В Python работа с массивами часто требует использования библиотеки NumPy, которая предоставляет мощные инструменты для математических операций и оптимизации вычислений. Для того чтобы начать использовать массивы NumPy, необходимо преобразовать стандартные списки Python в структуры данных, предоставляемые этой библиотекой. Такой процесс преобразования прост и эффективен, особенно если нужно ускорить выполнение вычислений или работать с большими объемами данных.
Преобразование списка в numpy массив выполняется с помощью функции numpy.array(). Это позволяет не только преобразовать список в массив, но и получить доступ к многочисленным методам для работы с данными. Основное преимущество использования NumPy заключается в том, что преобразованный массив будет обладать фиксированным типом данных, что упрощает работу с вычислениями и экономит память.
Рекомендация: Если вы хотите добиться максимальной производительности, старайтесь сразу передавать данные в массив в нужном формате, избегая лишних преобразований и дополнительных шагов. Использование numpy в Python оправдано для большинства задач, связанных с числовыми данными, и значительно улучшает производительность программы.
Простой способ преобразования list в numpy массив с помощью np.array()
Для преобразования списка Python в массив NumPy достаточно использовать функцию np.array(). Эта операция проста и удобна, особенно когда необходимо работать с числовыми данными в формате массива, который поддерживает векторизацию и ускоренные вычисления.
Чтобы выполнить преобразование, достаточно передать список как аргумент функции. Например:
import numpy as np
my_list = [1, 2, 3, 4, 5]
numpy_array = np.array(my_list)
В результате numpy_array будет представлять собой одномерный массив NumPy, содержащий те же элементы, что и исходный список. Это простое преобразование может быть полезно при работе с большими данными, поскольку NumPy оптимизирован для эффективных математических операций над массивами.
Можно также преобразовать многомерные списки (например, списки списков) в многомерные массивы. Например:
my_list_2d = [[1, 2, 3], [4, 5, 6]]
numpy_array_2d = np.array(my_list_2d)
Этот код создаст двумерный массив, аналогичный таблице, где каждая вложенная структура списка станет строкой массива.
Важно помнить, что тип данных элементов в исходном списке влияет на тип данных итогового массива. Если список содержит элементы разных типов (например, числа и строки), NumPy приведет все элементы к общему типу, что может повлиять на производительность и точность вычислений. В случае необходимости можно указать тип данных явно с помощью параметра dtype:
numpy_array = np.array(my_list, dtype=np.float32)
Этот способ предоставляет гибкость при работе с данными и позволяет более точно контролировать типы элементов в массиве.
Как преобразовать список с несколькими вложенными списками в numpy массив
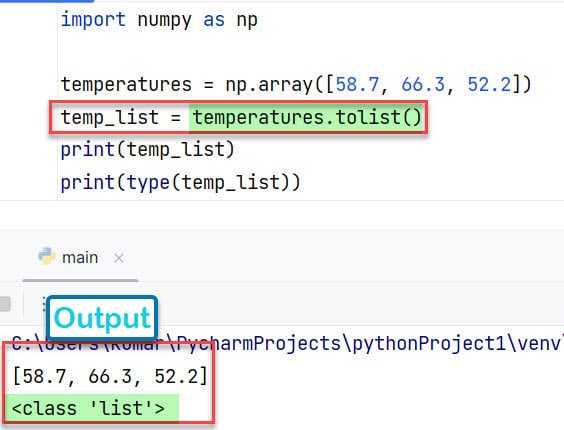
Для преобразования списка с несколькими вложенными списками в numpy массив, можно использовать функцию numpy.array(). Важно, чтобы вложенные списки имели одинаковую длину, иначе возникнет ошибка или данные будут преобразованы в массив объектов.
Пример:
import numpy as np
nested_list = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
np_array = np.array(nested_list)
print(np_array)
Этот код создаст двумерный массив, где каждая строка будет соответствовать вложенному списку.
Если списки вложены на несколько уровней, результатом будет массив объектов, а не числовой массив:
nested_list = [[1, 2], [3, 4], [5, [6, 7]]]
np_array = np.array(nested_list)
print(np_array)
Для корректного преобразования рекомендуется избегать вложенности более чем на два уровня или использовать правильную структуру данных, как показано в первом примере.
Если необходимо гарантировать правильность преобразования, можно использовать проверку, чтобы все вложенные списки имели одинаковую длину:
if all(len(sublist) == len(nested_list[0]) for sublist in nested_list):
np_array = np.array(nested_list)
else:
raise ValueError("Вложенные списки должны быть одинаковой длины.")
Это предотвратит создание некорректных массивов и поможет избежать ошибок при дальнейшей работе с данными.
Кроме того, при необходимости можно явно указать тип данных массива с помощью параметра dtype:
np_array = np.array(nested_list, dtype=int)
Это полезно, если элементы в списке имеют разные типы данных, и вы хотите привести их к единому типу.
