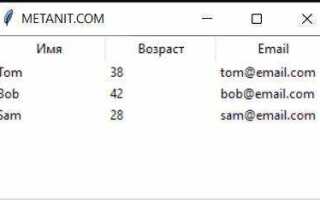
При работе с данными в Python часто возникает необходимость в представлении информации в виде таблиц. Такой подход помогает эффективно структурировать данные и удобно с ними манипулировать. Одним из методов создания таблиц является использование циклов для автоматической генерации строк и столбцов. В отличие от статичного кодирования, циклы позволяют динамически строить таблицы, что существенно упрощает работу с большими объёмами данных.
Простой пример использования циклов для создания таблицы: нужно сгенерировать таблицу умножения. Используя два вложенных цикла, можно пройти по всем комбинациям чисел и вывести результат в виде строк, где каждый элемент таблицы вычисляется на основе заданных формул. Такое решение не только сокращает количество строк кода, но и облегчает внесение изменений при необходимости масштабировать или адаптировать решение под другие задачи.
Как создать таблицу с помощью списка списков
Для создания таблицы в Python можно использовать структуру данных, такую как список списков. Это простой и удобный способ представления таблиц, где каждый внутренний список будет представлять строку таблицы, а элементы внутри этого списка – столбцы.
Пример создания таблицы:
table = [ ['Имя', 'Возраст', 'Город'], ['Иван', 25, 'Москва'], ['Анна', 30, 'Санкт-Петербург'], ['Дмитрий', 28, 'Новосибирск'] ]
В этом примере таблица содержит три строки данных и три столбца. Каждый элемент внутреннего списка соответствует отдельной ячейке таблицы. Таким образом, таблица с помощью списка списков представляется как двумерная структура.
Чтобы обратиться к конкретному элементу, например, к возрасту Анны, нужно указать индекс строки и индекс столбца. Индексация в Python начинается с нуля:
age_anna = table[1][1] # Возраст Анны
for row in table: print(row)
Этот подход удобен для работы с небольшими таблицами, где структура данных не требует сложных связей между элементами. Однако для более сложных таблиц, например, с динамическим количеством столбцов или строк, может быть целесообразно использовать библиотеки, такие как pandas.
Использование цикла for для добавления строк в таблицу
Для начала необходимо подготовить структуру таблицы. Допустим, у нас есть список данных, и мы хотим добавить их в таблицу, представленную в виде списка списков или другого типа данных, например, pandas.DataFrame. Воспользуемся списком словарей в качестве примера.
data = [
{"name": "Иван", "age": 30},
{"name": "Мария", "age": 25},
{"name": "Алексей", "age": 28}
]
table = []
for row in data:
table.append([row["name"], row["age"]])
В этом примере цикл for проходит по каждому элементу списка data, и для каждого элемента добавляет строку в таблицу table.
Важно отметить несколько моментов:
- Каждая итерация цикла добавляет в таблицу новую строку.
- Каждая строка состоит из значений, взятых из словаря (или другого источника данных).
- Таким образом, легко можно масштабировать решение для больших наборов данных.
Если нам нужно динамически изменять количество строк в таблице на основе различных условий, можно использовать условные операторы внутри цикла:
threshold = 27
table = []
for row in data:
if row["age"] > threshold:
table.append([row["name"], row["age"]])
Этот код добавит в таблицу только тех людей, чей возраст больше 27 лет.
Для работы с более сложными таблицами можно использовать библиотеки, такие как pandas. Например, при добавлении строк в pandas.DataFrame можно делать это через метод append(), но стоит помнить, что при использовании циклов и больших объемов данных производительность может снизиться. Для оптимизации лучше использовать другие методы добавления строк, такие как создание списка строк и их последующая передача в DataFrame.
import pandas as pd
df = pd.DataFrame(columns=["Name", "Age"])
for row in data:
df = df.append({"Name": row["name"], "Age": row["age"]}, ignore_index=True)
Этот подход позволяет динамически обновлять таблицу и добавлять в неё строки по мере необходимости, однако для больших наборов данных стоит учитывать производительность.
Инициализация таблицы с пустыми значениями
При создании таблицы в Python с использованием циклов для заполнения данных часто возникает необходимость инициализации структуры с пустыми значениями. В этом случае можно использовать встроенные методы и структуры данных, такие как списки и списковые выражения.
Для инициализации таблицы, представляющей собой список списков, можно применить цикл для заполнения каждого элемента пустым значением. Наиболее простой способ – это создать таблицу с пустыми строками или значениями, например, `None` или пустыми строками `»»`. Это может быть полезно для дальнейшего заполнения или обработки данных.
Пример создания таблицы размером 3×4 с пустыми значениями (используем `None` для обозначения пустоты):
rows = 3 cols = 4 table = [[None for _ in range(cols)] for _ in range(rows)]
В этом примере внешний цикл создает 3 строки, а вложенный цикл заполняет каждую строку 4 элементами с значением `None`. Такой подход позволяет легко настроить размер таблицы и обеспечить нужное количество пустых значений для последующей работы.
