Одним из самых распространённых форматов данных для обмена информацией между системами и хранения табличных данных является CSV. В Python работа с такими файлами значительно упрощается с использованием библиотеки pandas, которая предоставляет удобные методы для чтения, обработки и анализа данных. Загрузка CSV-файла в pandas – это первый шаг к эффективной работе с данными, и в этой статье мы подробно разберем, как это сделать.
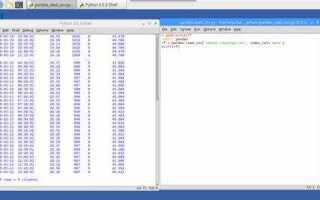
Для загрузки CSV в pandas используется функция read_csv, которая принимает путь к файлу или URL. Если файл находится на локальном диске, достаточно указать путь, если файл размещён в интернете, можно передать ссылку. Важно учитывать, что pandas автоматически обрабатывает большинство вариантов разделителей (запятые, табуляции и другие), но бывают случаи, когда необходимо явно указать разделитель через параметр sep.
Кроме того, стоит помнить, что при работе с большими данными могут возникнуть проблемы с памятью. В таких случаях полезно использовать дополнительные параметры, например, chunksize, который позволяет загружать файл частями, или dtypes, чтобы заранее указать типы данных для столбцов и избежать лишней нагрузки на память.
Установка pandas и подготовка среды для работы с CSV файлами
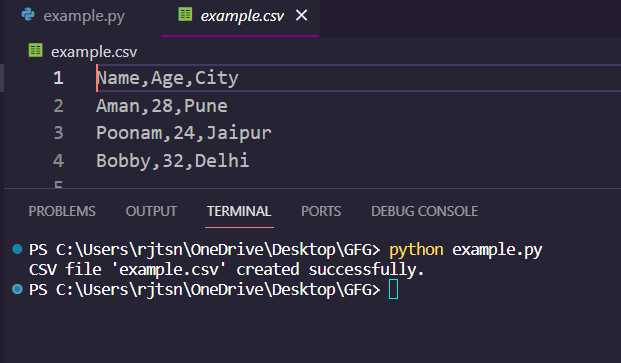
Для начала работы с файлами CSV в Python необходимо установить библиотеку pandas, которая предоставляет удобные функции для работы с табличными данными. Убедитесь, что на вашем компьютере установлен Python версии 3.6 или выше, так как pandas работает только с этими версиями.
Установка pandas выполняется с помощью пакетного менеджера pip. Для этого откройте терминал и выполните следующую команду:
pip install pandasЕсли вы работаете в виртуальной среде, активируйте её перед установкой. Для создания виртуальной среды используйте команду:
python -m venv myenvЗатем активируйте её:
- Для Windows:
myenv\Scripts\activate - Для MacOS/Linux:
source myenv/bin/activate
После установки pandas вам потребуется также установить библиотеку openpyxl, если вы хотите работать с файлами в формате Excel. Для этого выполните команду:
pip install openpyxlТеперь можно переходить к подготовке среды для работы с CSV файлами. Прежде чем загружать файл, убедитесь, что его структура соответствует стандарту CSV (например, разделитель – запятая, строка с заголовками). Для работы с CSV файлами в pandas используйте функцию read_csv(), которая позволяет легко загружать данные в DataFrame.
Рекомендуется также установить дополнительные пакеты для работы с кодировками, например, chardet, если предполагается работа с файлами с нестандартной кодировкой. Это поможет избежать ошибок при чтении данных, особенно если файл содержит символы на разных языках.
Теперь ваша среда готова для работы с CSV файлами в Python с помощью pandas. Следующий шаг – это загрузка и анализ данных, что будет рассмотрено в следующем разделе.
Чтение CSV файла с помощью функции read_csv

Пример использования функции:
import pandas as pd
data = pd.read_csv('путь_к_файлу.csv')Основной параметр filepath_or_buffer указывает на путь к файлу или объект, который поддерживает чтение (например, строка URL или файловый объект). Функция автоматически определяет разделитель, но в случае необходимости его можно указать вручную.
