В Python часто возникает необходимость преобразования списка в словарь. Это может быть полезно при работе с данными, когда нужно сопоставить элементы списка с уникальными ключами. Важно понимать, что ключи в словаре должны быть уникальными, а значения могут быть любыми объектами Python. Рассмотрим основные способы создания словаря из списка с примерами.
Использование функции zip – один из самых распространенных и эффективных методов для преобразования двух списков в словарь. Функция zip() объединяет два списка поэлементно, создавая пары ключ-значение. Для создания словаря из этих пар достаточно применить функцию dict():
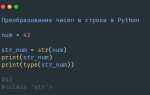
keys = ['a', 'b', 'c']
values = [1, 2, 3]
result = dict(zip(keys, values))
В данном примере результат будет таким: {'a': 1, 'b': 2, 'c': 3}.
Использование list comprehension позволяет создать словарь, если список состоит из пар данных (например, кортежей или списков), которые необходимо преобразовать в ключи и значения:
pairs = [('a', 1), ('b', 2), ('c', 3)]
result = {key: value for key, value in pairs}
Такой подход также позволяет легко добавлять дополнительные условия и фильтры для отбора данных, например:
result = {key: value for key, value in pairs if value > 1}
Реализация с использованием enumerate может быть полезна, если необходимо создать словарь с индексами элементов списка в качестве ключей. Пример:
items = ['apple', 'banana', 'cherry']
result = {index: item for index, item in enumerate(items)}
В результате получаем словарь: {0: 'apple', 1: 'banana', 2: 'cherry'}.
В зависимости от задачи и структуры исходных данных можно выбрать наиболее подходящий метод для создания словаря. Эти способы предоставляют гибкость при обработке данных и позволяют эффективно работать с большими объемами информации.
Как преобразовать список пар ключ-значение в словарь
Пример:
pairs = [('a', 1), ('b', 2), ('c', 3)]
dictionary = dict(pairs)
print(dictionary)Результат будет следующим: {'a': 1, 'b': 2, 'c': 3}. Список состоит из кортежей, где каждый кортеж представляет пару ключ-значение. Функция dict() автоматически преобразует этот список в словарь.
Если список содержит элементы, не являющиеся парами, код вызовет ошибку. Чтобы избежать этого, необходимо заранее проверить структуру данных, например, с помощью условных операторов.
Другим вариантом является использование генератора словаря. В этом случае можно пройтись по элементам списка с помощью цикла и добавить их в словарь вручную. Например:
pairs = [('a', 1), ('b', 2), ('c', 3)]
dictionary = {key: value for key, value in pairs}
print(dictionary)Этот метод даст тот же результат, но позволяет лучше контролировать процесс, если необходимо выполнить дополнительные действия с ключами или значениями перед добавлением их в словарь.
Когда ключи в списке могут повторяться, и нужно сохранить все значения для одного ключа, можно использовать defaultdict из модуля collections. Это обеспечит сбор всех значений в список для одинаковых ключей:
from collections import defaultdict
pairs = [('a', 1), ('b', 2), ('a', 3)]
dictionary = defaultdict(list)
for key, value in pairs:
dictionary[key].append(value)
print(dictionary)Результат: defaultdict(.
Использование генераторов для создания словаря
Генераторы в Python позволяют эффективно создавать словари без необходимости явного использования циклов. Такой подход позволяет сэкономить память и повысить читаемость кода.
Основная идея генератора словаря заключается в том, чтобы использовать выражения, которые создают пары ключ-значение, прямо в момент создания словаря. Генератор словаря создается аналогично генератору списка, но с использованием фигурных скобок.
Пример использования генератора для создания словаря:
numbers = [1, 2, 3, 4]
squared_dict = {num: num ** 2 for num in numbers}
print(squared_dict)Результат:
{1: 1, 2: 4, 3: 9, 4: 16}Здесь мы создаем словарь, где ключами являются элементы списка numbers, а значениями – их квадраты. Это позволяет избежать необходимости использовать циклы для итерации по списку и добавления пар в словарь.
