Преобразование одномерных списков в двумерные массивы в Python является распространенной задачей при работе с данными, особенно когда нужно организовать данные в виде матрицы. В Python есть несколько эффективных способов для этого, каждый из которых имеет свои особенности и преимущества в зависимости от контекста задачи.
Одним из самых простых и удобных решений является использование библиотеки NumPy, которая предоставляет широкие возможности для работы с многомерными массивами. Встроенные функции, такие как reshape(), позволяют легко изменить размерность массива. Однако если по какой-то причине вы хотите обойтись без дополнительных библиотек, можно воспользоваться стандартными средствами Python, такими как вложенные списки и циклы.
При выборе метода важно учитывать несколько факторов. Если требуется высокая производительность и работа с большими объемами данных, то стоит обратить внимание на NumPy. Для менее ресурсоемких задач или в случае, когда внешние зависимости нежелательны, можно использовать чистый Python. В обоих случаях важно правильно настроить параметры преобразования, чтобы избежать ошибок и некорректных данных.
Использование библиотеки NumPy для преобразования списка
Библиотека NumPy предоставляет эффективные инструменты для работы с массивами, включая удобные методы для преобразования списков в двумерные массивы. Один из самых популярных способов – использование функции numpy.reshape(), которая позволяет изменить форму массива, созданного из списка, и привести его к двумерной структуре.
Чтобы преобразовать список в двумерный массив с помощью NumPy, сначала необходимо создать одномерный массив с помощью numpy.array(), а затем применить reshape() для изменения его формы. Рассмотрим пример:
import numpy as np
# Создаем одномерный массив из списка
list_data = [1, 2, 3, 4, 5, 6]
array_data = np.array(list_data)
# Преобразуем в двумерный массив размером 2x3
reshaped_array = array_data.reshape(2, 3)
print(reshaped_array)
В данном примере список [1, 2, 3, 4, 5, 6] преобразуется в двумерный массив размером 2 строки и 3 столбца. Важно, чтобы количество элементов в списке совпадало с размером требуемого двумерного массива (в данном случае 2×3 = 6 элементов).
Функция reshape() удобна тем, что позволяет гибко изменять форму массива. Однако, если размеры не совпадают с количеством элементов, возникнет ошибка. В таких случаях лучше использовать проверку перед применением преобразования.
Еще один способ создания двумерного массива из списка – это использование функции numpy.newaxis. Этот метод позволяет легко добавить дополнительное измерение к массиву. Например:
array_data = np.array(list_data)
reshaped_array = array_data[:, np.newaxis] # Преобразуем в массив размером (6, 1)
print(reshaped_array)
В данном примере мы добавляем ось, превращая одномерный массив в двумерный с размерностью (6, 1).
NumPy также поддерживает функции numpy.reshape(-1, N), где -1 автоматически рассчитывает количество строк, исходя из общего числа элементов и заданного количества столбцов N. Например:
reshaped_array = array_data.reshape(-1, 3)
print(reshaped_array)
В этом случае количество строк вычисляется автоматически, а количество столбцов задается как 3.
Использование NumPy для преобразования списков в массивы – это мощный способ работы с данными в Python, который позволяет легко и быстро выполнять манипуляции с формой данных без существенных затрат на производительность.
Как разделить список на подсписки фиксированной длины
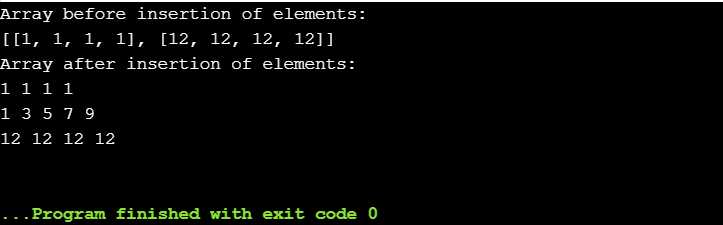
Пример реализации:
def split_list(lst, chunk_size):
return [lst[i:i + chunk_size] for i in range(0, len(lst), chunk_size)]
В этом примере функция `split_list` принимает два аргумента: сам список и размер подсписков. Она возвращает новый список, содержащий подсписки заданного размера. Важно отметить, что последний подсписок может быть короче, если размер исходного списка не делится нацело на размер подсписков.
