Работа с JSON-форматом в Python – это неотъемлемая часть взаимодействия с веб-API и сериализацией данных. Однако часто возникает необходимость сохранить данные в читаемом виде, с отступами и форматированием, чтобы упростить дальнейший анализ или отладку. В Python для этого используется встроенный модуль json, который предоставляет гибкие возможности для работы с форматом JSON, включая сохранение данных с красивым форматированием.
Основной функцией, которая поможет сохранить JSON в отформатированном виде, является json.dump(). Чтобы задать нужный уровень отступов, можно использовать параметр indent, который позволяет легко настроить форматирование. Чем больше значение этого параметра, тем больше пробелов будет использовано для отступов, что делает файл более читаемым.
Пример использования функции для записи отформатированного JSON в файл:
import json
data = {"name": "John", "age": 30, "city": "New York"}
with open("output.json", "w") as outfile:
json.dump(data, outfile, indent=4)
Этот код создаст файл output.json с данными, отформатированными с четырьмя пробелами для отступа. Если необходимо сохранить данные с отступами и при этом соблюсти стиль однотипных кавычек или избежать сортировки ключей, можно использовать параметры separators и sort_keys.
Кроме того, важно помнить, что форматированный JSON не всегда подходит для всех случаев, особенно когда речь идет о больших объемах данных. При сохранении данных на диск можно столкнуться с увеличением объема файлов из-за пробелов и новых строк. Поэтому в зависимости от задачи, важно выбрать оптимальный подход к сериализации и сохранению данных.
Сохранение JSON с отступами с помощью json.dump()

Для сохранения объекта Python в формате JSON с отступами используется функция json.dump(). Этот метод позволяет не только сериализовать данные, но и добавить отступы для улучшения читаемости файла. Основной параметр для настройки отступов – indent, который задает количество пробелов для отступа на каждом уровне вложенности.
Пример использования функции json.dump() с параметром indent:
import json
data = {
"name": "John",
"age": 30,
"city": "New York",
"children": [
{"name": "Alice", "age": 10},
{"name": "Bob", "age": 8}
]
}
with open('data.json', 'w') as file:
json.dump(data, file, indent=4)
В данном примере мы сохраняем словарь data в файл data.json, используя отступы в 4 пробела для каждого уровня вложенности. Это делает файл более читаемым для человека, так как каждый уровень структуры данных будет наглядно отделен пробелами.
Также можно использовать параметр separators для настройки разделителей между элементами JSON-объекта. Например, можно уменьшить размер файла, изменив разделитель между элементами:
json.dump(data, file, indent=4, separators=(',', ': '))
По умолчанию json.dump() использует запятую и пробел для разделения элементов, но можно настроить их по своему усмотрению, что может быть полезно в случаях с большими объемами данных.
При использовании indent важно учитывать, что форматирование влияет только на текстовое представление данных в файле, но не на сами данные. Этот параметр удобен для разработки, отладки или обработки конфигурационных файлов, где важна читаемость.
Использование параметра indent для улучшения читаемости файла
В Python модуль json предоставляет параметр indent, который позволяет форматировать JSON-данные с отступами. Этот параметр значительно улучшает читаемость данных в файле, особенно когда нужно работать с большими структурами данных.
По умолчанию, если не указать параметр indent, Python запишет JSON в компактном виде, без пробелов или переносов строк, что затрудняет его восприятие. Использование indent помогает легко визуально отделить элементы данных и создать структуру, удобную для анализа человеком.
Пример использования параметра indent при записи данных:
import json
data = {"name": "Alice", "age": 30, "city": "Moscow"}
with open('data.json', 'w') as file:
json.dump(data, file, indent=4)
В этом примере JSON будет записан с отступами по 4 пробела для каждого уровня вложенности, что улучшит его восприятие.
Некоторые рекомендации по использованию indent:
- Выбор количества пробелов: Обычно для отступов выбирают 2 или 4 пробела. Это зависит от предпочтений команды или стандарта кодирования, но важно придерживаться единого формата в проекте.