Генераторы полезны, когда нужно создать словарь на основе существующих данных. Пример с фильтрацией:
words = ['apple', 'banana', 'cherry', 'date']
filtered_dict = {word: len(word) for word in words if len(word) > 5}
print(filtered_dict)Результат:
{'banana': 6, 'cherry': 6}В данном примере создается словарь, в котором ключами являются слова из списка words, а значениями – их длина, но только для тех слов, которые имеют более 5 символов.
Для использования более сложных выражений, например, комбинирования данных из разных источников, можно применять генераторы с несколькими циклическими конструкциями:
keys = ['a', 'b', 'c']
values = [1, 2, 3]
combined_dict = {key: value for key, value in zip(keys, values)}
print(combined_dict)Результат:
{'a': 1, 'b': 2, 'c': 3}Использование zip позволяет объединить два списка в словарь, где каждый элемент из первого списка становится ключом, а из второго – значением.
Генераторы словарей часто применяются для обработки больших объемов данных или когда нужно выполнить операции с данными по мере их обработки, не создавая промежуточных структур данных.
Преимущества использования генераторов для создания словаря:
- Снижение использования памяти, так как генератор создает элементы по мере необходимости.
- Увеличение читаемости кода, благодаря компактной записи.
- Удобство при фильтрации данных, когда нужно создать словарь с определенными условиями.
Однако важно помнить, что генераторы не сохраняют промежуточные данные, что может быть как преимуществом, так и ограничением, в зависимости от ситуации. Выбор между обычным циклом и генератором зависит от требований к производительности и читабельности кода.
Как создать словарь с уникальными ключами из списка

Чтобы создать словарь с уникальными ключами из списка, нужно учесть, что ключи в словаре должны быть неизменяемыми (например, строки или числа). Если в списке есть повторяющиеся элементы, они должны быть обработаны так, чтобы каждый ключ встречался только один раз.
Для этого можно использовать функцию dict() в сочетании с методами обработки списка, такими как set(), который автоматически удаляет дубли. Например:
my_list = ['a', 'b', 'c', 'a', 'b']
unique_dict = dict.fromkeys(set(my_list), 1)
Этот код создаст словарь, где уникальные значения из списка будут использоваться как ключи, а значением для каждого ключа будет число 1.
Если нужно задать специфические значения для каждого ключа, можно воспользоваться генераторами словарей. Пример:
my_list = ['a', 'b', 'c', 'a', 'b']
unique_dict = {key: my_list.count(key) for key in set(my_list)}
Здесь мы подсчитываем количество вхождений каждого уникального элемента списка в качестве значения для соответствующего ключа.
Если необходимо сохранить порядок элементов в исходном списке, можно использовать структуру данных dict с сохранением порядка, который гарантируется в Python 3.7 и более поздних версиях:
my_list = ['a', 'b', 'c', 'a', 'b']
unique_dict = {key: None for key in my_list}
В этом случае словарь будет содержать ключи в том порядке, в котором они встречаются в списке, но каждый ключ будет уникальным.
Метод zip() для создания словаря из двух списков
Метод zip() в Python используется для объединения нескольких итерируемых объектов (списков, кортежей и т.д.) в один. При создании словаря с помощью zip() можно эффективно сочетать два списка, один из которых будет использоваться как ключи, а второй – как значения.
Предположим, у нас есть два списка:
keys = ['a', 'b', 'c']
values = [1, 2, 3]Используя метод zip(), мы можем создать словарь следующим образом:
dict(zip(keys, values))В результате получим словарь:
{'a': 1, 'b': 2, 'c': 3}Метод zip() объединяет элементы из двух списков по порядку. Если списки имеют разную длину, то zip() будет учитывать только наименьшее количество элементов:
keys = ['a', 'b', 'c', 'd']
values = [1, 2]Результат будет следующим:
{'a': 1, 'b': 2}Чтобы избежать потери данных из-за различной длины списков, можно использовать itertools.zip_longest() для дополнения короткого списка значениями по умолчанию:
from itertools import zip_longest
dict(zip_longest(keys, values, fillvalue=None))Этот метод позволит сохранить все элементы из обоих списков. Если длина одного списка больше, то отсутствующие значения будут заменены значением None.