Если необходимо инициализировать таблицу с конкретным пустым значением, например, пустыми строками, можно заменить `None` на `»»` в примере выше:
table = [["" for _ in range(cols)] for _ in range(rows)]
Использование такого подхода удобно в тех случаях, когда значения таблицы будут заполняться или изменяться позже в ходе работы программы. Важно помнить, что выбор пустого значения зависит от контекста задачи и типа данных, с которыми предстоит работать.
Вместо использования циклов можно применить метод библиотеки NumPy для работы с многомерными массивами, что значительно ускорит процесс инициализации для больших таблиц:
import numpy as np table = np.full((rows, cols), None)
Этот способ подойдет для сложных вычислений и операций с матрицами, где важно обеспечить высокую производительность при инициализации данных.
Заполнение таблицы данными с использованием вложенных циклов
Для этого удобно использовать два или более циклов, где внешний цикл отвечает за строки, а внутренний – за столбцы. Рассмотрим пример, как можно заполнить таблицу размером 5×5 числами от 1 до 25:
table = [] for i in range(5): row = [] for j in range(5): row.append(i * 5 + j + 1) table.append(row)
Этот код создает таблицу 5×5, где каждая ячейка содержит уникальное значение. Внешний цикл (по индексу строк) создает пустую строку, а внутренний цикл заполняет ее значениями. После чего строка добавляется в список, представляющий таблицу.
Важно учитывать следующие моменты:
- Вложенные циклы можно использовать для работы с любыми структурами данных, включая двумерные массивы и более сложные объекты.
- При работе с большими таблицами важно следить за производительностью, так как вложенные циклы могут заметно увеличивать время выполнения программы, особенно если таблица очень большая.
- Внутренний цикл всегда зависит от внешнего, и их взаимодействие может сильно повлиять на логику заполнения данных.
Кроме того, можно создавать таблицы с разными типами данных. Например, если нужно создать таблицу с результатами умножения, можно использовать следующий код:
table = [] for i in range(1, 11): row = [] for j in range(1, 11): row.append(i * j) table.append(row)
В данном случае внешнее значение цикла (i) задает первый множитель, а внутреннее значение (j) – второй. Таким образом, мы заполняем таблицу произведений чисел от 1 до 10.
Использование вложенных циклов позволяет гибко работать с таблицами в Python и быстро генерировать сложные данные. Важно тщательно продумывать логику вложенности, чтобы избежать ошибок и добиться нужных результатов.
Как сгенерировать таблицу по заданной формуле
Для генерации таблицы по формуле в Python можно использовать циклы, например, для вычисления значений на основе математической формулы или функций. Рассмотрим пример: создадим таблицу значений для формулы \(y = ax + b\), где \(a\) и \(b\) — константы, а \(x\) — переменная, которая изменяется от 1 до 10.
В этом примере мы используем цикл for для итерации по значениям переменной x, вычисляя соответствующие значения y. Формула для вычисления y – это линейное выражение, но алгоритм можно легко адаптировать для более сложных формул.
Пример кода:
a = 2 # коэффициент
b = 3 # константа
# Генерация таблицы значений
for x in range(1, 11): # Перебор значений x от 1 до 10
y = a * x + b # Применение формулы
Если необходимо генерировать таблицу для более сложных функций, например, для тригонометрических или экспоненциальных, достаточно заменить выражение в строке с формулой на соответствующую функцию Python, такую как math.sin(x) или math.exp(x). Важно учитывать, что для некоторых типов функций диапазоны значений x могут быть ограничены, и это нужно учитывать при выборе интервала.
Дополнительно можно сохранить результаты в файл или в список для дальнейшей обработки, что удобно для работы с большими объемами данных. Для этого, вместо print, можно использовать добавление в список или запись в файл.
Использование циклов для изменения значений в таблице

Циклы в Python позволяют эффективно изменять данные в таблицах, представляющих собой двумерные структуры, например, списки списков или структуры данных, подобные таблицам. Применение циклов для модификации значений в таблице становится необходимостью при обработке больших объемов информации. Рассмотрим основные подходы и рекомендации.
Для начала, таблицу можно представить как список списков, где каждая вложенная структура будет строкой таблицы. Цикл позволяет пройти по всем строкам и столбцам, внося изменения в нужные элементы. Например, при обновлении значений в определённой колонке можно использовать следующий подход:
table = [
[1, "Alice", 25],
[2, "Bob", 30],
[3, "Charlie", 35]
]
for row in table:
row[2] += 1 # Увеличение возраста на 1 для каждого человека
В этом примере цикл изменяет значения в третьем столбце для каждой строки. Такой подход удобно использовать для простых вычислений, например, для добавления, вычитания или умножения значений.