Как задать тип данных при преобразовании list в numpy массив
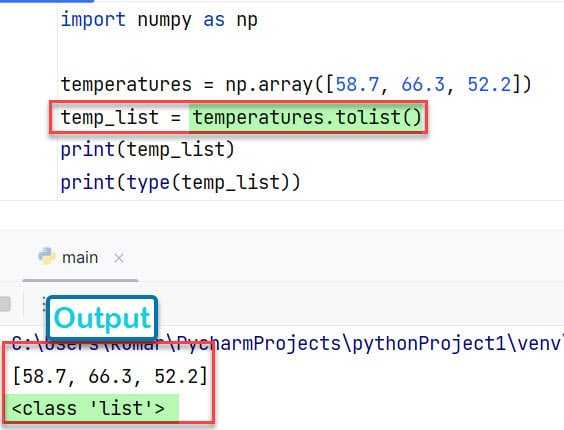
При преобразовании списка Python в массив NumPy, важно учитывать, какой тип данных будет использоваться в массиве. NumPy автоматически определяет тип данных на основе элементов списка, но часто необходимо задать тип явно для оптимизации работы с памятью или для выполнения математических операций. Для этого используется параметр dtype функции numpy.array().
Пример явного указания типа данных:
import numpy as np
my_list = [1, 2, 3, 4]
array = np.array(my_list, dtype=np.float32)
print(array)
В этом примере список целых чисел преобразуется в массив с типом данных float32. Это может быть полезно, если необходимо работать с числами с плавающей запятой, а также для уменьшения размера массива при ограниченной точности.
Для чисел с плавающей запятой можно выбрать несколько типов данных, таких как np.float32, np.float64, в зависимости от необходимой точности. Если же задача состоит в том, чтобы использовать более компактный формат, можно выбрать np.int8 или np.int16 для целых чисел, если диапазон значений позволяет.
Тип данных можно задать как строкой, так и с помощью сокращений типа NumPy. Например:
array = np.array(my_list, dtype='int32')
Кроме того, можно преобразовывать данные в более сложные типы, такие как строки или даже структуры данных, например:
my_list = ['a', 'b', 'c']
array = np.array(my_list, dtype=np.str_)
print(array)
При преобразовании из списка строк в массив NumPy тип данных автоматически станет строковым, но явное указание типа может быть полезно для избежания ошибок при дальнейших операциях с массивом.
Важно учитывать, что тип данных, заданный при создании массива, влияет на производительность и использование памяти. Чем меньше тип данных, тем экономнее будет использование памяти, но нужно внимательно следить, чтобы диапазон значений не выходил за пределы выбранного типа.
Что делать, если list содержит элементы разной длины?
Одним из решений является приведение всех вложенных списков к одинаковой длине. Например, можно добавить пустые значения (например, None или np.nan) к более коротким спискам, чтобы они стали одинаковыми по размеру. Это можно сделать с помощью цикла или встроенной функции itertools.zip_longest:
from itertools import zip_longest import numpy as np list_data = [[1, 2], [3, 4, 5], [6]] padded_data = list(zip_longest(*list_data, fillvalue=np.nan)) np_array = np.array(padded_data)
В этом примере, если один из списков короче других, то недостающие элементы будут заменены на np.nan, что обеспечит одинаковую длину всех вложенных списков.
Другой подход – привести все списки к минимальной длине (например, обрезать их до длины самого короткого списка). Это можно сделать с помощью list comprehension или обычного цикла:
min_length = min(len(lst) for lst in list_data) trimmed_data = [lst[:min_length] for lst in list_data] np_array = np.array(trimmed_data)
Если данные в списках имеют смысл только в случае полного соответствия длины (например, списки представляют собой строки с переменным количеством элементов), можно также рассмотреть вариант преобразования списка в объект dtype=object, который позволяет хранить элементы переменной длины, но в таком случае работа с массивом будет менее эффективной.
Преобразование list с помощью метода np.asarray() для уже существующих массивов
Метод np.asarray() из библиотеки NumPy позволяет преобразовать стандартный Python list в массив NumPy, при этом сохраняя исходные данные. Этот метод особенно полезен, если необходимо создать массив из уже существующего списка, не изменяя его содержимое. В отличие от np.array(), который всегда копирует данные, np.asarray() старается вернуть представление того же массива, если тип данных уже соответствует требуемому, минимизируя расходы памяти.
Если у вас есть list, который содержит данные одного типа, например, целые числа или вещественные числа, np.asarray() будет эффективным способом преобразования этого списка в массив. Например:
import numpy as np
my_list = [1, 2, 3, 4]
np_array = np.asarray(my_list)
print(np_array)Этот код создаст массив np_array, идентичный входному списку, но с типом данных NumPy. В случае, если элементы списка имеют разные типы данных, np.asarray() приведет все элементы к наиболее подходящему типу (например, преобразует строковые элементы в строковый тип данных).
