Регулярные выражения (регэксп) – мощный инструмент для поиска и обработки строк. В Python для работы с ними используется модуль re, который позволяет выполнять различные операции, такие как поиск, замена и разделение строк по заданному шаблону.
При создании регулярного выражения важно четко понимать, какие символы и конструкции использовать. Каждый элемент регулярного выражения имеет специфическое значение, и их правильное сочетание позволяет эффективно решать задачи по обработке текста. Для начала необходимо уметь создавать базовые шаблоны, например, для поиска конкретных слов или символов в строках. Символы вроде \d для чисел, \w для буквенно-цифровых символов и \s для пробелов являются основой для большинства регулярных выражений.
Значительное внимание стоит уделить метасимволам. Квантификаторы такие как +, * и {n,m} позволяют управлять количеством вхождений символов или групп. Например, регулярное выражение \d{2,4} найдет числа, состоящие от двух до четырех цифр. Важно не забывать, что регулярные выражения чувствительны к контексту, поэтому грамотное использование скобок и операторов может существенно улучшить точность поиска.
Для того чтобы создать более сложные и гибкие регулярные выражения, нужно освоить конструкции, такие как (?:) для незахватывающих групп и [^abc] для отрицательных классов символов. Эти и другие техники позволяют писать выразительные регулярные выражения, которые легко адаптируются под различные задачи, от валидации форм до парсинга логов.
Как использовать модуль re для работы с регулярными выражениями
Модуль re в Python предоставляет функции для работы с регулярными выражениями. Он позволяет выполнять поиск, замену и проверку строк, используя гибкие шаблоны, которые могут существенно упростить обработку текстов.
Для начала работы с модулем нужно импортировать его в код:
import reОсновные функции модуля re:
re.match(pattern, string) – проверяет, начинается ли строка с шаблона. Возвращает объект, если совпадение найдено, или None, если нет.
result = re.match(r'\d+', '123abc') # Найдет '123're.search(pattern, string) – ищет первое вхождение шаблона в строке. Возвращает объект или None.
result = re.search(r'\d+', 'abc123') # Найдет '123're.findall(pattern, string) – возвращает все непересекающиеся совпадения шаблона в строке в виде списка.
result = re.findall(r'\d+', 'abc123 def456') # ['123', '456']re.sub(pattern, repl, string) – заменяет все совпадения шаблона на строку repl.
result = re.sub(r'\d+', 'X', 'abc123 def456') # 'abcX defX're.split(pattern, string) – разбивает строку по шаблону и возвращает список.
result = re.split(r'\d+', 'abc123def456') # ['abc', 'def', '']Шаблоны регулярных выражений могут быть сложными. Например, чтобы найти все слова, начинающиеся с буквы «a», можно использовать следующий шаблон:
result = re.findall(r'\ba\w*', 'apple and banana are amazing') # ['apple', 'and', 'are', 'amazing']Важно помнить, что регулярные выражения чувствительны к регистру. Для игнорирования регистра можно использовать флаг re.IGNORECASE:
result = re.findall(r'abc', 'ABCabcAbC', re.IGNORECASE) # ['ABC', 'abc', 'AbC']Для повышения производительности и предотвращения повторных вычислений рекомендуется компилировать регулярные выражения:
pattern = re.compile(r'\d+')
result = pattern.findall('abc123 def456') # ['123', '456']Кроме того, re поддерживает использование групп в регулярных выражениях для захвата частей строки. Например:
result = re.findall(r'(\d+)', 'abc123 def456') # ['123', '456']Встроенные функции и возможности модуля re делают его мощным инструментом для работы с текстовыми данными, позволяя эффективно искать, заменять и обрабатывать строки в Python.
Как составить простое регулярное выражение для поиска подстроки
Для создания простого регулярного выражения, которое будет искать подстроку в строке, нужно понять несколько ключевых понятий. В Python для этого используется модуль re, который предоставляет функции для работы с регулярными выражениями.