Рассмотрим основные параметры read_csv(), которые часто используются при загрузке данных:
sep: Определяет символ, разделяющий значения в строках файла. По умолчанию используется запятая (`,`), но можно задать любой другой символ, например, табуляцию (\t).header: Указывает, какая строка файла содержит заголовки. Если строка заголовка отсутствует, передайтеheader=None.index_col: Указывает, какой столбец использовать в качестве индекса DataFrame. Можно указать номер столбца или его имя.usecols: Позволяет выбрать только определённые столбцы для загрузки. Принимает список с именами или индексами столбцов.dtype: С помощью этого параметра можно задать тип данных для столбцов. Это полезно, если pandas неверно определяет тип данных при чтении.skiprows: Пропускает заданное количество строк в начале файла или строки с указанными номерами.encoding: Указывает кодировку файла. Это важно для правильного чтения данных, особенно если файл содержит символы на других языках (например, UTF-8).
Пример загрузки файла с настройками параметров:
data = pd.read_csv('путь_к_файлу.csv', sep=';', header=0, usecols=['name', 'age'], dtype={'age': int})Загрузка данных с этим кодом указывает, что данные разделены точкой с запятой, заголовки находятся в первой строке, нужно выбрать только столбцы name и age, а для столбца age задать тип данных int.
Функция read_csv() поддерживает работу с файлами, находящимися в интернете, что упрощает загрузку данных с удалённых источников. Для этого достаточно указать URL вместо локального пути к файлу:
data = pd.read_csv('https://example.com/data.csv')Для более эффективной работы с большими файлами стоит использовать параметры, такие как chunksize, который позволяет загружать данные порциями. Это полезно, если файл слишком большой для загрузки в память целиком:
chunk_size = 10000
for chunk in pd.read_csv('путь_к_файлу.csv', chunksize=chunk_size):
process(chunk)Загрузка CSV файлов с помощью read_csv() – это не только просто и быстро, но и мощно благодаря множеству настраиваемых параметров. Они позволяют эффективно обрабатывать файлы различного формата, размера и структуры, что делает pandas незаменимым инструментом при работе с данными.
Как указать путь к файлу и настроить разделитель данных
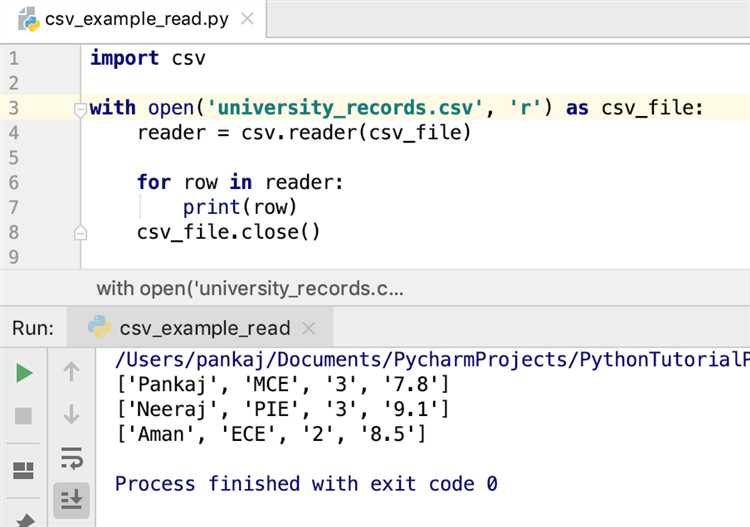
При загрузке CSV-файлов с помощью библиотеки pandas важно правильно указать путь к файлу и настроить разделитель, чтобы корректно прочитать данные. Эти два аспекта играют ключевую роль в процессе импорта.
Указание пути к файлу зависит от того, где находится файл относительно вашего скрипта. Если файл находится в той же директории, что и скрипт, достаточно указать его имя. Пример:
df = pd.read_csv('data.csv')
Если файл расположен в другом месте, укажите полный путь. Например:
df = pd.read_csv('C:/путь/к/файлу/data.csv')
На Linux или macOS путь будет иметь вид:
df = pd.read_csv('/home/user/путь/к/файлу/data.csv')
Если путь содержит пробелы, его можно заключить в кавычки. В случае с относительными путями важно, чтобы текущая рабочая директория была настроена правильно.
