Работа с текстовыми файлами – одна из наиболее частых задач при программировании на Python. Несмотря на кажущуюся простоту, правильная обработка файлов требует знания нескольких ключевых аспектов. В этом руководстве мы рассмотрим эффективные способы чтения текстовых файлов, их обработку и возможные ошибки, с которыми можно столкнуться в процессе работы.
Самый простой способ прочитать содержимое файла – это использовать встроенную функцию open(). Она открывает файл в определённом режиме, например, для чтения ‘r’. После этого можно использовать методы read(), readline() или readlines(), в зависимости от того, как именно необходимо извлечь информацию из файла.
При чтении больших файлов важно помнить о потреблении памяти. Для этого следует использовать построчное чтение с помощью readline(), чтобы не загружать весь файл в память сразу. Такой подход полезен, если размер файла значительно превышает объём доступной оперативной памяти.
Важно всегда закрывать файлы после работы с ними, чтобы освободить системные ресурсы. Для этого можно использовать конструкцию with open() as file:, которая гарантирует автоматическое закрытие файла после завершения блока кода.
Открытие текстового файла с использованием функции open()
Режим открытия файла может быть различным, и каждый из них имеет своё назначение:
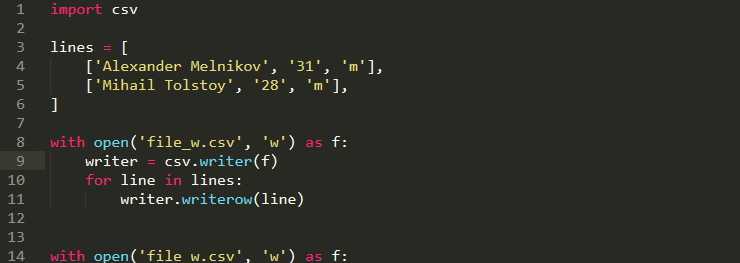
'r'– Открытие файла для чтения (по умолчанию). Если файл не существует, возникает ошибка.'w'– Открытие файла для записи. Если файл существует, его содержимое перезаписывается.'a'– Открытие файла для добавления. Если файл существует, новые данные добавляются в конец файла. Если файл не существует, создается новый.'b'– Бинарный режим. Используется вместе с другими режимами, например,'rb'или'wb', для работы с бинарными файлами.'x'– Открытие файла для создания. Файл создается, если его нет, в противном случае возникает ошибка.
Пример открытия файла в режиме чтения:
file = open('example.txt', 'r')После вызова функции open() файл необходимо закрывать, чтобы освободить ресурсы системы. Для этого используется метод close():
file.close()Однако более безопасный способ работы с файлами – использовать конструкцию with, которая автоматически закрывает файл после завершения работы с ним:
with open('example.txt', 'r') as file:
content = file.read()Использование with исключает необходимость вручную закрывать файл, что важно для предотвращения утечек ресурсов в случае ошибок в процессе работы с файлом.
Чтение всего содержимого файла с методом read()

Метод read() в Python используется для чтения всего содержимого файла. Этот метод загружает данные в память в виде одной строки, включая символы новой строки. Он идеален для работы с не очень большими файлами, где нужно извлечь всё содержимое сразу. Однако, следует учитывать, что при чтении больших файлов может возникнуть нехватка памяти.
Пример использования метода read():
with open('example.txt', 'r') as file:
content = file.read()
print(content)Здесь файл открывается с помощью контекстного менеджера with, что гарантирует автоматическое закрытие файла после завершения работы. Метод read() считывает весь текст из файла и сохраняет его в переменную content.
Метод read() возвращает строку, которая включает в себя все символы, включая пробелы и символы новой строки. Если файл пуст, метод вернёт пустую строку.
Для более эффективного чтения больших файлов стоит использовать альтернативные методы, такие как readline() или чтение файла по частям, чтобы избежать перегрузки памяти. В случае, если файл слишком велик для того, чтобы загружать его целиком в память, стоит использовать другие подходы, например, чтение файла построчно или поблочно с помощью метода read(size), где size определяет количество символов для считывания за один раз.
При использовании метода read() важно также помнить о кодировке файла. Если файл содержит символы, которые не соответствуют стандартной кодировке, это может вызвать ошибку при чтении. В таких случаях рекомендуется явно указать кодировку при открытии файла:
with open('example.txt', 'r', encoding='utf-8') as file:
content = file.read()
print(content)Такой подход позволяет избежать ошибок при работе с файлами в разных кодировках, например, если файл содержит символы из разных языков.
