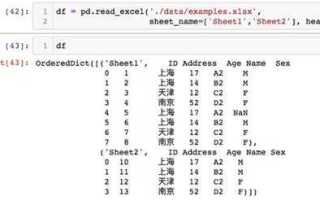
Одной из частых задач при работе с данными в Python является экспорт DataFrame в формат Excel. Этот процесс может быть полезен для анализа, визуализации или обмена данными с коллегами, особенно когда требуется сохранить результаты обработки в удобном и распространённом формате. В Python для этого идеально подходит библиотека pandas, которая имеет встроенные функции для работы с файлами Excel. В этом руководстве мы подробно разберём, как быстро и эффективно сохранить данные из DataFrame в файл Excel.
При сохранении данных важно учитывать несколько аспектов. Например, если вам нужно записать несколько DataFrame в один файл, можно использовать аргумент sheet_name, чтобы указать разные листы для каждого DataFrame. В случае работы с большими данными стоит обратить внимание на параметры, такие как index и header, чтобы корректно настроить экспорт и избежать лишних столбцов или строк в итоговом файле.
Установка необходимых библиотек для работы с Excel в Python
Для работы с Excel в Python используются две популярные библиотеки: pandas и openpyxl. Pandas предоставляет высокоуровневые структуры данных, такие как DataFrame, которые позволяют удобно работать с таблицами. Openpyxl же служит для чтения и записи файлов Excel в формате .xlsx.
1. Установка pandas:
Чтобы начать работать с pandas, достаточно установить библиотеку через pip. Для этого выполните команду в командной строке:
pip install pandaspandas автоматически устанавливает необходимые зависимости, такие как numpy, которые обеспечивают работу с массивами данных.
2. Установка openpyxl:
Для записи данных в формат Excel (.xlsx) с помощью pandas необходимо установить openpyxl. Это можно сделать с помощью следующей команды:
pip install openpyxlПосле установки этой библиотеки pandas будет использовать openpyxl для экспорта данных в Excel.
3. Проверка установки:
Для проверки успешной установки библиотек можно выполнить небольшой скрипт:
import pandas as pd
# Создаем небольшой DataFrame
df = pd.DataFrame({'Название': ['Алиса', 'Боб', 'Чарли'], 'Возраст': [25, 30, 35]})
# Записываем DataFrame в файл Excel
df.to_excel('output.xlsx', index=False, engine='openpyxl')
Этот код создаст Excel-файл output.xlsx с данными из DataFrame. Важно, чтобы указанный параметр engine=’openpyxl’ был явно задан, если используете openpyxl для записи.
Эти шаги обеспечат вас необходимыми инструментами для работы с файлами Excel в Python, предоставляя возможности для чтения, анализа и записи данных в удобном формате.
Как создать DataFrame и подготовить его для сохранения
Чтобы создать DataFrame, необходимо использовать библиотеку pandas, которая предоставляет удобные функции для работы с табличными данными. Прежде чем сохранить DataFrame в Excel, важно правильно подготовить данные.
Для начала создадим DataFrame, используя словарь, список или другие структуры данных. Важно, чтобы структура данных была последовательной, и все столбцы имели одинаковую длину. Например:
import pandas as pd
# Создание DataFrame из словаря
data = {
'Имя': ['Иван', 'Мария', 'Алексей'],
'Возраст': [25, 30, 28],
'Город': ['Москва', 'Санкт-Петербург', 'Новосибирск']
}
df = pd.DataFrame(data)
После создания DataFrame можно выполнить несколько подготовительных шагов:
- Проверка на пустые значения: Если в DataFrame есть пустые ячейки, их нужно либо заполнить, либо удалить. Для этого можно использовать методы
isnull()иdropna(). - Преобразование типов данных: Для правильного сохранения в Excel важно, чтобы данные в столбцах имели соответствующие типы. Например, для дат можно использовать
pd.to_datetime(), а для числовых значений –astype(). - Переименование столбцов: Если нужно, можно переименовать столбцы для улучшения читаемости. Для этого используйте метод
rename(). - Сортировка данных: Если порядок строк важен, отсортируйте DataFrame с помощью метода
sort_values(). - Удаление дубликатов: Для очистки данных от повторяющихся строк используйте метод
drop_duplicates().
