Работа с XML-файлами в Python становится необходимостью в большинстве проектов, связанных с обработкой данных, веб-разработкой или интеграцией с внешними сервисами. XML (eXtensible Markup Language) – это текстовый формат, который используется для хранения и обмена структурированными данными. В Python для работы с XML существует несколько популярных библиотек, но в этом руководстве мы сосредоточимся на двух самых распространенных – xml.etree.ElementTree и lxml.
Для простых задач, таких как парсинг XML, отлично подходит стандартная библиотека xml.etree.ElementTree, которая идет в комплекте с Python. Она предоставляет простой и эффективный интерфейс для работы с XML-данными, позволяя легко загружать и анализировать их. В случае более сложных требований, например, работы с большими XML-файлами или поддержки XPath и XSLT, рекомендуется использовать библиотеку lxml, которая является более мощной, но и более тяжелой по сравнению с ElementTree.
Чтобы загрузить XML файл в Python с помощью ElementTree, необходимо использовать функцию ElementTree.parse(), которая создает дерево элементов, из которого можно извлекать данные. Пример кода:
import xml.etree.ElementTree as ET
tree = ET.parse('file.xml')
root = tree.getroot()
Этот код загружает XML-файл и получает корневой элемент, с которым можно работать дальше. Для удобства обработки данных можно использовать методы библиотеки для поиска нужных тегов, атрибутов и значений, например, find() и findall().
Для загрузки XML-файлов с использованием lxml необходимо сначала установить эту библиотеку, если она не была установлена ранее. Используйте команду pip install lxml для установки. После этого можно применить более гибкие средства обработки XML с поддержкой XPath и XSLT:
from lxml import etree
tree = etree.parse('file.xml')
root = tree.getroot()
Этот код аналогичен предыдущему примеру, но с дополнительными возможностями для выполнения сложных запросов и преобразований XML-данных. Выбор между ElementTree и lxml зависит от сложности задачи и требований к производительности.
Выбор библиотеки для работы с XML в Python
Для работы с XML в Python существует несколько популярных библиотек, каждая из которых подходит для разных задач. Выбор зависит от ваших требований по производительности, удобству и функциональности.
Вот основные библиотеки для работы с XML:
- xml.etree.ElementTree – стандартная библиотека Python. Она легка в использовании, поддерживает основные операции с XML: чтение, запись и модификацию документов. Этого достаточно для большинства задач, если не требуется высокая производительность или сложные возможности.
- lxml – сторонняя библиотека, предназначенная для более сложных операций с XML. Она быстрее, чем ElementTree, и поддерживает XPath и XSLT. Рекомендуется для работы с большими XML-файлами или когда нужно выполнять сложные запросы.
- minidom – еще одна стандартная библиотека, которая предоставляет более удобный способ работы с XML в виде дерева объектов. Она ориентирована на удобство работы с документацией, но менее эффективна по сравнению с другими библиотеками в плане производительности.
- xmltodict – простая и быстрая библиотека, которая преобразует XML в словарь Python. Подходит, если нужно быстро извлечь данные из XML без особых усилий по обработке структуры документа.
При выборе библиотеки стоит учитывать следующие факторы:
- Производительность. Если вам нужно обрабатывать большие объемы данных, стоит выбрать lxml или ElementTree, так как они быстрее других решений.
- Удобство. Если необходимо быстро обработать XML без особых усилий, xmltodict может стать отличным выбором. Она превращает XML в Python-словарь, что упрощает работу с данными.
- Функциональность. Для сложных операций, таких как запросы с использованием XPath или преобразования с использованием XSLT, лучше выбрать lxml.
- Совместимость с стандартной библиотекой. Если не хочется устанавливать дополнительные пакеты, стоит выбрать xml.etree.ElementTree или minidom, так как они являются частью стандартной библиотеки Python.
Для большинства задач стандартных библиотек вполне достаточно. Однако, если ваш проект требует работы с большими файлами или сложных запросов, стоит обратить внимание на lxml.