Другой подход – использование библиотеки `itertools`, которая предоставляет функцию `islice` для удобного разбиения списка. Этот метод полезен, когда нужно работать с большими объемами данных, так как он не создает промежуточных копий списка, а генерирует подсписки по мере необходимости.
from itertools import islice
def split_list(lst, chunk_size):
return list(islice(lst, chunk_size))
Для больших списков или если нужно выполнить множество операций с разбиением, второй вариант может быть более предпочтительным из-за экономии памяти. Важно помнить, что выбор метода зависит от ваших конкретных нужд: нужно ли вам сохранить все данные в памяти или вы готовы обрабатывать их по мере необходимости.
Преобразование списка в массив с использованием list comprehension
List comprehension в Python позволяет элегантно преобразовать одномерный список в двумерный массив, особенно если требуется выполнить дополнительные операции с элементами списка в процессе преобразования.
Основная идея заключается в том, чтобы использовать выражение внутри списка для создания новых подсписков, таким образом создавая двумерную структуру. Рассмотрим пример:
original_list = [1, 2, 3, 4, 5, 6]
array_2d = [[original_list[i], original_list[i+1]] for i in range(0, len(original_list), 2)]
print(array_2d)
В этом примере исходный список делится на подсписки по два элемента. List comprehension позволяет сразу же назначить шаг при итерации, обеспечивая гибкость в обработке данных.
Как можно адаптировать такой подход для других случаев:
- Для создания массива с группами по N элементов используйте
range(0, len(original_list), N). - Если необходимо применить функцию к каждому элементу при создании подсписков, можно сделать это прямо внутри выражения list comprehension.
Пример с применением функции:
array_2d = [[x * 2 for x in original_list[i:i+2]] for i in range(0, len(original_list), 2)]
print(array_2d)
Такой подход позволяет получить более сложные структуры и произвести необходимые вычисления или преобразования данных в процессе их группировки. Благодаря list comprehension код остаётся компактным и читаемым, избегая необходимости в явных циклах и дополнительных проверках.
Использование метода reshape для создания двумерного массива
Чтобы использовать reshape, необходимо сначала создать объект массива. Для этого используется функция np.array(), которая преобразует список в массив. После этого вызывается метод reshape для изменения структуры данных.
Пример использования метода reshape:
import numpy as np data = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12] array = np.array(data) reshaped_array = array.reshape(3, 4) print(reshaped_array)
В этом примере список из 12 элементов преобразуется в массив размером 3 на 4, что означает, что массив будет иметь 3 строки и 4 столбца. Важно, чтобы количество элементов в исходном массиве соответствовало произведению новых размеров. Например, если вы пытаетесь преобразовать массив из 10 элементов в форму 3 на 4, возникнет ошибка, так как количество элементов не совпадает с требуемым.
Метод reshape также позволяет использовать параметр -1 для автоматического вычисления одного из размеров. Например, если нужно преобразовать одномерный массив в двумерный, и один размер неизвестен, можно указать -1:
reshaped_array = array.reshape(3, -1) print(reshaped_array)
В этом случае метод самостоятельно рассчитает количество столбцов, основываясь на количестве элементов в массиве.
Однако стоит помнить, что метод reshape возвращает новый массив, не изменяя оригинальный. Если требуется изменить исходный массив, можно использовать метод resize вместо reshape.
Для корректной работы с методом reshape важно, чтобы размерность массива соответствовала предполагаемым данным, а изменение формы не должно нарушать структуру данных. Этот метод полезен, например, при подготовке данных для машинного обучения, где требуется определённая форма входных данных.
