Сортировка двумерного массива в Python – это задача, которая может быть полезна в различных приложениях, от обработки данных до оптимизации алгоритмов. В языке Python для работы с массивами удобно использовать библиотеку NumPy, а также стандартные структуры данных, такие как list и sorted(). Важно понимать, как эффективно сортировать элементы массива в зависимости от структуры данных и цели.
Для сортировки двумерного массива можно применить разные подходы в зависимости от нужной сортировки: по строкам или по столбцам. В первом случае алгоритм будет сортировать внутренние элементы каждого списка, во втором – значения по столбцам, оставляя строки неизменными. Рассмотрим, как это сделать при помощи стандартных инструментов Python, а также обсудим особенности применения библиотеки NumPy, которая оптимизирует работу с многомерными массивами.
Основной метод сортировки двумерных массивов в Python – это использование функции sorted() или метода sort(), но их недостаток в том, что они не всегда удобны для работы с многомерными массивами, поскольку требуют предварительной подготовки данных. Библиотека NumPy же предоставляет более мощные и гибкие решения, такие как numpy.sort() и numpy.argsort(), которые позволяют легко работать с двумерными массивами и сортировать данные с минимальными затратами времени и усилий.
Сортировка строк двумерного массива по возрастанию в Python

Для сортировки строк двумерного массива по возрастанию в Python можно использовать функцию sorted() или метод sort(), в зависимости от требований к исходному массиву.
Если необходимо отсортировать строки массива по возрастанию значений внутри каждой строки, можно воспользоваться следующим методом:
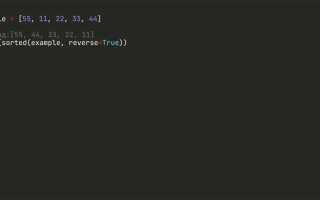
arr = [[3, 1, 2], [5, 4, 6], [8, 7, 9]]
sorted_arr = [sorted(row) for row in arr]
Этот код применяет функцию sorted() к каждой строке массива, возвращая новый массив с отсортированными строками. Исходный массив при этом остается неизменным.
Если требуется отсортировать строки двумерного массива по возрастанию значений по каждому столбцу, то можно использовать функцию sorted() с ключом сортировки:
arr = [[3, 1, 2], [5, 4, 6], [8, 7, 9]]
sorted_arr = sorted(arr, key=lambda x: x[0]) # Сортировка по первому элементу каждой строки
Здесь строки сортируются на основе значений первого элемента в каждой строке. Для сортировки по другим столбцам следует изменить индекс в lambda функции.
Также можно использовать метод sort() для сортировки на месте, что изменит исходный массив:
arr = [[3, 1, 2], [5, 4, 6], [8, 7, 9]]
arr.sort(key=lambda x: x[0]) # Сортировка на месте
Это изменит порядок строк массива, сортируя их по возрастанию значений первого элемента каждой строки.
Важно учитывать, что сортировка строк на основе отдельных столбцов позволяет решать задачи, где ключевым фактором является порядок элементов в столбцах массива, а не самих строк.
Как отсортировать столбцы двумерного массива по убыванию
Для сортировки столбцов двумерного массива по убыванию в Python можно воспользоваться библиотекой NumPy. Это позволит легко работать с массивами и эффективно манипулировать их содержимым. Рассмотрим, как выполнить эту задачу шаг за шагом.
Первый шаг – создание двумерного массива. Используем для этого функцию numpy.array(). Например:
import numpy as np
array = np.array([[12, 5, 8], [7, 14, 3], [9, 10, 6]])В данном примере у нас есть двумерный массив, состоящий из 3 строк и 3 столбцов. Следующий шаг – сортировка каждого столбца по убыванию. Для этого применим функцию numpy.sort() с параметром axis=0, что позволяет сортировать столбцы, а не строки.
sorted_array = np.sort(array, axis=0)[::-1]Здесь [::-1] инвертирует порядок сортировки, превращая его в убывающий. Результат будет следующим:
array([[12, 14, 8],
[9, 10, 6],
[7, 5, 3]])Теперь каждый столбец отсортирован по убыванию. Такой подход работает для любых типов данных, поддерживающих сравнение, включая целые числа и вещественные числа.
Если нужно отсортировать столбцы с сохранением исходных индексов строк, можно воспользоваться другим методом. Для этого сначала создаем индекс для каждого столбца, а затем сортируем его. Например:
sorted_array = np.array([np.sort(array[:, col])[::-1] for col in range(array.shape[1])]).TЗдесь array[:, col] выбирает данные из конкретного столбца, np.sort(...)[::-1] выполняет сортировку по убыванию, а .T транспонирует массив обратно, чтобы сохранить структуру двумерного массива.
Этот метод может быть полезен, если необходимо сохранить порядок строк в самом массиве, не изменяя их. Важно помнить, что сортировка по убыванию работает корректно только в случае, если данные в столбцах имеют сравнимые типы (например, все элементы – целые числа или все – строки).
