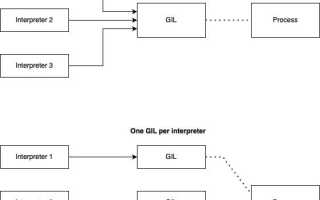
GIL (Global Interpreter Lock) – это механизм CPython-интерпретатора, который ограничивает выполнение байт-кода Python в многопоточном окружении. В каждый момент времени только один поток может исполнять Python-код, даже если у приложения запущено несколько потоков. Это решение было принято для упрощения работы с памятью и обеспечения безопасности при доступе к объектам интерпретатора.
Если требуется задействовать все ядра процессора, рекомендуется использовать многопроцессную модель через модуль multiprocessing. Каждый процесс получает свой собственный интерпретатор и, соответственно, независимый GIL. Для задач, критичных к скорости, можно также использовать сторонние решения: Numba и Cython позволяют обойти GIL при работе с нативным кодом, а интерпретаторы вроде PyPy и Jython вовсе не используют GIL в том виде, в каком он реализован в CPython.
Как работает GIL в интерпретаторе CPython
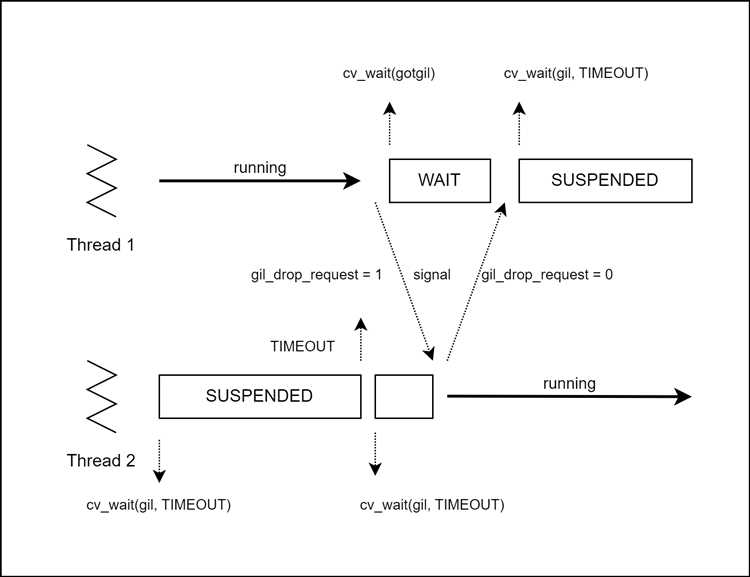
GIL реализован как рекурсивный блокировщик, и его поведение зависит от внутренних механизмов планирования потоков в CPython. При запуске нескольких потоков GIL переключается между ними с периодом, установленным параметром sys.getswitchinterval() (по умолчанию 5 мс). Это означает, что даже при наличии нескольких потоков, только один из них может исполнять Python-код, пока не произойдёт явная передача управления.
GIL освобождается вручную в C-расширениях, например, при длительных системных вызовах или вычислениях на C-уровне. Это позволяет другим потокам выполнять код Python, пока основной поток ожидает завершения операции. Однако большинство стандартных операций Python не освобождают GIL, что делает параллельное выполнение CPU-зависимых задач неэффективным.
Для обхода ограничений GIL рекомендуется использовать модуль multiprocessing, который создаёт отдельные процессы с собственными GIL, либо выносить вычислительно тяжёлые участки в C-расширения с ручным управлением блокировкой.
Почему GIL нужен: технические причины и ограничения

Без GIL каждая операция инкремента или декремента счетчика ссылок для любого объекта потребовала бы блокировки, что резко снизило бы производительность даже однопоточных программ. GIL позволяет избежать постоянного захвата и освобождения мьютексов при изменении счетчиков, особенно при работе с примитивными объектами вроде целых чисел и строк.
Также GIL упрощает реализацию сборщика мусора, так как предотвращает гонки при выполнении циклического обнаружения неиспользуемых объектов. Без GIL потребовалась бы сложная и затратная координация между потоками, чтобы гарантировать согласованность графа объектов.