Преобразование вложенных списков в двумерный массив с помощью map()
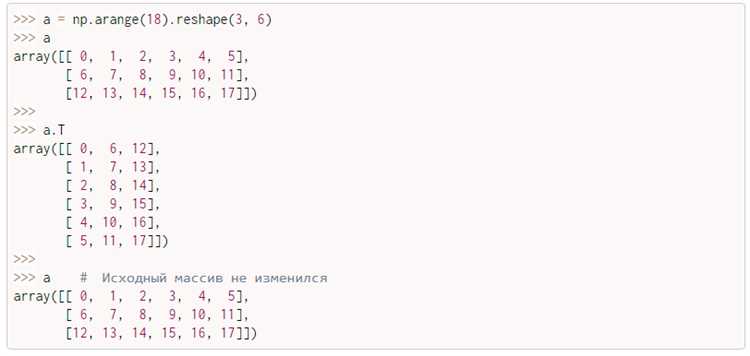
Функция map() в Python используется для применения функции к каждому элементу итерируемого объекта. Когда речь идет о преобразовании вложенных списков в двумерный массив, map() становится удобным инструментом для работы с данными, представленных в виде списка списков. Это позволяет эффективно обрабатывать многомерные данные и преобразовывать их в нужный формат.
Для начала важно понимать, что map() принимает два аргумента: функцию и итерируемый объект. В случае преобразования вложенных списков в двумерный массив, можно использовать map() для применения нужной операции к каждому внутреннему списку. Например, можно пройтись по списку списков и преобразовать его элементы в массивы NumPy для работы с ними в дальнейшем.
Пример использования:
import numpy as np
# Вложенные списки
nested_list = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
# Преобразование с помощью map() и lambda-функции
result = list(map(lambda x: np.array(x), nested_list))
print(result)
В этом примере map() применяется к каждому вложенному списку, преобразуя его в массив NumPy. После этого результат можно использовать для дальнейших операций, таких как математические вычисления или манипуляции с данными.
Важно отметить, что map() возвращает итератор, поэтому для получения окончательного результата необходимо преобразовать его в список (с помощью list()) или в другой подходящий тип данных. Такой подход обеспечивает компактность и эффективность работы с вложенными списками.
Для более сложных преобразований, когда необходимо обработать элементы не только вложенных списков, но и провести дополнительные вычисления, можно передать более сложные функции в map(). Это делает подход гибким и удобным для различных типов данных и задач.
Как правильно работать с неравномерными списками при преобразовании
Основное правило при работе с неравномерными списками – это их нормализация. Чтобы корректно преобразовать неравномерный список в двумерный массив, необходимо сначала привести его к одинаковой длине. Для этого можно использовать несколько методов:
1. Выравнивание списков по максимальной длине
Можно определить максимальную длину вложенных списков и дополнить все более короткие списки пустыми значениями (например, None или 0). Это полезно, когда важно сохранить структуру данных, но необходимо привести их к единому виду. Пример кода:
lists = [[1, 2], [3, 4, 5], [6]]
max_len = max(len(sublist) for sublist in lists)
normalized_lists = [sublist + [None] * (max_len - len(sublist)) for sublist in lists]
2. Обработка отсутствующих значений
Когда в списках встречаются недостающие элементы, можно использовать технику, которая заполняет пустые места заранее определёнными значениями. Важно, чтобы такие данные не искажали смысл исходных данных. Использование None или NaN – хороший способ для обозначения отсутствующих значений, что позволяет сохранить оригинальные данные.
3. Преобразование в «рваные» массивы с сохранением структуры
Если важен каждый элемент данных, и преобразование в традиционный двумерный массив невозможно из-за разной длины вложенных списков, можно использовать «рваные» массивы. В Python можно работать с такими структурами с помощью библиотеки numpy, которая поддерживает работу с массивами нефиксированной длины. Например:
import numpy as np
arr = np.array(lists, dtype=object)
Этот подход позволяет сохранить различие в длине строк, но даёт возможность работать с данными как с массивом, не теряя информации.
4. Адаптация под конкретную задачу
В зависимости от задачи, могут понадобиться разные подходы к обработке неравномерных списков. Если необходимо выполнить операции над двумерными массивами, и важна согласованность размеров, можно заранее провести анализ данных и в случае необходимости отфильтровать или изменить определённые элементы. В других случаях стоит использовать динамическую работу с вложенными списками, где длина подстраивается под каждую задачу.
Преобразование неравномерных списков в двумерные массивы требует внимательности к деталям. Учитывая эти рекомендации, можно избежать ошибок и корректно обрабатывать данные любой сложности.
