Разработка голосового помощника на Python – это задача, которая сочетает в себе использование нескольких технологий: распознавания речи, синтеза речи и обработки естественного языка. Один из самых популярных инструментов для этого – библиотека SpeechRecognition, которая позволяет эффективно конвертировать аудиофайлы в текст, что является основой для большинства голосовых интерфейсов. Для синтеза речи часто используют pyttsx3, который работает без подключения к интернету и поддерживает различные языки.
Первый шаг в создании голосового помощника – это выбор библиотек и инструментов для реализации. Для распознавания речи можно использовать Google Web Speech API, но она требует подключения к интернету. Важно помнить, что для качественного распознавания необходимо обучить модель на различных акцентах и шумах. Дополнительно стоит обратить внимание на точность работы модели в зависимости от качества микрофона и окружения, в котором будет работать помощник.
Чтобы ваш голосовой помощник мог не только слушать, но и отвечать, потребуется интеграция с синтезатором речи. Библиотека pyttsx3 позволяет легко генерировать голосовые ответы. Это важно для создания полноценного диалога, а не однонаправленного взаимодействия. Также можно рассмотреть использование gTTS (Google Text-to-Speech), если необходимо подключение к интернету для получения высококачественного синтеза.
Когда базовая функциональность настроена, следующий этап – это обработка запросов. Здесь в дело вступают более сложные инструменты, такие как spaCy или NLTK, которые позволяют анализировать текст и извлекать ключевую информацию. Они могут быть полезны, если нужно реализовать сложную логику или дать возможность помощнику распознавать команды в контексте.
Выбор библиотеки для обработки речи и синтеза голоса

Для распознавания речи одной из самых распространённых библиотек является SpeechRecognition. Она предоставляет простой интерфейс для работы с различными движками распознавания, включая Google Web Speech API, Microsoft Bing Voice Recognition и другие. Несмотря на высокую точность и поддерживаемые языки, стоит учитывать, что для использования некоторых движков требуется наличие интернета.
Если же нужна работа в оффлайн-режиме, можно обратить внимание на pocketsphinx, который является частью пакета CMU Sphinx. Это решение подходит для проектов, где требуется минимальная зависимость от сети, но оно не обладает такой же точностью, как более современные онлайн-методы.
Для синтеза голоса хорошими решениями являются pyttsx3 и gTTS (Google Text-to-Speech). pyttsx3 позволяет работать с синтезом речи без интернета и поддерживает несколько голосов, а также настройки скорости и тембра. Эта библиотека хорошо подходит для настольных приложений и автоматизации. Однако качество синтезированной речи может быть ниже, чем у онлайн-решений.
Если же вам важно получить более естественное звучание, стоит обратить внимание на gTTS, который использует Google Text-to-Speech API. Он требует интернет-соединения, но способен генерировать более естественные и плавные голоса, что делает его идеальным выбором для интерактивных голосовых приложений.
Также стоит упомянуть Festival – это мощная система синтеза речи с открытым исходным кодом, которая позволяет детально настроить голосовые модели. Однако её использование требует дополнительных усилий для настройки и интеграции с Python.
В зависимости от ваших нужд, можно выбрать подходящую библиотеку, ориентируясь на требования к точности распознавания, скорости отклика, а также доступности интернета. Комбинированное использование нескольких библиотек может позволить вам достичь оптимального результата в проекте.
Настройка микрофона и обработка аудиовхода
Для создания голосового помощника на Python, необходима правильная настройка микрофона и обработка аудиовхода. Важно, чтобы захват звука был чистым, без лишних шумов и искажений. Рассмотрим ключевые шаги для настройки и работы с аудиооборудованием в Python.
Для начала потребуется установить необходимые библиотеки. Наиболее популярным инструментом для работы с аудио в Python является библиотека pyaudio, которая предоставляет удобный интерфейс для захвата и воспроизведения звука.
- Установка PyAudio:
pip install pyaudio
- Дополнительные зависимости: Для использования
pyaudioна некоторых системах могут потребоваться дополнительные библиотеки, такие какportaudioна Linux.
Теперь, когда необходимые библиотеки установлены, можно приступить к захвату аудио с микрофона.