Чтение файла построчно с методом readline()
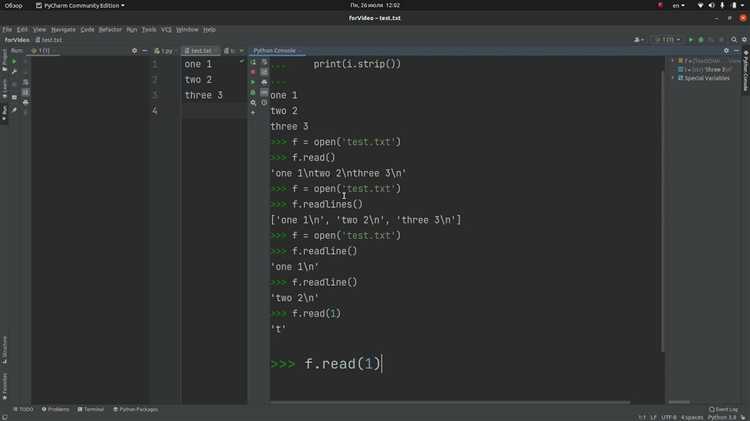
Метод readline() в Python позволяет считывать файл построчно, что эффективно при работе с большими файлами, где загрузка всего содержимого в память может быть проблематичной. Этот метод считывает строку из файла и возвращает её как строку. После этого указатель файла перемещается на следующую строку. Если файл достигнут конца, readline() вернёт пустую строку.
Пример использования:
with open('example.txt', 'r') as file:
line = file.readline()
while line:
print(line.strip()) # strip удаляет символы новой строки
line = file.readline()В данном примере файл открывается с помощью контекстного менеджера with, который автоматически закрывает файл по завершении работы. Метод readline() извлекает одну строку за раз, а цикл продолжается до тех пор, пока не будет достигнут конец файла.
Особенность метода readline() заключается в том, что он читает строки по одной, что снижает нагрузку на память, особенно при работе с большими файлами. Однако стоит помнить, что для маленьких файлов использование этого метода может быть не самым эффективным решением, так как обычное чтение с помощью readlines() или for line in file может быть быстрее.
Также важно отметить, что если файл содержит очень длинные строки, то readline() будет читать их целиком, что может привести к высокому расходу памяти. В таких случаях лучше обрабатывать данные построчно, избегая чтения слишком больших блоков данных за раз.
Если необходимо обработать только первые несколько строк, можно использовать метод readline() в сочетании с циклом, прерывая его после нужного числа итераций:
with open('example.txt', 'r') as file:
for _ in range(5): # Прочитать первые 5 строк
print(file.readline().strip())Таким образом, метод readline() полезен при необходимости построчного анализа файлов, обеспечивая более эффективное использование памяти по сравнению с полным чтением файлов в память.
Использование метода readlines() для получения списка строк

Метод readlines() позволяет считать все строки из текстового файла и вернуть их в виде списка. Каждый элемент списка представляет собой одну строку из файла, включая символы новой строки (\n), если они присутствуют в оригинале. Это особенно удобно, когда необходимо обработать файл построчно или выполнить дополнительные манипуляции с каждой строкой.
Пример использования метода:
with open('example.txt', 'r') as file:
lines = file.readlines()
for line in lines:
В данном примере файл открывается в режиме чтения (‘r’). Метод readlines() возвращает список строк, после чего можно пройтись по каждому элементу списка. Важно отметить, что символ новой строки \n, который присутствует в конце каждой строки, будет сохранён. Для удаления этого символа часто используют метод strip().
Метод readlines() полезен, когда файл не слишком большой, поскольку он загружает все строки в память сразу. Для работы с очень большими файлами лучше использовать методы, которые считывают данные по частям, например, read() или итераторы файлов.
Еще одно важное замечание – метод readlines() можно использовать с параметром, который указывает на размер буфера. В таком случае метод будет читать данные по частям, но при этом строки будут возвращаться целыми. Этот подход помогает эффективно работать с большими файлами, сохраняя структуру строк.