Простейшее регулярное выражение – это буквально строка, которую вы хотите найти. Например, если вам нужно найти подстроку «apple», регулярное выражение будет следующим:
re.search("apple", строка)
Этот код ищет первое вхождение подстроки «apple» в строке. Функция re.search() вернет объект, если подстрока найдена, или None, если нет.
Регулярные выражения могут быть расширены для более сложных случаев. Например, для поиска всех вхождений «apple» в строке можно использовать re.findall():
re.findall("apple", строка)
Если нужно игнорировать регистр символов, добавьте флаг re.IGNORECASE:
re.search("apple", строка, re.IGNORECASE)
Такое выражение будет находить «apple», «Apple», «APPLE» и т.д.
Для уточнения поиска можно использовать специальные символы. Например, точка . заменяет любой символ, а звездочка * указывает на повторение предыдущего символа ноль или более раз. Например, выражение:
re.search("a.*e", строка)
будет искать любую строку, начинающуюся с «a» и заканчивающуюся на «e», при этом между ними может быть любой набор символов.
Таким образом, создание регулярных выражений для поиска подстрок не требует сложных конструкций, но может быть легко адаптировано под разные задачи, добавляя флаги и специальные символы для точности и гибкости поиска.
Как использовать метасимволы для создания сложных паттернов
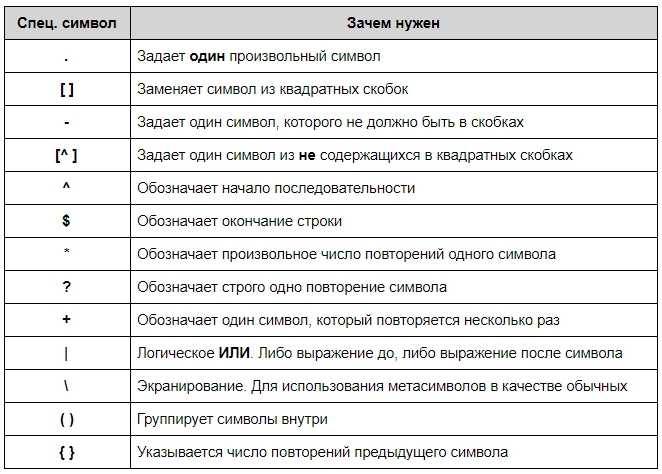
Одним из самых распространённых метасимволов является точка (.), которая соответствует любому символу, кроме символа новой строки. Для создания более точных паттернов используют квантификаторы, такие как *, +, ? и фигурные скобки ({n,m}), которые задают количество повторений. Например, паттерн a*b найдёт строки, содержащие «b» с любым количеством «a» перед ним (включая отсутствие «a»). Более сложное выражение a{2,4}b будет искать «a», повторённое от 2 до 4 раз, перед «b».
Для работы с группами символов используется квадратные скобки ([]), внутри которых указываются допустимые символы. Паттерн [a-z] найдёт любой символ от «a» до «z», а [^0-9] будет искать символы, которые не являются цифрами. Если нужно задать диапазон символов, используйте дефис внутри скобок, но с осторожностью, чтобы не перепутать его с обычным символом.
Особое внимание стоит уделить метасимволам для работы с альтернативами. Вертикальная черта (|) позволяет создать альтернативные пути. Например, выражение cat|dog найдёт как «cat», так и «dog» в строках. Это полезно при создании паттернов, которые должны искать несколько вариантов.
Для работы с границами слов и строк используют метасимволы, такие как \b и \B. \b определяет границу слова, а \B – противоположную ситуацию. Например, паттерн \bcat\b найдёт «cat» только как отдельное слово, а не как часть другого слова, например, «scattered».
Группировка с помощью скобок (()) позволяет объединять части паттернов для более сложных операций. Например, выражение (ab|cd)* будет искать «ab» или «cd», повторённые любое количество раз. Это особенно полезно для создания подмасок, которые могут захватывать отдельные фрагменты данных для дальнейшего анализа.