Пример простого кода для захвата аудиопотока:
import pyaudio
# Инициализация PyAudio
p = pyaudio.PyAudio()
# Настройки аудиопотока
stream = p.open(format=pyaudio.paInt16,
channels=1,
rate=44100,
input=True,
frames_per_buffer=1024)
# Захват аудио
print("Начало записи...")
audio_data = stream.read(1024)
print("Запись завершена.")
# Закрытие потока
stream.stop_stream()
stream.close()
p.terminate()
При настройке важно учитывать следующие параметры:
- format: Определяет формат аудиоданных. Для записи в формате 16-битных целых чисел следует использовать
pyaudio.paInt16. - channels: Указывает количество каналов. Для монофонической записи используйте значение 1, для стерео – 2.
- rate: Частота дискретизации. Обычно используется значение 44100 Гц, которое является стандартом для аудио CD.
- input: Указывает, что поток будет входным (для записи).
- frames_per_buffer: Размер буфера, который будет обрабатываться за один раз.
Для фильтрации шума и улучшения качества звука можно использовать библиотеки для обработки аудио, например, numpy и scipy. Для простых задач, таких как подавление шума, можно воспользоваться алгоритмами, удаляющими фоновые звуки.
Рекомендуется использовать алгоритм спектрального вычитания для удаления шума, который эффективно уменьшает фоновые помехи при записи речи. Пример кода с использованием numpy:
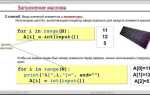
import numpy as np def remove_noise(audio_data, threshold=1000): audio_array = np.frombuffer(audio_data, dtype=np.int16) audio_array = np.where(np.abs(audio_array) > threshold, audio_array, 0) return audio_array.tobytes()
Для повышения точности распознавания речи, можно предварительно нормализовать аудиофайл, чтобы амплитуда звука не выходила за пределы допустимого диапазона. Это делается с помощью нормализации сигнала.
Кроме того, стоит учитывать работу с микрофоном. На некоторых устройствах могут возникать проблемы с задержками или низким качеством записи. Чтобы избежать этих проблем, используйте специализированные драйверы и обновления системы, а также проверьте настройки микрофона через операционную систему.
Не забывайте, что важно выбирать качественный микрофон для записи, особенно если система будет использоваться в реальном времени для взаимодействия с пользователем. Микрофоны с шумоподавлением обеспечат лучшее качество записи, чем стандартные модели.
Распознавание речи с использованием библиотеки SpeechRecognition
Библиотека SpeechRecognition предоставляет удобный интерфейс для работы с распознаванием речи в Python. Она поддерживает различные движки для распознавания, такие как Google Web Speech API, CMU Sphinx, Microsoft Bing Voice Recognition и другие. Для начала необходимо установить саму библиотеку командой:
pip install SpeechRecognition
После установки можно приступить к распознаванию речи. Для этого создадим объект recognizer, который будет работать с аудио. Например, для работы с микрофоном используется следующий код:
import speech_recognition as sr
recognizer = sr.Recognizer()
with sr.Microphone() as source:
print("Говорите...")
audio = recognizer.listen(source)
Этот код прослушивает микрофон, ожидает, пока пользователь начнет говорить, и записывает аудио в переменную audio. Для распознавания аудио можно использовать метод recognize_google, который отправляет аудио в Google Web Speech API для обработки. Пример:
try:
print("Распознавание...")
text = recognizer.recognize_google(audio, language="ru-RU")
print(f"Вы сказали: {text}")
except sr.UnknownValueError:
print("Не удалось распознать речь")
except sr.RequestError:
print("Ошибка соединения с сервисом распознавания")
Метод recognize_google отправляет аудиофайл на сервер Google для распознавания и возвращает текст. Важно помнить, что для использования этого сервиса требуется интернет-соединение. Также возможны ошибки, связанные с плохим качеством звука или недоступностью сервиса.
Для использования офлайн-распознавания можно подключить CMU Sphinx. Чтобы это сделать, необходимо установить дополнительные компоненты:
pip install pocketsphinx
После установки, чтобы использовать Sphinx вместо Google API, код будет выглядеть так:
text = recognizer.recognize_sphinx(audio)
CMU Sphinx работает быстрее и не требует интернет-соединения, однако его точность может быть ниже, особенно при распознавании сложных фраз или на фоне шума.