Обработка ошибок при преобразовании списка в двумерный массив
При преобразовании одномерного списка в двумерный массив в Python важно учитывать различные виды ошибок, которые могут возникнуть в процессе. Ошибки могут быть связаны как с самими данными, так и с ошибками логики преобразования. Рассмотрим несколько распространенных ситуаций и способы их обработки.
Неверная длина подсписков
При попытке преобразовать список в двумерный массив необходимо удостовериться, что все подсписки имеют одинаковую длину. Если длина подсписков варьируется, это может привести к несоответствию данных. В таких случаях следует либо нормализовать данные (добавляя или удаляя элементы), либо генерировать исключение, если данные не могут быть приведены к нужному виду.
list_data = [1, 2, 3, 4, 5, 6]
rows = 2
cols = 3
if len(list_data) != rows * cols:
raise ValueError("Невозможно преобразовать список в двумерный массив с заданными размерами")
matrix = [list_data[i:i + cols] for i in range(0, len(list_data), cols)]
Некорректные данные
Если данные содержат значения, которые не могут быть интерпретированы как элементы массива, необходимо их отфильтровывать или предварительно проверять. Например, если предполагается, что список содержит только числа, а в нем есть строки или другие типы данных, это вызовет ошибку. Для предотвращения подобных ситуаций можно использовать конструкцию try-except.
try:
list_data = [1, 2, 'a', 4]
matrix = [int(i) for i in list_data]
except ValueError as e:
print("Ошибка преобразования данных:", e)
Неверные размеры массива
Если количество строк или столбцов задано неправильно, преобразование может не быть выполнено корректно. Важно убедиться, что размеры массива соответствуют требованиям. Это можно проверить с помощью условных операторов до выполнения преобразования, чтобы избежать ошибок во время выполнения программы.
def create_2d_array(list_data, rows, cols):
if len(list_data) != rows * cols:
raise ValueError("Количество элементов в списке не совпадает с размерами массива")
return [list_data[i:i + cols] for i in range(0, len(list_data), cols)]
matrix = create_2d_array([1, 2, 3, 4, 5, 6], 2, 3)
Обработка пустого списка
Пустой список может вызвать проблемы при преобразовании в двумерный массив, особенно если предполагается наличие хотя бы одного элемента. Для предотвращения таких ситуаций следует предусмотреть обработку пустых списков. Например, можно возвращать пустой двумерный массив или генерировать исключение, если список пуст.
list_data = []
if not list_data:
matrix = []
else:
matrix = [list_data[i:i + 3] for i in range(0, len(list_data), 3)]
Невозможно преобразовать многомерный список
Если список содержит вложенные структуры данных (например, списки внутри списков), которые необходимо преобразовать в двумерный массив, важно убедиться, что структура данных однородна. Для решения этой проблемы можно проверить каждый элемент списка и убедиться, что он сам является списком перед выполнением преобразования.
def is_valid_matrix_structure(list_data):
return all(isinstance(i, list) for i in list_data)
list_data = [[1, 2], [3, 4]]
if not is_valid_matrix_structure(list_data):
raise TypeError("Список не является допустимым двумерным массивом")
Вопрос-ответ:
Как преобразовать список в двумерный массив в Python?
Для преобразования одномерного списка в двумерный массив в Python можно использовать различные способы. Например, можно воспользоваться библиотеками NumPy или стандартными методами Python. В первом случае с использованием NumPy достаточно применить функцию reshape(), а во втором – можно использовать циклы для группировки элементов в подсписки.
Можно ли преобразовать список в двумерный массив без использования сторонних библиотек?
Да, для этого можно использовать стандартные возможности Python. Один из способов — это пройтись по списку с помощью циклов и вручную собрать его в двумерный массив. Например, можно разделить исходный список на части фиксированной длины с помощью срезов.
Что делать, если количество элементов в списке не делится нацело на количество строк или столбцов?
Если количество элементов в списке не делится нацело на количество строк или столбцов, то возникает проблема с равномерным распределением элементов. В таком случае можно либо дополнить список недостающими значениями, либо использовать подход, при котором оставшиеся элементы будут распределяться по массиву так, как это возможно. Например, можно использовать методы, которые заполнят недостающие ячейки значениями по умолчанию, например, None или 0.