Важно отметить, что np.asarray() не делает копию данных, если это не требуется. Если входной list уже является массивом NumPy с подходящим типом, метод просто вернет ссылку на исходный массив, что делает его более быстрым по сравнению с np.array() в подобных ситуациях.
Для работы с многомерными массивами метод также поддерживает параметры, такие как dtype (для указания типа данных) и order (для определения порядка элементов в массиве). Например, если требуется явно указать тип данных как float64, можно использовать такой код:
np_array = np.asarray(my_list, dtype=np.float64)
print(np_array)Таким образом, np.asarray() является гибким инструментом для преобразования данных, когда важна производительность и минимизация копирования данных, особенно если входной объект уже является массивом NumPy.
Как работать с многомерными массивами после преобразования list в numpy массив
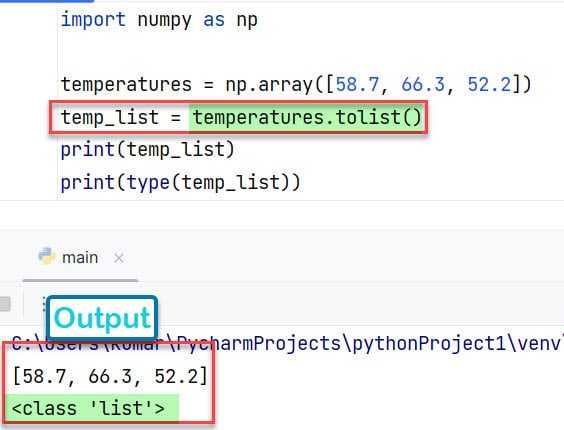
После преобразования обычного списка Python в numpy массив, работа с многомерными структурами данных становится значительно проще благодаря мощным функциональным возможностям библиотеки. Рассмотрим, как эффективно использовать numpy для обработки многомерных массивов.
1. Индексация и срезы
Для многомерных массивов numpy поддерживает индексацию и срезы по каждому измерению. Например, если у вас есть двумерный массив, вы можете обратиться к его элементам с помощью комбинации индексов. Допустим, у вас есть массив arr размером 3×3:
arr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
Чтобы получить элемент во втором ряду и третьем столбце, используйте:
arr[1, 2]
Для работы с срезами можно извлекать целые строки или столбцы. Например, чтобы получить второй столбец:
arr[:, 1]
2. Операции с массивами
Нumpy позволяет эффективно выполнять операции над многомерными массивами. Операции могут быть выполнены как по элементам, так и над целыми измерениями. Например, вы можете сложить два массива той же формы:
arr1 = np.array([[1, 2], [3, 4]])
arr2 = np.array([[5, 6], [7, 8]])
result = arr1 + arr2
Кроме того, можно применять универсальные функции (ufuncs), такие как np.sqrt для вычисления квадратных корней каждого элемента массива:
np.sqrt(arr)
3. Преобразование формы массива
Для изменения формы массива используйте метод reshape. Это полезно, если вам нужно изменить количество измерений. Например, если у вас есть одномерный массив, и вы хотите преобразовать его в двумерный массив:
arr = np.arange(6)
reshaped_arr = arr.reshape(2, 3)
При изменении формы важно, чтобы количество элементов оставалось неизменным, иначе операция завершится с ошибкой.
4. Использование свертки и агрегации
Для многомерных массивов numpy предоставляет методы для свертки данных (например, sum, mean) по определенным осям. Например, чтобы найти сумму элементов по столбцам, можно использовать:
arr.sum(axis=0)
Чтобы вычислить среднее значение по строкам:
arr.mean(axis=1)
5. Маскировка данных
С помощью масок можно работать с подмножествами данных. Например, для фильтрации всех элементов массива, которые больше 5, используйте:
arr[arr > 5]
Это позволяет вам извлекать данные на основе условий, что очень полезно при обработке больших массивов.
6. Векторизация
Векторизация – это процесс применения операций ко всем элементам массива без использования явных циклов. Это значительным образом улучшает производительность. Например, вы можете умножить все элементы массива на 2 без цикла:
arr * 2
Такой подход значительно ускоряет выполнение операций по сравнению с традиционными циклами Python.
Вопрос-ответ:
Какие преимущества дает использование numpy массива вместо обычного списка?
Использование numpy массивов имеет несколько преимуществ. Во-первых, numpy массивы работают быстрее, чем обычные списки Python, особенно при выполнении математических операций. Они занимают меньше памяти, так как имеют фиксированный тип данных и оптимизированы для работы с большими объемами числовых данных. Например, при обработке больших наборов данных или при выполнении сложных вычислений numpy массивы значительно эффективнее обычных списков.