Не забывайте про так называемые «негативные» метасимволы, такие как (?!pattern) для отрицательных просмотрев, или (?<=pattern) для положительных просмотрев. Эти конструкции позволяют эффективно исключать или включать определённые элементы в паттерн, не захватывая их в основной результат поиска.
Когда паттерн становится сложным, важно помнить о приоритетах операций. В случае, если выражение включает несколько метасимволов, можно использовать скобки для явного указания порядка выполнения. Например, паттерн a(b|c)*d сначала определяет альтернативы «b» или «c», а затем ищет «a» и «d» в нужных местах.
Комбинируя эти метасимволы, можно создавать регулярные выражения, которые точно соответствуют сложным условиям поиска и извлечения данных из текста. Однако, важно помнить, что чрезмерное использование сложных паттернов может негативно сказаться на производительности, особенно если обработка текста происходит на больших объёмах данных.
Как применять функции match, search и findall для поиска в строках
match проверяет, начинается ли строка с подстроки, которая соответствует регулярному выражению. Если да, функция возвращает объект, представляющий результат поиска. Если нет – None.
import re
result = re.match(r'\d+', '123abc')
print(result) #
Важно, что match не ищет совпадения по всей строке, а только в начале. Если поиск требуется внутри строки, используйте search.
search ищет первое совпадение регулярного выражения в строке, независимо от того, где оно находится. Это более универсальная функция, чем match, так как она не ограничена только началом строки.
result = re.search(r'\d+', 'abc123xyz')
print(result) #
findall возвращает все неперекрывающиеся совпадения в строке. Она возвращает результат в виде списка строк, соответствующих найденным подстрокам. Если совпадений нет, возвращается пустой список.
result = re.findall(r'\d+', 'abc123xyz456')
print(result) # ['123', '456']
Функция findall полезна, когда необходимо извлечь все совпадения, а не только первое, как в случае с search.
Резюме: если нужно проверить начало строки – используйте match, для поиска первого совпадения в любом месте строки – search, а для извлечения всех совпадений – findall.
Как обрабатывать результаты поиска и извлекать данные
После того как регулярное выражение найдено, необходимо корректно обработать результаты. Для этого Python предоставляет несколько методов, позволяющих извлекать нужную информацию из найденных совпадений.
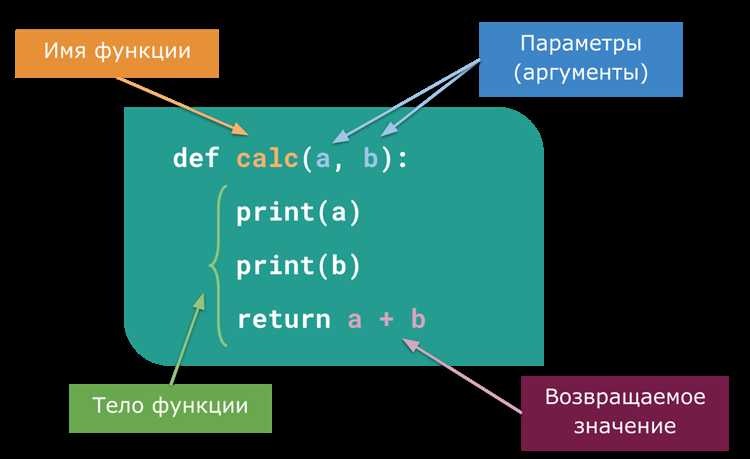
Основные способы извлечения данных:
- Метод
group()– возвращает совпавшую строку или подстроку. Используется после применения методаmatch()илиsearch(). - Метод
groups()– возвращает все группы захвата, найденные в регулярном выражении. Это полезно, если регулярное выражение включает несколько групп. - Метод
findall()– возвращает все совпадения по заданному шаблону в виде списка строк. Это удобный способ получения всех результатов поиска в тексте. - Метод
finditer()– возвращает итератор, который генерирует все совпадения в тексте. Каждый элемент итератора представляет собой объект Match, из которого можно извлечь нужные данные с помощьюgroup()илиgroups().