Для улучшения качества распознавания можно предварительно настроить параметры микрофона и фильтрацию шума. Например, перед прослушиванием аудио можно откалибровать микрофон с помощью:
recognizer.adjust_for_ambient_noise(source)
Этот метод анализирует уровень окружающего шума и корректирует чувствительность микрофона для лучшего распознавания.
Важно помнить, что распознавание речи зависит не только от библиотеки, но и от качества исходного аудио, окружающей среды и выбранного движка. Для точного распознавания необходимо использовать хороший микрофон, минимизировать фоновый шум и тщательно настраивать параметры системы распознавания.
Синтез речи с помощью pyttsx3 или gTTS

Для реализации синтеза речи в голосовом помощнике на Python можно использовать две популярные библиотеки: pyttsx3 и gTTS. Обе имеют свои особенности, и выбор зависит от задач и предпочтений разработчика.
pyttsx3 – это библиотека для синтеза речи в реальном времени, которая работает офлайн. Она поддерживает несколько голосовых движков, включая SAPI5 (Windows) и NSSpeechSynthesizer (MacOS). Это позволяет использовать произвольные голоса и изменять их характеристики, такие как скорость речи и высоту голоса. Для начала работы достаточно установить библиотеку с помощью команды:
pip install pyttsx3Для использования pyttsx3 необходимо инициализировать движок синтеза, установить настройки и вызвать метод для озвучивания текста:
import pyttsx3
engine = pyttsx3.init()
engine.setProperty('rate', 150) # Установка скорости речи
engine.setProperty('volume', 1) # Установка громкости (от 0.0 до 1.0)
engine.say("Привет, я твой голосовой помощник.")
engine.runAndWait()
В отличие от pyttsx3, gTTS (Google Text-to-Speech) использует онлайн-сервис для синтеза речи, что требует постоянного подключения к интернету. Это делает библиотеку проще в использовании, но ограничивает её возможностями при отсутствии интернета. Однако она поддерживает множество языков и акцентов, что удобно для международных проектов. Установить gTTS можно через pip:
pip install gTTSПример использования gTTS для синтеза речи:
from gtts import gTTS
import os
tts = gTTS(text="Привет, как я могу помочь?", lang='ru')
tts.save("hello.mp3")
os.system("start hello.mp3")
В этом примере создается аудиофайл, который затем воспроизводится. Библиотека gTTS также позволяет выбирать язык, голос и акцент, что делает её удобной для работы с различными аудиториями.
Рекомендация: Если вам нужно использовать синтез речи в оффлайн-режиме с настройками голосовых параметров, то предпочтительнее использовать pyttsx3. Для простых приложений или работы с несколькими языками без необходимости в локальной обработке данных gTTS будет отличным выбором.
Интеграция с интернет-сервисами для получения данных
Для создания голосового помощника на Python важно интегрировать его с интернет-сервисами, чтобы обеспечивать актуальность и разнообразие информации. Это может включать получение данных о погоде, новостях, курсах валют или других специфичных данных через API. Рассмотрим несколько важных аспектов этой интеграции.
Одним из наиболее популярных способов получения данных с интернет-сервисов является использование HTTP-запросов. В Python для этой задачи можно использовать библиотеку requests, которая позволяет отправлять GET и POST запросы к API и обрабатывать ответы в формате JSON.
Пример запроса на получение данных о погоде через открытое API OpenWeatherMap:
import requests
def get_weather(city):
api_key = 'your_api_key'
url = f'http://api.openweathermap.org/data/2.5/weather?q={city}&appid={api_key}&units=metric&lang=ru'
response = requests.get(url)
data = response.json()
return data['main']['temp'], data['weather'][0]['description']
city = "Moscow"
temperature, description = get_weather(city)
print(f"Температура в {city}: {temperature}°C, {description}")
Важно помнить, что для работы с большинством API потребуется ключ доступа, который обычно можно получить после регистрации на платформе разработчика.