Настройка разделителя данных необходима, если данные в файле разделены не стандартным символом запятой. В этом случае используйте параметр sep. Например, для разделителя табуляции:
df = pd.read_csv('data.csv', sep='\t')
Для файлов с другим разделителем, например, точкой с запятой, указывайте соответствующий символ:
df = pd.read_csv('data.csv', sep=';')
Если разделитель – это несколько символов, используйте регулярные выражения через параметр delimiter:
df = pd.read_csv('data.csv', delimiter=r'\s+') # разделитель – один или более пробелов
При работе с неочевидными разделителями всегда полезно просмотреть первые несколько строк файла, чтобы убедиться в корректности выбранного символа-разделителя.
Обработка ошибок при загрузке CSV файла
При работе с CSV файлами в Python с использованием библиотеки pandas могут возникать различные ошибки. Чтобы эффективно обрабатывать их и избежать сбоев в работе программы, необходимо учитывать несколько ключевых аспектов.
Одна из распространённых ошибок – это отсутствие файла по указанному пути. Для её предотвращения можно использовать конструкцию try-except и проверить наличие файла перед его загрузкой:
import os
import pandas as pd
file_path = 'data.csv'
if os.path.exists(file_path):
try:
df = pd.read_csv(file_path)
except Exception as e:
print(f"Ошибка при загрузке файла: {e}")
else:
print(f"Файл {file_path} не найден.")
Другим частым источником ошибок является неправильная кодировка файла. Для её уточнения в pandas есть параметр encoding. При работе с файлами, использующими нестандартную кодировку, например, Windows-1251, следует явно указывать encoding:
df = pd.read_csv('data.csv', encoding='windows-1251')
Ошибка может возникнуть и в случае несоответствия структуры данных ожидаемому формату. Если файл поврежден или имеет неправильные разделители, можно указать параметр delimiter или sep для определения корректного разделителя. Например, для файла с табуляцией в качестве разделителя:
df = pd.read_csv('data.csv', sep='\t')
Также стоит учитывать наличие пустых строк или некорректных значений. Для таких случаев можно использовать параметр error_bad_lines, чтобы игнорировать строки с ошибками:
df = pd.read_csv('data.csv', error_bad_lines=False)
Если же требуется задать правила для обработки пропущенных значений, можно воспользоваться параметром na_values. Например, если в файле пропущенные значения представлены как ‘NA’ или ‘N/A’:
df = pd.read_csv('data.csv', na_values=['NA', 'N/A'])
Важно помнить, что при загрузке больших файлов возможна ошибка из-за превышения объема памяти. В таких случаях можно читать файл порциями, используя параметр chunksize:
chunk_size = 10000
for chunk in pd.read_csv('data.csv', chunksize=chunk_size):
process_chunk(chunk)
Использование этих методов поможет не только избежать ошибок при загрузке CSV файлов, но и эффективно обрабатывать данные в условиях нестабильных источников данных.
Загрузка CSV файла с различными кодировками

При работе с CSV файлами часто встречаются данные, закодированные в различных кодировках. Проблемы с кодировками могут привести к ошибкам при загрузке или неверному отображению символов. Чтобы корректно прочитать такие файлы в Python с использованием pandas, необходимо учитывать кодировку файла.
Для указания кодировки при чтении файла используется параметр `encoding` в функции `pandas.read_csv()`. Основные кодировки, с которыми могут возникнуть трудности, это `utf-8`, `latin1`, `windows-1251`, и `iso-8859-1`.