Ограничения GIL проявляются в многопоточной обработке CPU-интенсивных задач. Даже при наличии нескольких ядер, только один поток Python может выполнять инструкции интерпретатора в конкретный момент времени. Это делает многопоточность в CPython неэффективной для задач, активно использующих CPU, таких как сжатие, криптография или численные вычисления.
Для обхода ограничений используют multiprocessing (процессы вместо потоков), C-расширения, работающие вне GIL, и альтернативные интерпретаторы Python, например PyPy или Jython, где GIL отсутствует или реализован иначе. Также рекомендуется передавать тяжёлую логику на сторонние библиотеки, написанные на C/C++, которые могут временно освобождать GIL во время выполнения.
Как GIL влияет на потоки и параллельное выполнение кода
Для обхода ограничений GIL при выполнении CPU-bound задач рекомендуется использовать модуль multiprocessing, который создает отдельные процессы с собственными интерпретаторами Python и независимыми GIL. Также эффективны реализации на C или Cython, где можно вручную управлять освобождением GIL в критичных участках кода.
GIL не влияет на производительность при использовании внешних библиотек, написанных на C и оптимизированных под многопоточность, если они освобождают GIL внутри своих реализаций. Пример – NumPy, который при вычислениях может использовать многопоточную обработку на уровне C без ограничений со стороны GIL.
В чем разница между потоками и процессами при наличии GIL

GIL (Global Interpreter Lock) в CPython блокирует одновременное выполнение байткода несколькими потоками, даже на многоядерных системах. Это означает, что потоки внутри одного процесса не могут эффективно использовать все ядра CPU при выполнении Python-кода. Потоки переключаются по очереди, что полезно для I/O-задач, но неэффективно для задач с высокой вычислительной нагрузкой.
Процессы, в отличие от потоков, не ограничены GIL. Каждый процесс запускает собственную интерпретацию Python, со своим GIL. Это позволяет процессам работать параллельно на разных ядрах, что делает их предпочтительным выбором для CPU-интенсивных задач, таких как обработка изображений, вычисления в науке и машинное обучение.
Модуль multiprocessing реализует создание отдельных процессов и позволяет обойти ограничения GIL. Однако он требует межпроцессного взаимодействия через очереди и пайпы, что несет дополнительные издержки на сериализацию (например, с использованием pickle).
Когда многозадачность с потоками в Python оказывается бесполезной

В Python многозадачность с использованием модуля threading часто не даёт ожидаемого прироста производительности из-за глобальной блокировки интерпретатора – GIL (Global Interpreter Lock). Это особенно критично в следующих сценариях:
-
Вычислительно интенсивные задачи: при выполнении операций с большим количеством математических вычислений, например, обработки больших массивов данных, криптографии, сжатия, декомпрессии. Все потоки в Python поочерёдно получают доступ к CPU, что приводит к простой и потере производительности по сравнению с однопоточным вариантом.
-
Параллельная обработка больших чисел или массивов: если задача использует циклы, функции из модуля
mathили работает с NumPy без использования C-расширений, то потоки не масштабируются с количеством ядер, так как каждый поток всё равно блокирует GIL. -
Обработка изображений, видео, аудио: при использовании чисто Python-библиотек потоковая многозадачность не ускоряет процесс. Пример: декодирование видеопотока с помощью Python-кода без внешних C-модулей.
-
Моделирование, симуляции, ML/AI без C-ускорения: библиотеки, не реализованные на C или не освобождающие GIL (например, нестандартные реализации алгоритмов), не получат прироста при использовании потоков.
В таких случаях предпочтительнее:
- Переписать критичные участки на C/C++ и использовать
ctypesилиcffi. - Применить многопроцессную модель (
multiprocessing), которая создаёт отдельные процессы, каждый со своим интерпретатором Python и отдельным GIL. - Использовать библиотеки, снимающие ограничение GIL, например, NumPy, если она работает с C-ядром, или Cython с указанием
nogil.