Важный момент: метод zip() работает с любыми итерируемыми объектами, не ограничиваясь только списками, что делает его универсальным инструментом при создании словарей.
Преобразование списка в словарь с индексами как ключами

В Python преобразовать список в словарь, используя индексы как ключи, можно несколькими способами. Один из них – использование функции enumerate(), которая позволяет получить индекс элемента при его обходе. Это полезно, когда требуется создать словарь с индексами, начиная с 0, в качестве ключей для значений списка.
Пример использования enumerate() для создания словаря:
my_list = ['apple', 'banana', 'cherry']
my_dict = dict(enumerate(my_list))
print(my_dict)Результатом выполнения этого кода будет:
{0: 'apple', 1: 'banana', 2: 'cherry'}Метод enumerate() возвращает кортежи, состоящие из индекса и соответствующего значения из списка. Функция dict() преобразует эти кортежи в пары "ключ-значение", где индекс становится ключом, а значение – значением в словаре.
Если необходимо начать индексацию с другого числа, например, с 1, можно передать параметр start в функцию enumerate():
my_dict = dict(enumerate(my_list, start=1))
print(my_dict)Этот код создаст словарь с ключами, начинающимися с 1:
{1: 'apple', 2: 'banana', 3: 'cherry'}Альтернативный способ – использование генератора словаря. В этом случае можно вручную указать индексы и соответствующие значения:
my_dict = {i: my_list[i] for i in range(len(my_list))}
print(my_dict)Этот метод создает тот же результат, что и с enumerate(), но требует явного указания индексов через функцию range().
Оба метода являются эффективными и широко используемыми для создания словаря из списка, однако enumerate() обычно является более предпочтительным из-за своей лаконичности и читаемости кода.
Как добавить значения в существующий словарь на основе списка
Пример добавления значений:
my_dict = {'a': 1, 'b': 2}
my_list = [('c', 3), ('d', 4)]
for key, value in my_list:
my_dict[key] = valueВ этом примере мы перебираем элементы списка, где каждый элемент – это кортеж с двумя значениями: ключом и значением. Эти данные добавляются в существующий словарь, обновляя его.
Другой способ – использование метода update(). Этот метод позволяет добавить сразу несколько элементов в словарь из списка, состоящего из кортежей.
my_dict.update(my_list)Вместо цикла это решение экономит код и делает операцию быстрой, добавляя пары ключ-значение в словарь.
Также, если нужно добавить только уникальные ключи, можно предварительно проверить, существует ли ключ в словаре, чтобы избежать его перезаписи:
for key, value in my_list:
if key not in my_dict:
my_dict[key] = valueЭтот способ подходит, если вы хотите добавлять только новые ключи, игнорируя уже существующие.
Обработка ошибок при создании словаря из списка
При создании словаря из списка важно учитывать возможные ошибки, которые могут возникнуть, особенно если структура данных не соответствует ожидаемому формату. Рассмотрим несколько распространенных проблем и способы их решения.
1. Несоответствие количества элементов в парах
Когда создается словарь, каждая пара значений должна быть представлена в виде кортежа из двух элементов: ключ и значение. Ошибка возникает, если в списке встречаются элементы, содержащие больше или меньше двух значений.
Пример ошибки:
list_data = [(1, 'a'), (2, 'b'), (3)] # Третий элемент имеет только один элемент dict_data = dict(list_data) # Ошибка
Решение: Необходимо убедиться, что каждый элемент списка является парой (кортежем из двух элементов). Можно использовать фильтрацию списка перед созданием словаря:
list_data = [(1, 'a'), (2, 'b'), (3,)] # Исправленный элемент list_data = [item for item in list_data if len(item) == 2] dict_data = dict(list_data) # Успешное создание словаря
2. Дублирование ключей
Если в списке содержатся несколько одинаковых ключей, при создании словаря один из них будет перезаписан. Это может привести к потере данных. Важно понимать, что словарь не допускает дублирующихся ключей.