Однако если требуется более сложная логика изменения, например, на основе условия, можно добавить оператор if. Например, для изменения значения в таблице в зависимости от имени:
for row in table:
if row[1] == "Bob":
row[2] = 40 # Заменить возраст на 40 для Bob
Кроме того, при необходимости работы с большими таблицами можно использовать индексы строк и столбцов. Для этого применяются циклы с диапазонами индексов. Пример:
for i in range(len(table)):
table[i][2] = table[i][2] * 1.1 # Увеличить возраст на 10% для всех
Важно помнить, что использование циклов требует оптимизации для предотвращения излишних вычислений при работе с очень большими таблицами. Например, можно обрабатывать только те строки, которые удовлетворяют определённым условиям, или параллельно работать с несколькими частями таблицы.
В случаях, когда необходимо работать с таблицами большого размера или более сложной структуры, следует рассмотреть использование библиотек, таких как pandas, которые предлагают высокоуровневые функции для манипуляции данными, включая циклические изменения значений, но с гораздо меньшими затратами на вычисления.
Поиск и замена значений в таблице через цикл

В Python для поиска и замены значений в таблице, представленной в виде списка списков или массива, можно использовать цикл, который позволит перебирать элементы и производить необходимые изменения. Рассмотрим процесс на примере двухмерного списка, где строки и столбцы содержат данные, требующие обработки.
Чтобы найти и заменить определённое значение, можно использовать вложенный цикл. Внешний цикл будет проходить по строкам, а внутренний – по элементам каждой строки. Важно заранее определить, какое значение требуется заменить, и на что оно должно быть заменено.
Пример кода:
table = [ ['John', 25, 'Engineer'], ['Alice', 30, 'Doctor'], ['Bob', 22, 'Artist'] ] target_value = 'Doctor' replacement_value = 'Scientist' for row in table: for i in range(len(row)): if row[i] == target_value: row[i] = replacement_value
В данном примере значение ‘Doctor’ заменяется на ‘Scientist’ во всех строках таблицы. Использование индексации позволяет изменять только нужные элементы без влияния на остальные данные.
Если необходимо заменить все вхождения какого-то значения в таблице, это можно сделать за один проход с использованием дополнительной проверки. Например, заменяя все вхождения числа на строку, следует учитывать тип данных, чтобы избежать ошибок преобразования.
Для более сложных операций можно использовать дополнительные условия, например, заменять значение только в тех строках, которые удовлетворяют некоторым критериям, или обновлять только значения в определённом столбце.
Метод поиска и замены с использованием цикла также полезен, когда требуется выполнить несколько операций одновременно, например, обновить сразу несколько элементов в строке в зависимости от их значений.
Для больших таблиц или массивов стоит учитывать, что операции с вложенными циклами могут существенно повлиять на производительность. В таких случаях можно рассмотреть оптимизированные структуры данных, например, использование библиотеки NumPy для работы с многомерными массивами.
Для начала, важно задать ширину столбцов таблицы. Например, если вы хотите выровнять числа по правому краю, можно использовать следующий подход:
data = [(1, 'Alice', 25), (2, 'Bob', 30), (3, 'Charlie', 35)]
for row in data:
print("{:<5} {:<10} {:>5}".format(row[0], row[1], row[2]))В данном примере {:<5} задает выравнивание по левому краю с шириной столбца 5 символов, а {:>5} – выравнивание по правому краю для числового значения.
for row in data:
print(f"{row[0]:<5} {row[1]:<10} {row[2]:>5}")Чтобы сделать таблицу более структурированной, можно добавить разделители между строками. Например, добавление горизонтальных линий для разделения заголовков и данных. Это можно легко реализовать с помощью строк:
header = ("ID", "Name", "Age")
separator = "-" * 30
print(f"{header[0]:<5} {header[1]:<10} {header[2]:>5}")
print(separator)
for row in data:
print(f"{row[0]:<5} {row[1]:<10} {row[2]:>5}")from tabulate import tabulate
print(tabulate(data, headers=["ID", "Name", "Age"], tablefmt="grid"))Вопрос-ответ:
Что такое создание таблицы в Python с использованием циклов?
Создание таблицы в Python с помощью циклов — это процесс автоматического формирования структурированных данных в виде таблицы, используя язык программирования Python. Для этого часто применяют циклы для генерации строк и столбцов таблицы. Например, можно использовать циклы для создания двумерных массивов, списков или использования библиотеки pandas для создания таблиц с динамически заполняемыми данными.
Какие библиотеки Python полезны для работы с таблицами?
Для работы с таблицами в Python наибольшее применение находят такие библиотеки, как `pandas` и `numpy`. Pandas предоставляет удобный интерфейс для создания, манипуляции и анализа таблиц данных в формате DataFrame. NumPy используется для работы с многомерными массивами и также может быть полезен для создания таблиц с числовыми данными. Эти библиотеки значительно упрощают работу с данными в таблицах и позволяют быстро манипулировать ими.