Таким образом, для сортировки столбцов двумерного массива по убыванию можно использовать функции NumPy с различными подходами, в зависимости от специфики задачи.
Использование функции sorted() для сортировки двумерного массива
Функция sorted() в Python предоставляет удобный способ сортировки элементов, включая двумерные массивы. В отличие от метода sort(), sorted() возвращает новый отсортированный список, не изменяя исходный массив. Это делает её полезной для работы с массивами, где необходимо сохранить оригинальные данные.
Чтобы отсортировать двумерный массив с помощью sorted(), необходимо учитывать, по какому критерию будет происходить сортировка. Обычно сортировка применяется по элементам внутренних списков или по определённому столбцу массива.
Рассмотрим несколько вариантов применения функции sorted() для двумерных массивов:
- Сортировка по элементам внутренних списков: Для этого передаём двумерный массив в
sorted()с указанием ключа для сортировки по элементам каждого подмассива.
Пример сортировки двумерного массива по элементам внутри каждого подмассива:
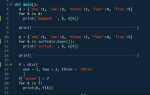
array = [[3, 1, 4], [1, 5, 9], [2, 6, 5]]
sorted_array = [sorted(sublist) for sublist in array]
print(sorted_array)
В данном примере каждый внутренний список сортируется по возрастанию.
- Сортировка по значениям в одном столбце: Для этого используем параметр
keyс функцией, извлекающей элемент по определённому индексу в подмассиве.
Пример сортировки двумерного массива по первому элементу каждого подмассива:
array = [[3, 1, 4], [1, 5, 9], [2, 6, 5]]
sorted_array = sorted(array, key=lambda x: x[0])
print(sorted_array)
Здесь массив сортируется по первому числу в каждом подмассиве, то есть по индексу 0.
- Сортировка в обратном порядке: Чтобы отсортировать массив в убывающем порядке, необходимо передать параметр
reverse=Trueв функциюsorted().
Пример сортировки массива по второму элементу каждого подмассива в обратном порядке:
array = [[3, 1, 4], [1, 5, 9], [2, 6, 5]]
sorted_array = sorted(array, key=lambda x: x[1], reverse=True)
print(sorted_array)
В данном случае двумерный массив будет отсортирован по второму элементу каждого подмассива, но в убывающем порядке.
Таким образом, sorted() предоставляет гибкие возможности для сортировки двумерных массивов, позволяя сортировать их по любым критериям, будь то элементы внутри подмассивов или элементы в определённых столбцах.
Как отсортировать двумерный массив по нескольким критериям

Для сортировки двумерного массива по нескольким критериям в Python можно воспользоваться функцией sorted() с параметром key, который позволяет задавать сложные условия сортировки. Каждый элемент двумерного массива представляет собой вложенный список, и сортировать его можно по значениям этих вложенных списков.
Предположим, у нас есть массив, в котором каждый элемент – это список, содержащий, например, имя, возраст и зарплату. Для сортировки по нескольким критериям нужно комбинировать лямбда-функции в параметре key.
Пример:
data = [
["Иван", 25, 50000],
["Петр", 30, 45000],
["Алексей", 25, 60000],
["Мария", 30, 55000]
]
sorted_data = sorted(data, key=lambda x: (x[1], x[2]))
В этом примере сортировка происходит сначала по возрасту (x[1]), а затем по зарплате (x[2]). Если возраст одинаков, то порядок элементов будет определяться по зарплате.
Можно использовать любые условия сортировки, комбинируя индексы списка. Если требуется сортировка по убыванию, можно добавить оператор - перед значениями:
sorted_data = sorted(data, key=lambda x: (-x[1], -x[2]))
Этот пример отсортирует массив сначала по возрасту в убывающем порядке, а затем по зарплате также в убывающем порядке.
Если нужно выполнить сортировку по нескольким критериям с учетом разных направлений (по возрастанию для одного критерия и по убыванию для другого), это также легко реализуется с помощью лямбда-функции, комбинирующей различные операции сортировки.
Методы сортировки с сохранением индексов элементов в Python
В Python можно сортировать двумерные массивы, сохраняя информацию об исходных индексах элементов, что может быть полезно для восстановления порядка данных после сортировки. Для этого применяются разные подходы, позволяющие отслеживать индексы и отсортированные элементы одновременно.
Один из популярных способов – использование встроенной функции sorted() с параметром key и сохранением индексов. Этот метод часто применяется в задачах, где важно отсортировать данные и затем работать с их индексами.
Пример: если есть двумерный массив, и нужно отсортировать строки по значениям в одном из столбцов, можно использовать следующий подход:
array = [[1, 5, 3], [4, 2, 7], [9, 6, 8]]
sorted_array = sorted(enumerate(array), key=lambda x: x[1][0])
Здесь enumerate(array) возвращает пару (индекс, строка), а key=lambda x: x[1][0] сортирует массив по первому элементу каждой строки. После сортировки индексы сохраняются, что позволяет отслеживать исходные позиции элементов.