- Чтение и редактирование: Использование
indentделает JSON читаемым не только для автоматических парсеров, но и для разработчиков, которые могут вручную редактировать данные. Это особенно важно для конфигурационных файлов или документации. - Производительность: Форматирование с отступами увеличивает размер файла и может немного замедлить процесс записи, особенно для больших данных. Но для большинства случаев это не имеет существенного влияния.
- Пространство и линейки: Если структура данных слишком глубокая, стоит использовать больше пробелов для повышения читаемости, но это также может увеличить длину строк в файле. Следует соблюдать баланс, чтобы избежать слишком длинных строк.
Использование indent помогает сделать данные более доступными для людей, что особенно важно при совместной разработке или анализе информации в текстовом виде. Применяйте этот параметр для повышения прозрачности и удобства работы с файлами JSON.
Как сохранить JSON в файл с сортировкой ключей

Чтобы сохранить данные с отсортированными ключами, необходимо передать параметр sort_keys=True в функцию json.dump() или json.dumps(). Рассмотрим пример кода:
import json
data = {
"b": 2,
"a": 1,
"c": 3
}
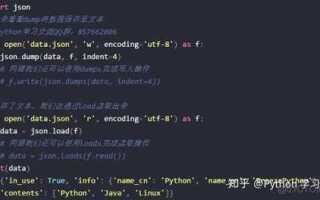
with open('data.json', 'w') as f:
json.dump(data, f, sort_keys=True, indent=4)В этом примере ключи словаря «a», «b» и «c» будут отсортированы в алфавитном порядке при записи в файл. Параметр indent позволяет задать количество пробелов для отступов, улучшая визуальное восприятие JSON-файла.
Важно отметить, что сортировка происходит только по ключам первого уровня. Если словарь содержит вложенные структуры, их ключи будут отсортированы отдельно для каждого уровня. Это делает данные более организованными и удобными для анализа.
Кроме того, в случае необходимости сериализации сложных данных (например, пользовательских объектов), важно следить за тем, чтобы все объекты в JSON были правильно преобразованы в соответствующие типы перед сохранением. Это можно реализовать через параметр default, который позволяет указать функцию для сериализации нестандартных объектов.
Работа с кодировками при сохранении JSON в Python

При сохранении JSON-данных в Python важно учитывать кодировку, чтобы гарантировать правильное представление символов, особенно для не-ASCII символов, таких как кириллица. Для этого необходимо указать кодировку при записи в файл, иначе может возникнуть ошибка или некорректное сохранение данных.
По умолчанию, модуль json использует кодировку UTF-8 при записи данных в файл. Однако, если работа ведется с другими кодировками или требуется специфическая настройка, стоит указать кодировку явно.
- Для записи JSON с использованием UTF-8 можно использовать следующий код:
import json
data = {"ключ": "значение"}
with open('data.json', 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False)
Опция ensure_ascii=False гарантирует, что символы, не входящие в стандартный ASCII, будут записаны в файле в оригинальной форме (например, кириллица).
- Если необходимо использовать другую кодировку, например,
windows-1251, можно указать это при открытии файла:
with open('data.json', 'w', encoding='windows-1251') as f:
json.dump(data, f, ensure_ascii=False)
Для работы с кодировками важно помнить несколько моментов:
- Между платформами. На разных операционных системах поведение кодировок может отличаться. Особенно это важно при обмене файлами между Windows и Linux.
- Чтение с ошибками. Если файл с JSON был записан в неправильной кодировке, при чтении может возникнуть ошибка. Чтобы избежать этого, всегда проверяйте кодировку при открытии файлов для чтения и записи.
- Преобразование кодировок. В случае, если данные сохранены в одной кодировке, а при чтении требуется другая, можно воспользоваться библиотекой
chardetдля автоматического определения кодировки и ее преобразования.
Особое внимание стоит уделить кодировкам при работе с международными данными или при использовании нестандартных символов в JSON. В этих случаях всегда лучше заранее определить кодировку, чтобы избежать проблем с потерей данных или появлением ошибок при записи и чтении файлов.