После выполнения этих шагов ваш DataFrame будет готов к сохранению в Excel. Теперь вы можете перейти к сохранению, используя метод to_excel(), при этом стоит обратить внимание на аргументы, такие как index=False, чтобы не сохранять индекс в файле.
Сохранение DataFrame в Excel с использованием pandas
Для сохранения объекта DataFrame в формат Excel в Python используется метод to_excel() библиотеки pandas. Это простое и мощное решение позволяет быстро экспортировать данные в файл Excel, поддерживающий несколько листов и разнообразные форматы ячеек.
Чтобы сохранить DataFrame в файл Excel, достаточно передать его в метод to_excel(), указав имя файла. По умолчанию данные будут записаны в первый лист файла, но можно указать и другое имя листа с помощью параметра sheet_name.
Пример простого сохранения DataFrame в Excel:
import pandas as pd
df = pd.DataFrame({
'Имя': ['Иван', 'Мария', 'Петр'],
'Возраст': [25, 30, 22]
})
df.to_excel('data.xlsx', index=False)В этом примере файл будет сохранен под именем data.xlsx, а параметр index=False исключает запись индекса DataFrame в файл.
Если необходимо сохранить несколько DataFrame в одном файле, можно использовать объект ExcelWriter, который позволяет записывать данные на несколько листов. Для этого указываются имена листов в параметре sheet_name.
Пример записи нескольких DataFrame в один Excel файл:
with pd.ExcelWriter('multi_sheet_data.xlsx') as writer:
df1.to_excel(writer, sheet_name='Лист 1', index=False)
df2.to_excel(writer, sheet_name='Лист 2', index=False)Если файл Excel уже существует, pandas по умолчанию перезапишет его. Чтобы добавлять данные в существующий файл, нужно использовать параметр mode='a' и библиотеку openpyxl для работы с Excel в режиме добавления.
Для работы с более сложными случаями, такими как стилизация ячеек, объединение ячеек или установка ширины столбцов, можно использовать дополнительные возможности библиотеки openpyxl или xlsxwriter, которые интегрируются с pandas.
Как настроить имя файла и путь для сохранения

При сохранении DataFrame в Excel с помощью библиотеки pandas важно правильно настроить путь и имя файла. Это помогает избежать ошибок при сохранении и позволяет организовать файлы по папкам для удобства работы.
Для настройки пути и имени файла используется параметр `path` в функции `to_excel()`. Путь может быть как абсолютным, так и относительным. Например, если нужно сохранить файл в папке «output» в текущем рабочем каталоге, можно указать путь: `output/filename.xlsx`.
Для абсолютного пути указывайте полный путь к файлу, например: `/home/user/data/filename.xlsx` на Linux или `C:\\Users\\User\\Documents\\filename.xlsx` на Windows. Использование абсолютных путей гарантирует, что файл будет сохранён в нужной директории, независимо от текущего рабочего каталога.
Также важно учитывать, что имя файла не должно содержать запрещённых символов, таких как `:/?<>|*` в Windows, или символов с особыми значениями в других операционных системах. Если необходимо использовать динамические имена файлов (например, с датой), можно воспользоваться функцией `datetime` для добавления текущей даты в имя файла:
from datetime import datetime
filename = f"data_{datetime.now().strftime('%Y-%m-%d')}.xlsx"
В результате получится имя файла, включающее текущую дату, что помогает легко отслеживать версионность данных.
Если путь или имя файла задано неверно, pandas выдаст ошибку. Поэтому всегда проверяйте корректность пути перед выполнением сохранения. Также рекомендуется заранее проверять существование папки с помощью модуля `os`, чтобы избежать ошибок, связанных с отсутствием директории:
import os
if not os.path.exists('output'):
os.makedirs('output')
Этот код создаст папку «output», если она ещё не существует, и предотвратит ошибки при попытке сохранить файл.