Другим распространённым вариантом является использование Python-библиотеки json для работы с данными, полученными в формате JSON. При получении данных с сервера данные часто приходят в виде строки JSON, которую нужно преобразовать в объект Python для дальнейшей обработки.
Пример обработки JSON-ответа для получения курса валют с использованием API сайта exchangeratesapi.io:
import requests
import json
def get_exchange_rate(base_currency, target_currency):
url = f"https://api.exchangeratesapi.io/latest?base={base_currency}"
response = requests.get(url)
data = response.json()
return data['rates'][target_currency]
base_currency = "USD"
target_currency = "EUR"
rate = get_exchange_rate(base_currency, target_currency)
print(f"Курс {base_currency} к {target_currency}: {rate}")
Для более сложных сервисов, таких как голосовые API или API для распознавания речи (например, Google Cloud Speech API), требуется настройка аутентификации через OAuth 2.0 и использование библиотек, таких как google-auth и google-api-python-client.
Следует также учитывать, что многие интернет-сервисы имеют ограничения на количество запросов в единицу времени (rate limiting), поэтому необходимо эффективно управлять запросами, использовать кэширование или адаптировать логику приложения для уменьшения количества обращений.
Кроме того, для повышения производительности стоит использовать асинхронные запросы с помощью библиотеки aiohttp, что позволяет одновременно обрабатывать несколько запросов без блокировки основного потока выполнения программы.
Пример асинхронного запроса с использованием aiohttp:
import aiohttp
import asyncio
async def fetch_weather(city):
async with aiohttp.ClientSession() as session:
url = f'http://api.openweathermap.org/data/2.5/weather?q={city}&appid=your_api_key&units=metric&lang=ru'
async with session.get(url) as response:
data = await response.json()
return data['main']['temp'], data['weather'][0]['description']
async def main():
city = "Moscow"
temperature, description = await fetch_weather(city)
print(f"Температура в {city}: {temperature}°C, {description}")
asyncio.run(main())
Эти методы и практики позволяют эффективно интегрировать голосового помощника с интернет-сервисами и использовать актуальные данные для улучшения функционала и взаимодействия с пользователем.
Обработка команд и создание логики диалога
Основная задача при разработке голосового помощника – правильно обрабатывать команды пользователя и обеспечить естественный ход диалога. Чтобы создать гибкую и функциональную логику, важно правильно настроить несколько ключевых элементов: распознавание команд, обработку контекста и генерацию ответов.
Распознавание команд начинается с использования библиотек для работы с речью, таких как SpeechRecognition или pyaudio. Для начала необходимо настроить захват аудио и его преобразование в текст. Для этого можно использовать функцию recognizer_instance.recognize_google(), которая отправляет аудио в сервис Google для распознавания. Это требует стабильного интернет-соединения, но позволяет достичь хорошей точности.
После получения текста команды важно выделить ключевые слова, которые будут служить триггерами для различных функций. Для этого используется библиотека spaCy или NLTK, которые помогают анализировать текст и извлекать из него важные сущности. Например, в команде «Отключи свет» ключевое слово «свет» будет связано с действием выключения.
Обработка контекста диалога – важный момент, который позволяет сохранить последовательность взаимодействия с пользователем. Простая система обработки команд не может помнить прошлые запросы, что ограничивает её возможности. Для улучшения логики следует использовать хранилище контекста, например, словарь, который сохраняет информацию о текущем состоянии. Важным элементом становится система обработки состояний (state machine), где каждое состояние соответствует определённой стадии диалога. Например, если пользователь только что запросил погоду, то помощник будет помнить это и в ответах уточнять детали, если потребуется.
Генерация ответов зависит от сложностей команды и желаемого уровня взаимодействия. Простые команды, такие как включение света или воспроизведение музыки, могут быть выполнены напрямую с помощью соответствующих библиотек. Для более сложных диалогов следует использовать алгоритмы машинного обучения. Одним из популярных подходов является использование transformer-моделей, таких как GPT или Rasa, которые могут генерировать более сложные ответы, учитывая контекст общения. Важно настроить их так, чтобы ответы были релевантными и грамматически корректными, а также не создавали излишней путаницы в разговоре.