Пример ошибки:
list_data = [(1, 'a'), (1, 'b'), (2, 'c')] dict_data = dict(list_data) # Ключ 1 перезапишет значение 'a' на 'b'
Решение: Чтобы избежать перезаписи, можно предварительно проверить наличие одинаковых ключей или объединить значения в случае дублирования:
from collections import defaultdict dict_data = defaultdict(list) for key, value in list_data: dict_data[key].append(value) dict_data = dict(dict_data) # Словарь с объединенными значениями для одинаковых ключей
3. Ошибка при попытке преобразования данных в типы, несовместимые с ключами
В Python словарь требует, чтобы ключи были неизменяемыми типами данных. Если список содержит изменяемые объекты (например, списки или другие словари), возникнет ошибка.
Пример ошибки:
list_data = [([1, 2], 'a'), ([3, 4], 'b')] dict_data = dict(list_data) # Ошибка: списки не могут быть ключами
Решение: Преобразуйте изменяемые объекты в неизменяемые перед созданием словаря:
list_data = [(tuple(item[0]), item[1]) for item in list_data] dict_data = dict(list_data) # Успешное создание словаря
4. Неправильный тип данных в значении
Если значениями в словаре ожидаются определенные типы данных, важно проверять корректность этих значений перед преобразованием. Например, если значения должны быть числами, но в список попали строки, это может вызвать неожиданные ошибки в дальнейшем.
Пример ошибки:
list_data = [(1, 'a'), (2, 'b')] dict_data = dict(list_data) # Ошибка, если ожидаются числа в значениях
Решение: Преобразуйте значения в нужный тип данных перед созданием словаря:
list_data = [(key, int(value)) if value.isdigit() else (key, 0) for key, value in list_data] dict_data = dict(list_data) # Создание словаря с обработанными значениями
Вопрос-ответ:
Что такое словарь в Python и как его можно создать?
Словарь в Python — это структура данных, которая состоит из пар "ключ-значение". Ключи в словаре должны быть уникальными, а значения могут быть любыми объектами. Чтобы создать словарь, можно использовать фигурные скобки `` и разделять ключи и значения двоеточием, например: `my_dict = {'ключ1': 'значение1', 'ключ2': 'значение2'}`. Также можно создать пустой словарь с помощью функции `dict()`: `my_dict = dict()`.
Как из списка создать словарь в Python?
Если у вас есть список, который нужно преобразовать в словарь, можно использовать функцию `dict()`, если элементы списка представляют собой пары "ключ-значение". Например, если у вас есть список: `pairs = [('a', 1), ('b', 2), ('c', 3)]`, то можно создать словарь с помощью: `my_dict = dict(pairs)`. Это создаст словарь: `{'a': 1, 'b': 2, 'c': 3}`.
Можно ли создать словарь из списка, где элементы не являются парами "ключ-значение"?
Да, можно. Если у вас есть список, состоящий из одиночных элементов, и вы хотите использовать их в качестве ключей, а значениями будут какие-то другие данные (например, индекс каждого элемента), то можно создать словарь с помощью генераторов. Пример: если есть список `['apple', 'banana', 'cherry']`, и вы хотите, чтобы ключами были элементы списка, а значениями их индексы, можно сделать так: `my_dict = {item: index for index, item in enumerate(['apple', 'banana', 'cherry'])}`. Получится словарь: `{'apple': 0, 'banana': 1, 'cherry': 2}`.
Как можно использовать метод zip() для создания словаря из двух списков?
Метод `zip()` позволяет объединить два списка в последовательности пар. Если вам нужно создать словарь из двух списков, один из которых будет использоваться как ключи, а другой — как значения, можно сделать это с помощью функции `dict()`. Например, если у вас есть два списка: `keys = ['a', 'b', 'c']` и `values = [1, 2, 3]`, то можно создать словарь следующим образом: `my_dict = dict(zip(keys, values))`. Это создаст словарь: `{'a': 1, 'b': 2, 'c': 3}`.