По умолчанию pandas пытается определить кодировку автоматически, но в случае ошибок или при наличии специфических символов полезно вручную указать кодировку. Например, для файлов, сохраненных в Windows, часто используется кодировка `windows-1251`. Для этого достаточно указать параметр:
df = pd.read_csv('file.csv', encoding='windows-1251')Если файл имеет нестандартную кодировку, можно использовать кодировку `ISO-8859-1`, которая часто помогает при загрузке файлов с европейскими символами:
df = pd.read_csv('file.csv', encoding='ISO-8859-1')В случае, если неизвестна кодировка файла, можно попробовать использовать модуль `chardet` для определения кодировки. Для этого нужно сначала установить библиотеку:
pip install chardetЗатем использовать его для определения кодировки:
import chardet
rawdata = open('file.csv', 'rb').read()
result = chardet.detect(rawdata)
encoding = result['encoding']
df = pd.read_csv('file.csv', encoding=encoding)Если кодировка всё ещё вызывает проблемы, рекомендуется проверить сам файл на наличие специфических символов или открыть его в текстовом редакторе, который отображает информацию о кодировке.
Важно помнить, что выбор правильной кодировки зависит от источника данных и региона, в котором они были созданы. Поэтому перед загрузкой данных всегда проверяйте, в какой кодировке они сохранены, чтобы избежать ошибок при их обработке.
Загрузка только нужных столбцов из CSV файла

Когда данные в CSV файле содержат много столбцов, и вам нужно работать лишь с частью из них, можно существенно повысить производительность, загружая только нужные столбцы. В pandas это достигается с помощью параметра usecols при вызове функции read_csv.
Параметр usecols принимает список строк или чисел, указывающих, какие именно столбцы из файла нужно загрузить. Например:
import pandas as pd
data = pd.read_csv('data.csv', usecols=['column1', 'column3'])
Этот код загрузит только столбцы column1 и column3 из файла data.csv.
Можно также указать столбцы по их индексам. Например:
data = pd.read_csv('data.csv', usecols=[0, 2])
Это загрузит первый и третий столбцы (нумерация начинается с 0).
Кроме того, можно использовать функцию lambda для динамического выбора столбцов. Например, чтобы загрузить только те столбцы, чьи имена начинаются с буквы «A»:
data = pd.read_csv('data.csv', usecols=lambda column: column.startswith('A'))
Этот подход полезен, когда имена столбцов имеют общий паттерн и нужно выбрать их все без явного перечисления.
Если необходимо загрузить только определённое количество первых столбцов, это можно сделать с помощью числовых индексов:
data = pd.read_csv('data.csv', usecols=range(5)) # Загружает первые 5 столбцов
Для больших файлов использование usecols помогает избежать загрузки ненужных данных в память, улучшая эффективность работы программы.
Как загружать CSV файлы с URL или из интернета
Для загрузки CSV файлов из интернета с помощью библиотеки pandas в Python, достаточно использовать функцию read_csv(), указав в качестве аргумента прямой URL-адрес файла. Это позволяет работать с данными, не загружая их на локальное устройство. Пример использования:
import pandas as pd url = "https://example.com/data.csv" data = pd.read_csv(url) print(data.head())
При загрузке данных с URL pandas автоматически обрабатывает различные форматы кодировки и параметры разделителей. Однако важно учитывать несколько моментов:
- Проверьте доступность URL: прежде чем загружать данные, убедитесь, что ссылка на файл активна и файл доступен для скачивания (например, с помощью requests или другого инструмента).
- Параметры файла: если в CSV файле используются нестандартные разделители (например, табуляции или точка с запятой), можно указать параметр sep в функции read_csv().
- Обработка ошибок: рекомендуется использовать обработку исключений для проверки ошибок при попытке загрузки данных с URL, чтобы избежать сбоев в работе программы.
Пример загрузки файла с нестандартным разделителем:
data = pd.read_csv(url, sep=";") print(data.head())
Если файл размещён за защищённым доступом (например, на сервере с авторизацией), можно использовать библиотеку requests для предварительного получения данных:
import requests response = requests.get(url) data = pd.read_csv(pd.compat.StringIO(response.text)) print(data.head())
Для повышения надёжности стоит добавить проверку статуса ответа с сервера перед обработкой данных:
if response.status_code == 200:
data = pd.read_csv(pd.compat.StringIO(response.text))
print(data.head())
else:
print("Ошибка загрузки файла")
Таким образом, загрузка CSV файлов из интернета с помощью pandas – это простая задача, если соблюдать основные принципы работы с URL и учитывать особенности данных.