При работе с Python сравнение списков – это одна из самых часто используемых операций, особенно в случае обработки данных или реализации алгоритмов. Основной задачей является точное определение, являются ли два списка идентичными, и если нет, в чём именно заключается разница. Существует несколько методов сравнения, каждый из которых подходит для разных типов задач.
Для простого сравнения списков можно использовать оператор ==, который проверяет, равны ли два списка по элементам и их порядку. Важно помнить, что порядок элементов имеет значение: два списка с одинаковыми элементами, но в разном порядке, будут считаться разными. Для нахождения различий между списками можно использовать методы set() и difference(), но это решение исключает повторяющиеся элементы, что не всегда подходит для задач, где важен точный состав списков.
Если необходима более детальная проверка, например, для нахождения индекса первого различия, можно использовать цикл и метод zip(). Такой подход позволяет точнее определить, на каком именно элементе списки перестают быть одинаковыми. В случае работы с большими списками важно учитывать время выполнения алгоритмов. Например, использование set() может быть значительно быстрее, чем перебор элементов с помощью zip(), но это зависит от конкретной задачи и особенностей данных.
Для оптимизации работы с большими наборами данных и сложными структурами списков полезно комбинировать методы сравнения, например, сочетать проверку на идентичность через == с дополнительной проверкой различий с использованием collections.Counter(). Этот метод полезен в случае, когда порядок элементов не имеет значения, но важно учитывать количество повторений каждого элемента.
Сравнение списков на идентичность с помощью оператора ==
Оператор == в Python используется для сравнения списков на идентичность по значениям их элементов. Это означает, что два списка считаются равными, если у них одинаковые элементы в одинаковом порядке.
Пример:
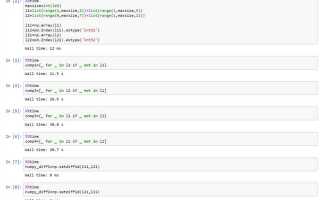
list1 = [1, 2, 3]
list2 = [1, 2, 3]
print(list1 == list2) # Выведет: TrueВ приведенном примере списки list1 и list2 имеют одинаковые элементы, поэтому сравнение с помощью == возвращает True.
Особенности оператора ==:
1. Порядок элементов имеет значение. Даже если списки содержат одинаковые элементы, но в разном порядке, они будут считаться неравными:
list1 = [1, 2, 3]
list2 = [3, 2, 1]
print(list1 == list2) # Выведет: False2. Типы элементов важны. Списки, содержащие элементы разных типов, не будут равны, даже если их значения совпадают по внешнему виду:
list1 = [1, "2", 3]
list2 = [1, 2, 3]
print(list1 == list2) # Выведет: False3. Равенство вложенных списков. Если список содержит другие списки, то сравниваются не только их ссылки, но и элементы внутри них:
list1 = [[1, 2], [3, 4]]
list2 = [[1, 2], [3, 4]]
print(list1 == list2) # Выведет: TrueОператор == не проверяет, ссылаются ли два списка на один и тот же объект в памяти. Он только сравнивает их содержимое, что делает его удобным для проверки равенства данных.
Рекомендации:
— Если важен порядок элементов, оператор == подходит для сравнения.
— Если вам нужно сравнивать только содержимое, а не порядок, стоит использовать дополнительные методы, такие как сортировка списка перед сравнением.
Использование set() для сравнения без учета порядка
Функция set() в Python позволяет преобразовать список в множество, автоматически исключая дубликаты и игнорируя порядок элементов. Это удобно для сравнения двух списков, когда важно только их содержание, а порядок не имеет значения.
Чтобы сравнить два списка с помощью set(), выполните следующие шаги:
- Преобразуйте оба списка в множества с помощью
set(). - Сравните полученные множества с помощью оператора
==.
Пример:
list1 = [1, 2, 3, 4]
list2 = [4, 3, 2, 1]
if set(list1) == set(list2):
print("Списки равны.")
else:
print("Списки не равны.")