Пример извлечения первого совпадения с помощью метода group():
import re pattern = r'\d+' # Числа text = 'В тексте 123 и 456.' match = re.search(pattern, text) if match: print(match.group()) # Выведет '123'
Для извлечения всех чисел из строки, можно использовать findall():
numbers = re.findall(r'\d+', 'Текст 123 и 456') print(numbers) # ['123', '456']
Если регулярное выражение использует несколько групп, можно извлечь их с помощью groups():
pattern = r'(\d+)-(\d+)' # Два числа через дефис
text = '2021-2022'
match = re.search(pattern, text)
if match:
print(match.groups()) # Выведет ('2021', '2022')
Для обработки сложных данных, таких как извлечение имен и дат, можно комбинировать регулярные выражения и методы finditer():
pattern = r'([A-Za-z]+) (\d{4}-\d{2}-\d{2})'
text = 'John 2022-05-06, Alice 2021-07-15'
matches = re.finditer(pattern, text)
for match in matches:
name, date = match.groups()
print(f'Имя: {name}, Дата: {date}')
Для более сложных извлечений часто полезно использовать регулярные выражения с необязательными группами, метками или отрицательными просмотром, чтобы отфильтровывать ненужные данные.
Как тестировать регулярные выражения и избегать ошибок

Для начала используйте встроенные средства Python для тестирования регулярных выражений. Модуль re предоставляет функции, такие как re.match(), re.search() и re.findall(), которые помогут вам проверить, соответствует ли строка вашему паттерну. Например, можно сразу протестировать регулярное выражение с помощью re.fullmatch(), чтобы убедиться, что вся строка полностью удовлетворяет шаблону.
Регулярные выражения часто содержат ошибки, связанные с недочетами в символах или их последовательности. Чтобы избежать таких проблем, важно внимательно следить за экранированием символов. Например, символ . в регулярных выражениях означает "любой символ", но если вы хотите найти точку, нужно использовать \..
Инструменты онлайн-тестирования регулярных выражений, такие как regex101 и regexr, предоставляют удобную платформу для проверки регулярных выражений в реальном времени. Эти ресурсы показывают, как паттерн работает с разными строками, и могут подсказать ошибку в синтаксисе или логике выражения. Используйте их для первоначальной отладки.
Регулярные выражения должны быть максимально простыми и понятными. Использование слишком сложных паттернов может привести к трудностям в поддержке кода и ошибкам при изменении. Старайтесь писать такие выражения, которые легко понять без углубленного анализа.
Также важным моментом является тестирование регулярных выражений на различных входных данных. Регулярное тестирование на различных строках помогает выявить потенциальные проблемы, которые могут возникнуть в реальной эксплуатации. Применяйте технику "пограничных значений" – тестируйте регулярные выражения на строках минимальной длины, максимально возможной длины и на строках с неожиданными символами.
Если ваше регулярное выражение работает медленно, возможно, оно слишком сложное или избыточное. Избегайте "жадных" квантификаторов, таких как * или +, когда это не требуется. Используйте их с осторожностью, так как они могут привести к неожиданному результату при поиске.
Наконец, всегда проверяйте, как ваше регулярное выражение будет работать с потенциально плохими данными, например, с пустыми строками, пробелами, нечисловыми символами и т.д. Это помогает избежать неожиданных результатов в реальных приложениях.
Вопрос-ответ:
Что такое регулярное выражение в Python и для чего оно используется?
Регулярное выражение в Python – это последовательность символов, которая определяет шаблон для поиска или замены текста в строках. Оно используется для обработки строковых данных, например, для поиска определённых слов, проверки формата данных (например, email или телефон), а также для замены или извлечения информации из текста. Регулярные выражения позволяют эффективно выполнять операции, которые с обычными методами могли бы занять гораздо больше времени и ресурсов.