Работа с контекстным менеджером для автоматического закрытия файла
Для работы с контекстным менеджером в Python используется конструкция with, которая обеспечивает правильное открытие и закрытие файлов. В отличие от стандартного метода с использованием open() и явного вызова close(), контекстный менеджер берет на себя все необходимые действия по освобождению ресурса.
Пример использования контекстного менеджера для чтения файла:
with open('example.txt', 'r') as file:
content = file.read()
print(content)
with open('example.txt', 'r') as file:– открывает файл в режиме чтения.file.read()– считывает весь текст из файла.- После завершения работы с файлом, Python автоматически вызовет
file.close(), даже если в процессе возникнут ошибки.
Важно отметить, что контекстный менеджер может быть использован не только для чтения файлов, но и для записи или добавления данных:
with open('example.txt', 'w') as file:
file.write('Hello, world!')
В этом случае файл будет открыт для записи, и после завершения блока with файл автоматически закроется.
- Использование контекстного менеджера обеспечивает точную очистку ресурсов, снижая вероятность утечек памяти или других ошибок.
- Этот подход рекомендуется при работе с файлами, особенно если предстоит работать с большими объемами данных или файлами, которые могут быть повреждены из-за неправильного закрытия.
- Контекстный менеджер исключает необходимость ручного закрытия файла, что упрощает код и делает его более читаемым.
Еще одним преимуществом является обработка исключений. Если в блоке with возникнет ошибка, файл все равно будет закрыт корректно:
with open('example.txt', 'r') as file:
content = file.read()
raise ValueError("Пример ошибки")
В этом примере ошибка ValueError будет вызвана после чтения файла, однако контекстный менеджер гарантирует, что файл будет закрыт перед возникновением исключения.
Контекстный менеджер используется не только для файлов, но и для других ресурсов, таких как сетевые соединения или базы данных, что делает его универсальным инструментом для управления ресурсами в Python.
Обработка ошибок при чтении текстового файла
При работе с текстовыми файлами в Python важно учитывать возможные ошибки, которые могут возникнуть во время чтения данных. Эти ошибки могут быть связаны как с самим файлом, так и с его содержимым. Рассмотрим наиболее распространенные ошибки и методы их обработки.
Основные ошибки, с которыми можно столкнуться при чтении файла, следующие:
- FileNotFoundError – файл не найден. Это самая распространенная ошибка при попытке открыть несуществующий файл.
- IsADirectoryError – попытка открыть каталог как файл.
- UnicodeDecodeError – ошибка декодирования. Происходит, если файл имеет неправильную кодировку или если он содержит символы, которые не могут быть интерпретированы в выбранной кодировке.
Для эффективной обработки ошибок следует использовать конструкции try-except. Пример обработки ошибок при чтении файла:
try:
with open('example.txt', 'r', encoding='utf-8') as file:
content = file.read()
except FileNotFoundError:
print("Файл не найден.")
except IsADirectoryError:
print("Попытка открыть каталог как файл.")
except IOError:
except UnicodeDecodeError:
print("Ошибка декодирования файла. Неверная кодировка.")
except Exception as e:
print(f"Неизвестная ошибка: {e}")Такой подход позволяет отлавливать ошибки и информировать пользователя о причине сбоя. Рассмотрим конкретные рекомендации по обработке различных ошибок:
- FileNotFoundError: перед открытием файла полезно проверить его существование с помощью функции
os.path.exists(). Это уменьшит количество ошибок в коде. - IsADirectoryError: перед открытием файла всегда проверяйте, что путь указывает на файл, а не на каталог. Можно использовать
os.path.isfile()для этой проверки. - IOError: для обработки подобных ошибок можно добавить логику повторной попытки открыть файл с задержкой или уведомить пользователя о возможных причинах, таких как проблемы с правами доступа.
- UnicodeDecodeError: для работы с файлами, содержащими нестандартные символы, всегда указывайте кодировку при открытии файла. Лучше использовать
utf-8, но если это не подходит, можно указать другую кодировку, напримерISO-8859-1.
Также важно учитывать, что конструкции try-except могут использоваться для отслеживания нестандартных ситуаций, например, ошибок в формате содержимого файла. Например, если файл должен содержать только числа, но встречаются символы, можно обработать это с помощью проверки в блоке except.
Правильная обработка ошибок не только помогает предотвратить сбои программы, но и дает пользователю точные и понятные сообщения об ошибках, что делает приложение более удобным в использовании.