Чтение XML файла с использованием библиотеки ElementTree
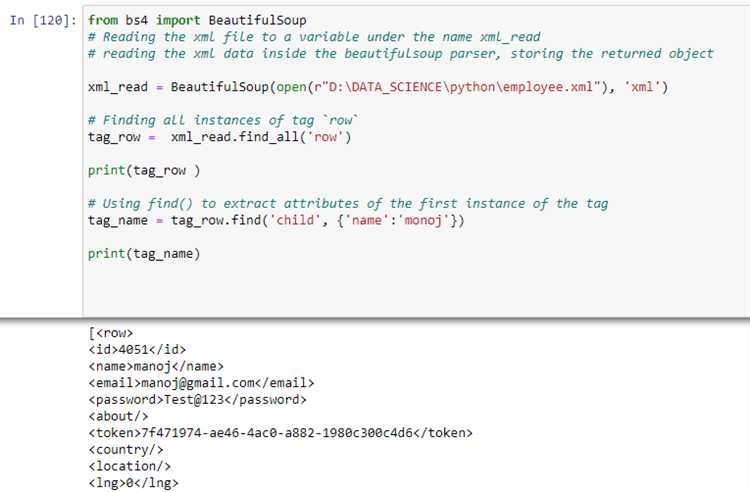
Библиотека ElementTree предоставляет простой и эффективный способ работы с XML файлами в Python. Для чтения XML документа используется метод ElementTree.parse(), который загружает содержимое файла и позволяет легко манипулировать его данными.
Пример чтения XML файла с помощью ElementTree:
import xml.etree.ElementTree as ET
# Загрузка XML файла
tree = ET.parse('example.xml')
root = tree.getroot()
# Итерация по элементам
for child in root:
print(child.tag, child.attrib)ElementTree эффективно работает с небольшими и средними XML файлами, но при работе с большими объемами данных стоит учитывать возможные проблемы с памятью. В таких случаях лучше использовать модуль lxml или подходы с потоковой обработкой данных.
Для парсинга строкового XML содержимого можно использовать функцию ET.fromstring(), что полезно при работе с данными, полученными из сети:
xml_data = '''
Метод findall() позволяет находить все элементы, соответствующие заданному тегу. В данном случае, это все элементы <item>, и для каждого извлекаются значения атрибутов name и value.
Для извлечения текстового содержимого элемента используется метод text:
for item in root.findall('item'):
print(item.text)Использование ElementTree помогает быстро и удобно обрабатывать XML данные в Python, оставаясь при этом в пределах стандартной библиотеки. Для более сложных сценариев, таких как обработка XML с использованием пространства имен или работа с большим объемом данных, может потребоваться дополнительно изучить другие библиотеки, такие как lxml.
Загрузка XML файла через библиотеку lxml
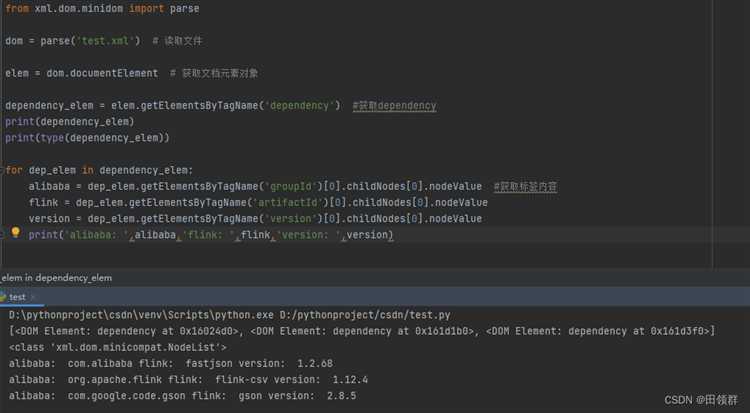
Первым шагом является установка библиотеки. Для этого нужно выполнить команду:
pip install lxml
Для загрузки XML файла через lxml, используется модуль etree, который предоставляет несколько методов для парсинга. Один из наиболее популярных – это метод etree.parse(), который позволяет загружать XML из файла или из строки. Важно помнить, что lxml поддерживает как файловые потоки, так и строки.
Пример загрузки XML из файла:
from lxml import etree
tree = etree.parse('file.xml') # загрузка XML из файла
root = tree.getroot() # получение корневого элемента
Метод getroot() возвращает корневой элемент XML документа, с которым можно работать дальше. Важно, что если файл не существует или поврежден, lxml выбросит исключение IOError, поэтому стоит обрабатывать ошибки при работе с файлом.
Загрузка XML данных из строки осуществляется с помощью метода etree.fromstring(). Например:
xml_data = '''''' root = etree.fromstring(xml_data) # загрузка XML из строки Data
После загрузки XML, можно работать с элементами документа, используя XPath запросы или методы поиска, такие как find(), findall(), и iter().