В этом примере два списка считаются одинаковыми, несмотря на разный порядок элементов. Множества автоматически устраняют дубли, так что для точного сравнения повторяющиеся элементы в списках не имеют значения.
Важно помнить, что множеств нет порядка, и они не сохраняют последовательность добавления элементов. Если порядок элементов важен, это решение не подойдет.
Преимущества использования set() для сравнения:
- Быстрое сравнение больших списков.
- Учитывает только уникальные элементы в списках.
- Не зависит от порядка элементов.
Если вам нужно выполнить сравнение, которое игнорирует порядок, но сохраняет важность дубликатов, используйте collections.Counter.
Проверка одинаковости элементов списков с разными типами данных
При сравнении двух списков в Python важно учитывать, что элементы в них могут быть разных типов: строки, числа, списки, объекты. Если типы данных отличаются, стандартные операторы сравнения (например, ==) могут дать неожиданные результаты. Например, строка и число с одинаковым значением не считаются одинаковыми. Важно знать, как правильно проверять такие случаи.
Для проверки одинаковости элементов списков с разными типами данных стоит использовать более детальный подход. Простейший способ – это использование функции zip(), которая позволяет одновременно обрабатывать элементы двух списков. С помощью zip() можно пройти по каждому элементу списков и провести сравнение с учетом типов данных.
Для более точной проверки может потребоваться преобразование типов элементов. Например, если элементы списков предполагается сравнивать как строки, можно использовать функцию str() для явного приведения чисел и других типов данных к строковому виду. Однако стоит помнить, что при этом могут возникать ошибки при несовместимости типов, например, при попытке преобразовать объект в строку.
Пример сравнения списков с разными типами данных:
list1 = [1, "apple", 3.14] list2 = ["1", "apple", 3.14] # Преобразуем элементы в строковый тип и сравниваем result = all(str(a) == str(b) for a, b in zip(list1, list2))
В данном примере элементы списков сравниваются после приведения всех элементов к строковому типу. Такой подход может быть полезен, когда нужно игнорировать различия в представлениях данных (например, «1» и 1).
Важно: При сравнении элементов с разными типами данных следует быть внимательным к логике приложения. Например, если в списках содержатся числа с плавающей запятой, их прямое сравнение может вызвать ошибки из-за особенностей представления этих чисел в памяти. В таких случаях полезно использовать методы округления или допустимые погрешности для проверки одинаковости.
Если требуется строгое сравнение типов данных, то можно воспользоваться встроенной функцией type(). Это обеспечит точное соответствие типов и исключит ошибки, связанные с преобразованием данных.
result = all(type(a) == type(b) for a, b in zip(list1, list2))
Таким образом, при сравнении списков с разными типами данных важно учитывать контекст и цели проверки. Приведение типов может быть полезным в ряде случаев, однако для точного сравнения типов лучше использовать функцию type() или другие специализированные методы обработки данных.
Как найти элементы, которые есть только в одном из списков

Для поиска элементов, которые присутствуют только в одном из двух списков, можно использовать операторы множества в Python. Это решение работает быстро и эффективно благодаря особенностям структуры данных «множество». Основная идея – исключить элементы, которые встречаются в обоих списках, и оставить только те, что уникальны для каждого списка.
Пример: у нас есть два списка, list1 и list2, и нам нужно найти элементы, которые есть только в одном из этих списков, но не в обоих сразу.
Для этого можно воспользоваться операцией симметрической разности. Симметрическая разность возвращает все элементы, которые присутствуют либо в первом, либо во втором списке, но не в обоих. В Python эта операция выполняется с помощью метода ^ или функции symmetric_difference().
Пример кода:
list1 = [1, 2, 3, 4, 5]
list2 = [4, 5, 6, 7, 8]
set1 = set(list1)
set2 = set(list2)
# Симметрическая разность
result = set1 ^ set2
print(result)
Результат: {1, 2, 3, 6, 7, 8}. Эти элементы есть только в одном из двух списков.