Обработка ошибок и неверных команд должна быть встроена в систему. Например, если пользователь неправильно сформулировал запрос, голосовой помощник должен предложить варианты для уточнения или дать обратную связь о проблеме. Это делает взаимодействие более плавным и менее фрустрирующим для пользователя.
Создание логики диалога для голосового помощника – это не только обработка команд, но и продуманное взаимодействие с пользователем, где важно учесть как синтаксис, так и контекст общения для предоставления качественного опыта.
Использование алгоритмов машинного обучения для улучшения точности распознавания

Основные методы, применяемые для улучшения точности распознавания:
- Глубокие нейронные сети (DNN): Использование глубоких нейронных сетей позволяет повысить точность распознавания за счет более сложных слоев обработки данных. DNN моделируют более сложные зависимости в речи и улучшают качество распознавания, особенно в шумных условиях.
- Рекуррентные нейронные сети (RNN) и LSTM: Эти алгоритмы особенно эффективны при обработке последовательностей данных, таких как речь. LSTM (Long Short-Term Memory) помогают моделям запоминать долгосрочные зависимости, что важно для контекстного понимания фраз и уменьшения ошибок при распознавании.
- Модели трансформеров: Модели на основе трансформеров, такие как BERT и GPT, значительно улучшили точность распознавания за счет использования внимания и контекстной обработки данных. Они позволяют точнее воспринимать смысл речи в зависимости от контекста и предыдущих слов.
Для дальнейшего улучшения точности можно применять методы адаптации моделей к конкретному пользователю:
- Обучение на индивидуальных данных: Сбор и анализ данных речи конкретного пользователя помогает адаптировать модель под его особенности (тембр голоса, акценты, привычки). Такой подход требует сбора достаточно разнообразных примеров речи и обработки этих данных с помощью алгоритмов машинного обучения.
- Использование фидбек-системы: Периодическое обновление модели на основе пользовательских ошибок и корректных запросов позволяет системе «учиться» на реальных примерах и повышать точность распознавания с течением времени.
Дополнительные методы для улучшения качества:
- Шумоподавление: Важным этапом обработки является фильтрация фона и шума с помощью специализированных алгоритмов. Использование методов, таких как спектральное вычитание или когнитивные фильтры, помогает улучшить точность распознавания в сложных акустических условиях.
- Акустические модели: Совершенствование акустических моделей на основе данных о звуковых характеристиках помогает повысить точность распознавания в разных условиях (разные голоса, шумы и т. д.). Использование современных подходов, таких как end-to-end модели, позволяет улучшить результаты.
Таким образом, для достижения высоких результатов в распознавании речи необходимо интегрировать различные алгоритмы машинного обучения, а также активно работать с данными пользователей и окружающими условиями. Каждый этап обучения модели способствует повышению точности и эффективности голосового помощника.
Развертывание голосового помощника на сервере или в локальной сети

Развертывание голосового помощника на сервере или в локальной сети требует внимательного подхода к выбору технологий и архитектуры. Важно, чтобы система была устойчивой, безопасной и легко масштабируемой.
Для начала нужно выбрать подходящий сервер или машину, которая будет выполнять роль хоста для голосового помощника. Это может быть как локальная машина, так и облачный сервер. При выборе железа следует учитывать требования к процессору и памяти, особенно если помощник использует ресурсоёмкие модели машинного обучения или работает с большими объемами данных.
1. Подготовка серверной среды: Использование операционной системы Linux, например, Ubuntu или CentOS, является хорошим выбором для серверных решений. Эти ОС обеспечивают стабильность и высокую производительность, что важно для работы с большими объёмами запросов и данных. На сервере необходимо установить Python и все необходимые зависимости для работы с библиотеками, такими как SpeechRecognition, PyAudio, Flask, FastAPI и другие, которые обеспечат работу с голосовыми командами и запросами.
2. Развертывание API для взаимодействия с голосовым помощником: Для взаимодействия голосового помощника с клиентскими приложениями можно использовать REST API. Рекомендуется использовать фреймворки, такие как Flask или FastAPI, которые легко интегрируются с Python-приложениями и позволяют быстро развернуть сервер для обработки HTTP-запросов. Создание API также включает в себя настройку маршрутов для обработки различных команд, получение и отправку аудио данных, а также управление сессиями пользователей.