Сохранение JSON в строку с форматированием для дальнейшей обработки
При работе с JSON в Python часто возникает необходимость преобразования данных в строковый формат, который будет удобно передавать или сохранять, сохраняя при этом читаемость и структуру. Для этого можно использовать метод `json.dumps()`, который позволяет настраивать форматирование при конвертации Python-объектов в строку JSON.
Для сохранения JSON в строку с форматированием нужно использовать параметр `indent`. Он указывает количество пробелов, которые будут добавлены для отступов на каждом уровне вложенности. Это позволяет улучшить читаемость данных, что особенно важно при анализе или дебаггинге больших структур данных. Например:
import json
data = {"name": "John", "age": 30, "city": "New York"}
formatted_json = json.dumps(data, indent=4)
print(formatted_json)
В результате будет выведена строка, где каждый уровень вложенности данных будет отступать на 4 пробела. Для настройки количества пробелов можно передать любое целое число в параметр `indent`. Если требуется более компактное представление, можно установить значение `indent=2`, или даже `indent=1`.
Если необходима дальнейшая обработка JSON-строки, важно учитывать параметры, которые влияют на сохранение структуры данных. Например, параметр `separators` позволяет контролировать разделители между элементами JSON. Использование `separators=(‘,’, ‘: ‘)` помогает уменьшить размер строки за счет удаления лишних пробелов:
formatted_json = json.dumps(data, indent=4, separators=(',', ': '))
print(formatted_json)
Также для того, чтобы избежать использования кавычек вокруг строковых ключей в JSON, можно использовать параметр `ensure_ascii=False`, что полезно для работы с данными на разных языках, включая русский. Этот параметр предотвращает преобразование символов в экранированные последовательности:
formatted_json = json.dumps(data, indent=4, ensure_ascii=False) print(formatted_json)
Когда данные в строке JSON могут быть переданы или сохранены, важно выбрать подходящие параметры форматирования в зависимости от требуемых условий. Например, для работы с большими данными в целях аналитики или логирования часто предпочтительнее использовать минимизированный формат, а для обмена данными с людьми – более читаемое представление с отступами.
Как избежать потери данных при сохранении JSON в Python
При сохранении данных в формате JSON важно учитывать несколько аспектов, чтобы избежать потери информации. Первый момент связан с типами данных. JSON поддерживает ограниченный набор типов: строки, числа, массивы, объекты и булевы значения. Если в вашем Python-объекте присутствуют типы данных, которых нет в JSON (например, объекты с методами или файлы), они могут быть потеряны при преобразовании в JSON.
Для того чтобы избежать потери данных, важно предварительно обработать такие элементы, например, используя кастомные сериализаторы. В Python для этого можно определить собственные функции сериализации с помощью аргумента default в функции json.dump() или json.dumps(). Пример:
import json
def custom_serializer(obj):
if isinstance(obj, YourCustomClass):
return obj.to_dict() # преобразуем объект в словарь
raise TypeError("Type not serializable")
data = YourCustomClass()
with open('data.json', 'w') as f:
json.dump(data, f, default=custom_serializer)
Еще один важный момент – это точность чисел. JSON имеет ограничения по точности представления чисел с плавающей запятой, что может привести к потере точности при сохранении больших или очень точных значений. Чтобы избежать этого, можно использовать параметр ensure_ascii в функции json.dump(), а также ограничивать количество знаков после запятой для чисел с плавающей запятой.
Также стоит учесть возможные проблемы с кодировками. По умолчанию json.dump() сохраняет строки в UTF-8, что может быть проблемой при работе с нестандартными символами. Чтобы избежать ошибок при чтении и записи, убедитесь, что ваши данные и файлы используют одну и ту же кодировку.
Если структура данных сложная (например, вложенные списки или объекты), важно учитывать, что глубокое копирование объектов перед их сериализацией может предотвратить случайную модификацию данных в процессе сохранения. Используйте copy.deepcopy() для копирования объектов, когда требуется сохранить исходную структуру данных.
Наконец, при работе с большими объемами данных стоит быть осторожным с памятью. Для сохранения больших JSON-файлов без потери данных полезно использовать методы потоковой записи, такие как json.dump() с открытием файла в режиме записи, а не преобразование всего объекта в строку сразу через json.dumps().