Альтернативно, можно использовать метод symmetric_difference():
result = set1.symmetric_difference(set2)
print(result)
Этот подход гарантирует, что будут возвращены только те элементы, которые не имеют дубликатов в обоих списках. Также важно помнить, что порядок элементов в множестве не сохраняется, так как множества в Python неупорядочены.
Поиск пересечений между двумя списками
Пример кода:
list1 = [1, 2, 3, 4, 5]
list2 = [4, 5, 6, 7, 8]
intersection = list(set(list1) & set(list2))
print(intersection)В этом примере создаются множества из обоих списков, а затем выполняется пересечение с помощью оператора «&». Результатом будет новый список, содержащий элементы, которые есть в обоих исходных списках.
Если порядок элементов в пересечении важен, можно использовать цикл для фильтрации элементов из первого списка, которые присутствуют во втором:
intersection = [item for item in list1 if item in list2]
print(intersection)Этот способ сохраняет порядок элементов, но может быть менее эффективным, так как для каждого элемента из первого списка выполняется поиск во втором списке.
Если необходимо выполнить операцию с большими объемами данных, стоит обратить внимание на производительность. Преобразование списков в множества и использование операций с множествами обычно быстрее, особенно когда элементы уникальны.
Для поиска пересечений в более сложных структурах данных (например, списках словарей) можно воспользоваться методами фильтрации с условием. Это может потребовать дополнительных шагов, таких как создание вспомогательных списков или применение функций, ориентированных на сравнение по определенным ключам.
Сравнение списков на основе их длинны и элементов
Для сравнения двух списков в Python на основе их длины и элементов можно использовать различные подходы, в зависимости от требований задачи.
Сравнение длинны списков часто используется для проверки, содержат ли списки одинаковое количество элементов. Это можно легко сделать с помощью функции len(), которая возвращает количество элементов в списке.
Пример кода для сравнения длин:
list1 = [1, 2, 3]
list2 = [4, 5, 6]
if len(list1) == len(list2):
print("Списки одинаковой длины")
else:
print("Списки различной длины")
Этот способ работает, если важно, чтобы списки были одинаковой длины, и не учитывает порядок элементов или их значения.
Сравнение элементов списков более сложное, так как помимо длины важно учитывать порядок и значение каждого элемента. Для этого можно использовать оператор равенства ==, который проверяет, содержат ли списки одинаковые элементы в том же порядке.
Пример сравнения списков по элементам:
list1 = [1, 2, 3]
list2 = [1, 2, 3]
if list1 == list2:
print("Списки идентичны")
else:
print("Списки различаются")
Если требуется сравнить списки без учета порядка элементов, можно использовать sorted() для сортировки обоих списков перед сравнением:
list1 = [1, 2, 3]
list2 = [3, 2, 1]
if sorted(list1) == sorted(list2):
print("Списки содержат одинаковые элементы, независимо от порядка")
else:
print("Списки содержат разные элементы")
Важным аспектом является то, что при таком подходе sorted() изменяет порядок элементов, что может повлиять на производительность при работе с большими списками.
Если порядок элементов не важен и элементы могут повторяться, но должны встречаться одинаковое количество раз, используйте коллекцию Counter из модуля collections.
Пример с использованием Counter:
from collections import Counter
list1 = [1, 2, 3, 3]
list2 = [3, 2, 1, 3]
if Counter(list1) == Counter(list2):
print("Списки содержат одинаковые элементы с одинаковой частотой")
else:
print("Списки различаются по элементам или их частоте")
Этот метод эффективен, когда важна не только длина, но и частота каждого элемента в списке.
Как учесть дубликаты при сравнении списков
При сравнении списков в Python важно учитывать, что дубликаты могут влиять на результаты. Стандартные операторы сравнения, такие как ==, проверяют на одинаковые элементы в одинаковом порядке, но не учитывают количество повторений. Если необходимо сравнить списки с учётом дубликатов, потребуется использовать другие подходы.
Один из способов – это использование модулей collections и Counter. Этот подход помогает точно определить, сколько раз каждый элемент встречается в списках, и позволяет учесть дубликаты при сравнении.