3. Работа с локальной сетью: При развертывании в локальной сети важно правильно настроить внутреннюю сеть для обеспечения стабильной и быстрой связи между клиентами и сервером. Для этого можно использовать статический IP-адрес сервера, либо настроить динамическую привязку с помощью DHCP. Стоит также настроить фаерволы и другие меры безопасности, чтобы ограничить доступ только для нужных устройств.
4. Контроль доступа и безопасность: При развертывании голосового помощника важно предусмотреть механизмы контроля доступа. Использование аутентификации через токены или API-ключи позволит ограничить доступ к серверу для неавторизованных пользователей. Важно настроить шифрование данных, чтобы избежать утечек личной информации. SSL-сертификаты для защиты каналов связи (HTTPS) обязательны, особенно если помощник будет обрабатывать чувствительную информацию.
5. Масштабирование и нагрузка: Если планируется значительная нагрузка на систему, стоит подумать о её масштабировании. Для этого можно использовать контейнеризацию с помощью Docker, что позволит легко деплоить копии серверных приложений на разных машинах и масштабировать инфраструктуру по мере роста числа запросов. В случае необходимости можно настроить балансировщики нагрузки для распределения запросов между несколькими экземплярами сервера.
6. Мониторинг и логирование: Для успешной эксплуатации голосового помощника необходим мониторинг состояния серверов и приложений. Инструменты вроде Prometheus и Grafana помогут отслеживать производительность и нагрузку на систему. Логирование запросов и ошибок с помощью таких систем, как ELK Stack или Graylog, позволит быстро находить и устранять проблемы.
Эти шаги обеспечат стабильную работу голосового помощника в локальной сети или на сервере, минимизируя риски и увеличивая производительность. Важно не только правильно настроить инфраструктуру, но и регулярно обновлять её, следить за безопасностью и производительностью системы для обеспечения качественного обслуживания пользователей.
Вопрос-ответ:
Какой основной алгоритм используется при создании голосового помощника на Python?
Для создания голосового помощника на Python используется несколько основных библиотек и алгоритмов. Одним из популярных решений является использование библиотеки `SpeechRecognition` для преобразования речи в текст. Затем для обработки команд можно применять библиотеки, такие как `pyttsx3` для синтеза речи и `wikipedia` для поиска информации. Дополнительно для интеграции с внешними сервисами или выполнения задач, таких как управление устройствами, часто используются API, например, Google Assistant API или Alexa. Главное — это корректная обработка команд и синтезирование адекватных ответов.
Как можно добавить возможность голосового помощника выполнять задачи, такие как запуск программ или управление устройствами?
Для того чтобы голосовой помощник мог выполнять более сложные задачи, например, запускать программы или управлять устройствами, потребуется интеграция с внешними сервисами или использование дополнительных библиотек. Например, для управления устройствами можно использовать библиотеку `pyautogui`, которая позволяет автоматизировать действия на компьютере, такие как открытие программ или нажатие клавиш. Для работы с умными устройствами (например, освещением, термостатами) можно использовать сервисы как Google Assistant API или Alexa Skills Kit, которые предоставляют функционал для взаимодействия с умной техникой. Важно, чтобы голосовой помощник распознавал команды с учетом контекста и мог обращаться к этим сервисам для выполнения задач.
Что такое обработка естественного языка и как её использовать при создании голосового помощника?
Обработка естественного языка (ОНЯ) — это область искусственного интеллекта, которая занимается взаимодействием между компьютером и человеком на естественном языке. В контексте голосового помощника ОНЯ используется для того, чтобы компьютер мог понимать, интерпретировать и отвечать на команды, произнесенные пользователем. В Python для ОНЯ часто используют библиотеки, такие как **NLTK** или **spaCy**, которые предоставляют инструменты для обработки текста, выявления смысловых блоков и анализа структуры предложений. Эти технологии позволяют голосовому помощнику не просто выполнять команды, но и понимать их контекст, что делает взаимодействие более естественным и удобным.