Использование различных форматов Excel: .xls vs .xlsx
Файл .xls имеет ограничение на количество строк в 65 536 и столбцов в 256. Этот формат подходит для небольших объемов данных, но для работы с большими таблицами он неудобен. В то время как .xlsx поддерживает до 1 048 576 строк и 16 384 столбцов, что делает его более гибким для анализа больших данных.
Кроме того, формат .xlsx использует XML-базированную структуру, что позволяет работать с файлами более эффективно. В отличие от .xls, который хранит данные в бинарном формате, .xlsx файлы занимают меньше места на диске и легче поддаются обработке с использованием различных библиотек, например, openpyxl или pandas.
Формат .xlsx также поддерживает более широкий набор функций, включая улучшенные возможности для работы с графиками, форматированием ячеек, фильтрами и условным форматированием. Это делает .xlsx предпочтительным вариантом для более сложных таблиц и отчетов.
Выбор между .xls и .xlsx зависит от ваших нужд. Если вы работаете с устаревшими версиями Excel или нужна совместимость с более старыми программами, используйте .xls. Однако если вам требуется работать с большими объемами данных или использовать расширенные возможности Excel, формат .xlsx будет лучшим выбором.
Сохранение нескольких DataFrame в одном Excel-файле с несколькими листами
В Python с помощью библиотеки pandas можно эффективно сохранять несколько DataFrame в одном Excel-файле, распределяя данные по разным листам. Это полезно, когда требуется объединить различные таблицы в одном документе для удобства анализа или передачи.
Для выполнения этой задачи используется класс ExcelWriter из библиотеки pandas, который позволяет записывать несколько DataFrame в одном файле Excel. Рассмотрим пошаговую инструкцию для выполнения данной операции.
- Импорт необходимых библиотек:
- Для начала необходимо импортировать
pandasиExcelWriter. - Также нужно установить библиотеку
openpyxl, которая используется для записи в формат.xlsx.
- Для начала необходимо импортировать
- Создание нескольких DataFrame:
- Для примера создадим два DataFrame. Один будет содержать информацию о сотрудниках, а другой – данные о продажах.
- Использование ExcelWriter для записи:
- Создайте объект
ExcelWriter, указав путь к файлу и используемую библиотекуopenpyxlдля записи в формат .xlsx. - Каждый DataFrame можно записать на отдельный лист с помощью метода
to_excel, передав параметрsheet_nameдля указания имени листа.
- Создайте объект
- Запись данных:
- После записи всех DataFrame в нужные листы необходимо вызвать метод
save()для сохранения файла. - Важно закрыть объект
ExcelWriter, чтобы все изменения были зафиксированы в файле.
- После записи всех DataFrame в нужные листы необходимо вызвать метод
Пример кода для сохранения нескольких DataFrame:
import pandas as pd
# Создание примера DataFrame
df1 = pd.DataFrame({'Имя': ['Алексей', 'Мария', 'Иван'], 'Должность': ['Менеджер', 'Инженер', 'Аналитик']})
df2 = pd.DataFrame({'Дата': ['2025-01-01', '2025-02-01', '2025-03-01'], 'Продажи': [100, 150, 200]})
# Использование ExcelWriter для записи
with pd.ExcelWriter('output.xlsx', engine='openpyxl') as writer:
df1.to_excel(writer, sheet_name='Сотрудники', index=False)
df2.to_excel(writer, sheet_name='Продажи', index=False)
В результате выполнения этого кода, Excel-файл output.xlsx будет содержать два листа: «Сотрудники» с данными из первого DataFrame и «Продажи» с данными из второго.
Рекомендации:
- Для работы с большим количеством данных или для записи более 10 листов можно использовать формат
xlsx, который поддерживает множество листов, в отличие от формата.xls. - При записи данных в несколько листов следует убедиться, что имена листов уникальны, чтобы избежать перезаписи данных.
- Если нужно добавить данные в существующий файл, не перезаписывая его, используйте
ExcelWriterс параметромmode='a', который позволяет добавлять новые листы в уже созданный файл.