Пример использования Counter:
from collections import Counter
list1 = [1, 2, 2, 3]
list2 = [2, 1, 3, 2]
if Counter(list1) == Counter(list2):
print("Списки идентичны с учётом дубликатов.")
else:
print("Списки различаются.")
Counter подсчитывает количество каждого элемента и создает словарь, где ключ – это элемент списка, а значение – количество его вхождений. Сравнив два таких объекта, можно узнать, совпадают ли списки, учитывая дубликаты.
Если необходимо учитывать порядок элементов, то можно дополнительно использовать сортировку:
if sorted(list1) == sorted(list2):
print("Списки идентичны, включая порядок элементов.")
else:
print("Списки различаются по порядку элементов.")
Также стоит учитывать, что при сравнении списков с дубликатами порядок элементов может быть важен в зависимости от задачи. Например, при сравнении двух списков идентичных элементов в разных порядках, их можно считать различными или одинаковыми, в зависимости от контекста.
Для задач, где важен порядок элементов, используйте метод sorted() или прямое сравнение с учётом индексов. В случае, если порядок не важен, используйте Counter или другие способы подсчёта элементов для точного сравнения списков.
Определение различий между списками с помощью библиотеки difflib
Для того чтобы использовать difflib для сравнения списков, необходимо сначала импортировать библиотеку и подготовить данные для анализа. Пример кода:
import difflib
list1 = ["яблоко", "банан", "вишня"]
list2 = ["яблоко", "груша", "вишня"]
diff = difflib.ndiff(list1, list2)
print("\n".join(diff))Результат сравнения будет выглядеть следующим образом:
яблоко
- банан
+ груша
вишняЗдесь символы - и + обозначают, какие элементы присутствуют в одном списке, но отсутствуют в другом. Элементы без символов означают, что они совпадают в обеих коллекциях.
Важные моменты при работе с difflib.ndiff:
- Результат возвращает генератор, который можно пройти с помощью цикла или преобразовать в список.
diff = difflib.unified_diff(list1, list2, lineterm="")
print("\n".join(diff))---
+++
@@ -1,3 +1,3 @@
яблоко
- банан
+ груша
вишняДля более сложных сценариев можно использовать другие методы из библиотеки, такие как get_close_matches для нахождения схожих элементов в списках, что полезно, если списки могут содержать незначительные ошибки в написании.
Вопрос-ответ:
Как правильно сравнить два списка в Python?
Для того чтобы сравнить два списка в Python, можно использовать операторы сравнения. Например, оператор `==` проверяет, равны ли два списка по элементам и их порядку. Если элементы и их порядок совпадают, результатом будет `True`. Если хотя бы один элемент отличается, результат будет `False`. Также можно использовать функции, такие как `all()` и `zip()`, для более сложных сравнений.
Что будет, если списки в Python имеют разную длину при сравнении?
Если два списка имеют разную длину, то при сравнении с помощью оператора `==` результат будет всегда `False`, так как Python проверяет не только элементы, но и их количество. Даже если все элементы совпадают, но длина списков различна, сравнение вернёт ложное значение.
Можно ли сравнивать списки с разными типами данных в Python?
Списки с разными типами данных можно сравнивать, но результат будет зависеть от типа данных. Например, если один список содержит целые числа, а другой — строки, то результат сравнения с помощью `==` будет `False`, так как Python не считает такие типы эквивалентными. Важно учитывать, что разные типы данных всегда будут считаться неравными, даже если их значения могут быть математически схожими (например, строка ’10’ и число 10).
Какие методы позволяют сравнить два списка на наличие одинаковых элементов, независимо от их порядка?
Для того чтобы сравнить два списка на наличие одинаковых элементов без учёта их порядка, можно использовать множества. Преобразовав списки в множества с помощью `set()`, можно выполнить сравнение с помощью оператора `==`. Множества не сохраняют порядок элементов, и поэтому при сравнении будет учитываться только наличие одинаковых элементов. Однако при этом все дубликаты будут удалены, и порядок элементов будет игнорироваться.