Какие библиотеки позволяют обойти ограничения GIL

Несмотря на то, что Global Interpreter Lock (GIL) ограничивает возможности многозадачности в Python, существуют несколько решений, позволяющих эффективно обходить эти ограничения. Эти библиотеки и инструменты либо используют многопроцессорную архитектуру, либо реализуют параллельную обработку данных, минуя GIL. Рассмотрим основные из них.
- Multiprocessing – стандартная библиотека Python, которая предоставляет интерфейс для работы с процессами. Каждый процесс работает в своем собственном адресном пространстве, что позволяет обойти GIL. Этот подход особенно эффективен для задач, требующих интенсивных вычислений, таких как обработка больших массивов данных или выполнение сложных алгоритмов.
- Joblib – библиотека для параллельных вычислений, которая используется для ускорения обработки данных и параллельного выполнения задач. Joblib работает с многозадачностью на уровне процессов и является хорошим инструментом для работы с большими объемами данных, поскольку она эффективно использует возможности многопроцессорных систем.
- NumPy и SciPy – хотя сами по себе не обходят GIL, эти библиотеки используют C-расширения для выполнения вычислений, что позволяет эффективно использовать многоядерные процессоры. Внутри этих библиотек операции выполняются в многозадачном режиме, освобождая GIL для вычислений на низком уровне.
- PyPy – альтернатива CPython, которая реализует JIT-компиляцию и может существенно повысить производительность многозадачных программ. PyPy не устраняет GIL, но его оптимизации в ряде случаев позволяют улучшить скорость работы многозадачных приложений.
- Dask – библиотека для параллельных вычислений, которая предоставляет удобный интерфейс для распределенных вычислений. Dask эффективно использует многопроцессорную архитектуру и может масштабироваться на кластеры, позволяя обрабатывать большие объемы данных.
- CuPy – библиотека, аналогичная NumPy, но с поддержкой GPU. CuPy может использовать графические процессоры для вычислений, что позволяет обходить GIL и значительно ускорять выполнение задач, связанных с числовыми вычислениями.
- Ray – система для распределенных вычислений, которая предоставляет средства для разработки масштабируемых приложений с использованием параллельных вычислений. Ray оптимизирован для работы с многозадачными программами и хорошо справляется с распределением вычислений на несколько узлов.
- TensorFlow и PyTorch – хотя эти библиотеки в первую очередь ориентированы на машинное обучение, они также используют многопроцессорную и многозадачную архитектуру для эффективной работы с большими объемами данных и обхода GIL. Оба инструмента поддерживают вычисления на GPU, что помогает значительно ускорить процесс обучения моделей.
Для оборачивания задач, связанных с ограничениями GIL, важно учитывать требования приложения, тип данных и доступные ресурсы. Каждая из этих библиотек предоставляет оптимальные решения для конкретных ситуаций, позволяя эффективно управлять многозадачностью в Python.
Подходит ли asyncio как альтернатива потокам с GIL
Когда задачи требуют интенсивных вычислений, asyncio не может конкурировать с многопоточностью или многопроцессорностью. В этом случае каждый поток или процесс будет работать независимо, и GIL не будет ограничивать их взаимодействие. Для таких задач лучше использовать библиотеки, поддерживающие многопроцессорность, например, multiprocessing, или параллельные вычисления через concurrent.futures.
Таким образом, asyncio представляет собой эффективное решение для I/O-bound задач, но не подходит для CPU-bound операций. Для сложных вычислений многозадачность через потоки с GIL не будет эффективной, и стоит рассматривать альтернативы, не связанные с глобальным блокировщиком интерпретатора.
Какие языки и реализации Python не используют GIL

Несмотря на наличие GIL (Global Interpreter Lock) в стандартной реализации Python (CPython), существуют другие языки и реализации, которые позволяют эффективно использовать многозадачность без блокировки потоков на уровне интерпретатора.
Jython – это реализация Python для платформы Java. В отличие от CPython, Jython не использует GIL, так как управление потоками в нем передается Java Virtual Machine (JVM), которая сама эффективно обрабатывает многозадачность. Это позволяет Jython работать с потоками параллельно, не сталкиваясь с ограничениями GIL, что значительно увеличивает производительность при многозадачности, особенно в многопроцессорных системах.