Пример поиска элементов:
child = root.find('child') # нахождение первого элемента
Если необходимо выполнить более сложные запросы, lxml поддерживает XPath. Например, для поиска всех элементов с тегом child:
children = root.xpath('//child') # поиск всех элементов
for child in children:
print(child.text)
Также, стоит отметить, что lxml поддерживает удобное сохранение изменений в XML файл через метод tree.write():
tree.write('output.xml', pretty_print=True) # сохраняет XML с отступами
Для повышения производительности при работе с большими XML файлами, можно использовать парсинг через потоковый метод etree.iterparse(), который позволяет обрабатывать элементы по мере их чтения, не загружая весь файл в память сразу. Это полезно, если файл слишком велик, чтобы загружать его целиком.
Пример потокового парсинга:
for event, element in etree.iterparse('large_file.xml', events=('end',)):
if element.tag == 'child':
print(element.text)
element.clear() # очистка элемента после обработки
Использование lxml для загрузки и обработки XML данных обеспечивает высокую производительность и гибкость, особенно при работе с большими или сложными структурами XML. Умение эффективно использовать различные методы библиотеки поможет вам оптимизировать работу с XML файлами в Python.
Работа с большими XML файлами с использованием библиотеки xml.sax
Для работы с большими XML файлами в Python часто используется библиотека xml.sax, которая реализует обработку XML данных с помощью событийного подхода. Это особенно важно, когда файл имеет гигантский размер и не может быть загружен целиком в память.
Библиотека xml.sax предоставляет механизм потоковой обработки, что позволяет анализировать XML файл по частям, обрабатывая каждую часть документа по мере её поступления. Такой подход помогает избежать проблемы недостатка памяти при работе с большими данными.
Для начала работы с xml.sax необходимо создать обработчик событий, который будет реагировать на различные элементы XML документа. В отличие от других методов парсинга (например, с использованием библиотеки ElementTree), здесь мы сами определяем, как обработать каждый элемент документа, который встречается при его чтении.
Пример базовой реализации обработчика:
import xml.sax
class MyHandler(xml.sax.ContentHandler):
def startElement(self, name, attrs):
print(f"Начало элемента: {name}")
pythonEditdef endElement(self, name):
print(f"Конец элемента: {name}")
def characters(self, content):
print(f"Содержимое: {content}")
Создание парсера и привязка обработчика
parser = xml.sax.make_parser()
handler = MyHandler()
parser.setContentHandler(handler)
Чтение XML файла
with open("bigfile.xml", "r") as f:
parser.parse(f)В этом примере создается класс MyHandler, который переопределяет методы startElement, endElement и characters. Эти методы срабатывают, когда парсер встречает определенные части документа: начало и конец элемента, а также содержимое между тегами.
Если XML файл слишком большой, чтобы загрузить его целиком, xml.sax будет читать файл построчно и обрабатывать его по частям, что позволяет экономить память и ускорять работу с файлами большого размера.
Для эффективной работы с большими файлами важно учесть следующие моменты:
- Использование потоковой обработки позволяет снизить нагрузку на память.
- Нужно минимизировать количество операций, выполняемых внутри обработчиков, так как каждый вызов события может замедлить процесс парсинга.
- Если файл очень большой, то стоит заранее подумать о производительности и эффективно организовать обработку данных.
В случаях, когда необходимо извлечь только определенную информацию из файла (например, значения атрибутов или элементы с конкретными тегами), можно дополнительно фильтровать события внутри обработчиков, чтобы избежать ненужной обработки всех элементов файла.
Библиотека xml.sax также поддерживает работу с внешними сущностями и DTD, что делает её удобной для сложных XML документов. Однако для работы с DTD требуется установить дополнительный параметр xml.sax.xmlreader.XMLReader.
Обработка ошибок при загрузке XML файлов в Python
Основная ошибка при работе с XML файлами – это неправильный синтаксис файла. Прежде чем приступить к обработке, нужно убедиться, что файл является валидным XML. В Python это можно сделать с помощью библиотеки lxml или стандартной библиотеки xml.etree.ElementTree, которая при некорректном формате поднимет исключение ET.ParseError.
Пример:
import xml.etree.ElementTree as ET
try:
tree = ET.parse('file.xml')
except ET.ParseError as e:
print(f"Ошибка парсинга XML: {e}")
Ошибки, связанные с отсутствием файла или проблемами с доступом к нему, обрабатываются с помощью исключений FileNotFoundError или PermissionError. Важно заранее проверять существование файла и его доступность для чтения, чтобы избежать этих ошибок.