Другой подход – использование библиотеки numpy, которая имеет удобные функции для работы с многомерными массивами. Например, метод argsort() возвращает индексы, которые могут быть использованы для сортировки массива. Рассмотрим пример:
import numpy as np
array = np.array([[1, 5, 3], [4, 2, 7], [9, 6, 8]])
sorted_indices = array[:, 0].argsort() # Сортируем по первому столбцу
sorted_array = array[sorted_indices]
Здесь argsort() возвращает индексы, которые затем используются для перестановки строк. Это позволяет отсортировать двумерный массив и сохранить связи между элементами и их индексами.
Для сохранения индексов при сортировке можно также использовать методы библиотеки pandas, если массив представлен в виде DataFrame. В этом случае метод sort_values() позволяет отсортировать данные, при этом индексы строк сохраняются:
import pandas as pd
df = pd.DataFrame([[1, 5, 3], [4, 2, 7], [9, 6, 8]], columns=['A', 'B', 'C'])
df_sorted = df.sort_values(by='A')
Таким образом, сортировка сохраняет оригинальные индексы строк, что удобно для работы с большими объемами данных, где важно не потерять первоначальные позиции элементов.
Использование каждого из этих методов зависит от задачи и предпочтений в выборе библиотек. Важно, что все эти подходы позволяют сохранять индексы при сортировке, что делает процесс более гибким и удобным при работе с массивами данных в Python.
Решение проблемы сортировки массива с разными типами данных в строках
Когда в строках двумерного массива присутствуют различные типы данных (например, числа и строки), возникает необходимость обработки этих типов при сортировке. В Python можно легко столкнуться с ошибками сортировки, если не учитывать типы элементов. Рассмотрим способы решения этой проблемы.
Основной подход заключается в определении правильного порядка для сравнения различных типов. Для этого нужно использовать ключи сортировки, которые преобразуют данные в единый тип, с которым Python сможет работать корректно.
Пример на Python:
data = [
[1, "apple", 3.5],
[2, "banana", 1.2],
[3, "orange", 2.8]
]
sorted_data = sorted(data, key=lambda x: (x[0], str(x[1]), x[2]))
В данном примере:
- Сортировка осуществляется по первому элементу (целое число), второму элементу (строка), третьему элементу (вещественное число).
- Используется ключ сортировки, который сначала приводит второй элемент строки к строковому типу для корректного сравнения (для строк в разных регистрах и различных типов данных).
Если нам нужно использовать более сложную логику сортировки, можно воспользоваться функцией cmp_to_key из модуля functools, которая позволяет написать пользовательскую функцию для сравнения элементов.
Пример с cmp_to_key:
from functools import cmp_to_key
def custom_compare(x, y):
# Сравнение числовых значений
if x[0] != y[0]:
return x[0] - y[0]
# Сравнение строк
if x[1] != y[1]:
return (x[1] > y[1]) - (x[1] < y[1])
# Сравнение чисел с плавающей точкой
return (x[2] > y[2]) - (x[2] < y[2])
sorted_data = sorted(data, key=cmp_to_key(custom_compare))
Этот подход полезен, когда порядок сортировки не сводится к простому преобразованию типов и требует сложной логики.
Еще одна ситуация, с которой можно столкнуться – это необходимость сортировать только по одному из элементов, оставляя другие типы данных без изменений. Например, если строки содержат как числа, так и строки, но сортировать нужно только по числовым значениям:
data = [
[1, "apple", 3.5],
[2, "banana", 1.2],
[3, "orange", 2.8]
]
sorted_data = sorted(data, key=lambda x: x[2])
Здесь сортировка происходит только по третьему элементу (вещественному числу), что дает гибкость в работе с массивами смешанных типов данных.
Чтобы избежать ошибок, связанных с несовместимостью типов данных, важно всегда продумывать ключи сортировки, которые будут безопасно приводить элементы массива к одинаковому виду для корректного сравнения. В большинстве случаев, преобразование в строку или использование кастомных функций сравнения решает проблему сортировки данных с разными типами.
Вопрос-ответ:
Как отсортировать двумерный массив по строкам в Python?
Для сортировки двумерного массива по строкам можно воспользоваться функцией `sorted()`. Пример: если у вас есть список списков, например `arr = [[3, 2], [1, 4], [5, 0]]`, вы можете отсортировать его по каждому подсписку с помощью кода: `sorted(arr)`. Это отсортирует элементы в каждом подсписке по возрастанию. Если нужно отсортировать строки в порядке убывания, можно использовать параметр `reverse=True`.
Можно ли отсортировать двумерный массив по определенному столбцу?
Да, для сортировки двумерного массива по столбцу в Python можно использовать функцию `sorted()` с ключом, который указывает на индекс столбца. Например, если нужно отсортировать массив по второму столбцу, используйте: `sorted(arr, key=lambda x: x[1])`, где `x[1]` означает доступ к элементу второго столбца. Для сортировки по убыванию добавьте параметр `reverse=True`.