IronPython – это версия Python для .NET Framework, также не использующая GIL. В IronPython потоками управляет .NET runtime, что позволяет добиться эффективного многозадачного выполнения. Таким образом, разработчики, работающие с .NET, могут использовать все преимущества многозадачности, не сталкиваясь с ограничениями, свойственными CPython.
Pyston – это высокопроизводительная реализация Python, ориентированная на улучшение скорости исполнения программ. В отличие от CPython, Pyston использует более современные подходы к многозадачности и не имеет глобальной блокировки. Это позволяет улучшить параллельную работу с потоками и повысить общую производительность в многозадачных приложениях.
PyPy с поддержкой STM (Software Transactional Memory) также может быть использован для параллельного выполнения без традиционного GIL. Хотя STM в PyPy находится в стадии разработки и не является стандартной функцией, эта модель потенциально может предоставить решение для многозадачных операций без блокировок, присущих GIL в CPython.
Для большинства проектов, требующих высокой параллельности, выбор альтернативных реализаций Python без GIL может быть оправдан, особенно если целевая платформа поддерживает их оптимизацию. Однако стоит отметить, что переход на такие реализации требует внимательного подхода к совместимости с существующими библиотеками и фреймворками.
Вопрос-ответ:
Что такое GIL в Python и как он влияет на многозадачность?
GIL (Global Interpreter Lock) — это механизм, который используется в интерпретаторе Python (CPython) для управления доступом к общим ресурсам программы, таким как память. Он ограничивает возможность выполнения нескольких потоков одновременно. Это означает, что хотя Python и поддерживает многозадачность с помощью потоков, только один поток может выполнять байт-код Python в любой момент времени. Это ограничение может затруднить эффективное использование многозадачности на многопроцессорных системах, особенно при выполнении вычислительно сложных задач. Однако для задач, ориентированных на I/O, GIL не имеет большого влияния, потому что потоки могут блокироваться на операции ввода-вывода, позволяя другим потокам работать.
Почему GIL ограничивает многозадачность в Python?
Причина заключается в том, что GIL блокирует выполнение байт-кода Python в каждом потоке. В Python используется интерпретатор CPython, который не поддерживает настоящее параллельное выполнение потоков. Это связано с тем, что GIL синхронизирует доступ к данным, чтобы избежать проблем с их целостностью, когда несколько потоков пытаются изменить одни и те же данные одновременно. Если бы GIL не существовал, несколько потоков могли бы нарушить состояние данных, что могло бы привести к багам или сбоям. В то время как для задач, которые не зависят от CPU, например, операций с сетью, GIL не создает значительных проблем, для вычислительных задач это может привести к тому, что многозадачность не даст прироста производительности.
Как GIL влияет на производительность многозадачных программ в Python?
На производительность многозадачных программ GIL оказывает серьезное влияние в случае вычислительно интенсивных задач. Если программа использует несколько потоков для выполнения вычислений, GIL будет препятствовать параллельному выполнению этих потоков, что может привести к низкой производительности, особенно на многопроцессорных системах. Однако в случаях, когда программа занимается в основном операциями ввода-вывода (например, работа с файлами или сетью), GIL не мешает многозадачности, поскольку потоки часто блокируются во время операций I/O, позволяя другим потокам выполнять свою работу. Это делает Python хорошим выбором для многозадачных приложений, где большая часть работы связана с вводом-выводом, а не с тяжелыми вычислениями.
Как можно обойти ограничения GIL при работе с многозадачностью в Python?
Для обхода ограничений GIL можно использовать несколько подходов. Один из них — это многозадачность на основе процессов, а не потоков. В этом случае каждый процесс работает в своем собственном адресном пространстве и не сталкивается с GIL, что позволяет использовать многопроцессорные системы более эффективно. Для этого можно использовать модуль `multiprocessing` в Python. Другим вариантом является использование других реализаций Python, таких как Jython (реализация Python для JVM) или IronPython (реализация для .NET), которые не используют GIL и поддерживают истинную параллельность. Также, если задача связана с вычислениями, можно использовать библиотеки, такие как NumPy, которые реализуют вычисления на C и обходят GIL, выполняя вычисления вне Python-интерпретатора.