Пример:
try:
with open('file.xml', 'r') as file:
tree = ET.parse(file)
except FileNotFoundError:
print("Файл не найден.")
except PermissionError:
print("Нет прав доступа к файлу.")
При работе с большими XML файлами может возникнуть ошибка переполнения памяти. Для предотвращения этого лучше использовать потоковый парсинг, например, с использованием xml.sax или lxml.etree.iterparse, которые позволяют обрабатывать файл по частям, не загружая его целиком в память.
Пример использования iterparse:
import lxml.etree as ET
for _, elem in ET.iterparse('large_file.xml', events=('start', 'end')):
if _ == 'start':
print(f"Обработан элемент: {elem.tag}")
elem.clear() # Очистка памяти от уже обработанных элементов
Если файл содержит невалидные данные, которые не могут быть обработаны стандартными средствами, можно воспользоваться библиотекой lxml, которая поддерживает более сложные структуры и может распознавать ошибки в невалидных данных.
Не менее важна обработка ошибок, связанных с кодировкой XML файла. Если файл закодирован в нестандартной кодировке, Python может не правильно интерпретировать его содержимое. В таких случаях следует указывать кодировку явно при чтении файла.
with open('file.xml', 'r', encoding='utf-8') as file:
tree = ET.parse(file)
Если файл содержит неправильную кодировку или она не указана, это может привести к ошибке UnicodeDecodeError. Рекомендуется всегда проверять кодировку файла перед его загрузкой или использовать более универсальные методы, например, chardet, для определения кодировки.
Подводя итог, можно выделить несколько важных аспектов для надежной работы с XML файлами:
- Использование обработчиков исключений для проверки синтаксических ошибок.
- Работа с файлами через контекстный менеджер для безопасного открытия и закрытия файлов.
- Применение потокового парсинга для работы с большими XML файлами.
- Корректная обработка ошибок кодировки и файловых ошибок.
Парсинг данных из XML файла после его загрузки
После того как XML файл успешно загружен в Python, необходимо извлечь из него данные. Для этого можно использовать стандартные библиотеки, такие как `xml.etree.ElementTree` или сторонние решения, например, `lxml`. Рассмотрим наиболее эффективные подходы с примерами.
Для начала загрузим XML файл в объект, который можно будет анализировать:
import xml.etree.ElementTree as ET
tree = ET.parse('data.xml')
root = tree.getroot()
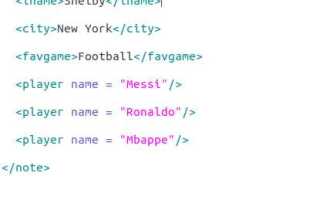
После того как объект загружен, основная задача – извлечь нужные элементы и атрибуты. В XML-документе данные представлены в виде элементов с тегами. Например:
Иван
30
Красная площадь
Москва
Для того чтобы извлечь имя и возраст, нужно использовать методы, которые позволяют обращаться к элементам по тегам:
name = root.find('person/name').text
age = root.find('person/age').text
Метод `find()` возвращает первый найденный элемент, а свойство `text` извлекает содержимое тега. Если нужно получить все элементы с определенным тегом, используйте метод `findall()`:
persons = root.findall('person')
for person in persons:
name = person.find('name').text
age = person.find('age').text
print(f'Имя: {name}, Возраст: {age}')
Для работы с атрибутами элементов применяется метод `get()`:
address = person.find('address')
street = address.find('street').text
city = address.find('city').text
print(f'Улица: {street}, Город: {city}')
Если данные в XML содержат вложенные элементы, можно использовать методы поиска по атрибутам или тегам, комбинируя их:
person = root.find(".//person[@id='123']")
Если файл содержит большое количество данных, для оптимизации можно обрабатывать XML потоково, используя библиотеку `lxml` с элементом `iterparse`, чтобы избежать загрузки всего документа в память.
Пример работы с потоком:
from lxml import etree
for _, element in etree.iterparse('data.xml', events=('end',)):
if element.tag == 'person':
name = element.find('name').text
print(name)
element.clear()
Этот способ экономит память при обработке крупных XML файлов, так как элементы очищаются после обработки.
Таким образом, для парсинга данных из XML файла нужно выбрать подходящий инструмент в зависимости от объема данных и сложности структуры документа. В большинстве случаев для простых файлов достаточно библиотеки `xml.etree.ElementTree`, а для работы с большими и сложными документами лучше использовать `lxml` и методы потоковой обработки.