимизацию в плане памяти и скорости.
NumPy – это специализированная библиотека для научных вычислений, которая представляет собой более мощный инструмент для работы с массивами. В отличие от модуля array, numpy предлагает гораздо более широкий набор функций для математических операций, таких как линейная алгебра, статистика, обработка многомерных данных и многое другое. Благодаря внутренним оптимизациям и использованию низкоуровневых операций, numpy значительно быстрее при работе с большими данными.
Основное различие между этими двумя подходами заключается в производительности и масштабируемости. NumPy предоставляет гораздо более быстрые операции с массивами за счет использования высокоэффективных алгоритмов и возможностей работы с многомерными массивами. Например, выполнение операции над двумя массивами в numpy будет значительно быстрее, чем в array, благодаря оптимизированным внутренним вычислениям.
Когда важна производительность и требуется работа с большими объемами данных, numpy является предпочтительным выбором. В то же время, если задача ограничена памятью и производительностью, и необходимо выполнять только базовые операции, array может быть достаточным инструментом.
Также стоит отметить, что numpy имеет более удобный синтаксис для выполнения математических операций и работы с многомерными массивами, чего нет в модуле array. В случае работы с большими и сложными вычислениями выбор в пользу numpy будет очевидным, а для простых задач достаточно стандартных возможностей array.
Вопрос-ответ:
Что такое массивы в Python и для чего используется модуль array?
Массивы в Python — это структуры данных, которые позволяют хранить коллекции однотипных элементов. В стандартной библиотеке Python есть модуль `array`, который предоставляет поддержку массивов. В отличие от списков, элементы массива имеют фиксированный тип данных, что делает их более удобными для работы с большими объемами данных или при необходимости производить вычисления с элементами массивов, не теряя памяти на динамическую типизацию. Модуль array полезен, когда требуется хранить и манипулировать большим количеством чисел с минимальными затратами памяти.
В чем отличие между массивами и списками в Python?
Основное отличие между массивами и списками в Python заключается в том, что массивы, созданные с помощью модуля `array`, требуют, чтобы все элементы имели одинаковый тип данных. Это позволяет массивам быть более эффективными по памяти, чем списки, которые могут содержать элементы разных типов (например, числа и строки). Массивы лучше подходят для работы с большими объемами данных, где важна производительность и экономия памяти. В свою очередь, списки более гибкие и удобные для хранения элементов различных типов. Однако для хранения исключительно однотипных данных массивы будут быстрее и менее ресурсоемкими.