В Python часто требуется преобразовывать строки в структуру данных, удобную для дальнейшей обработки. Одним из таких вариантов является создание двумерного массива, где строки текста становятся отдельными элементами. Этот подход полезен при работе с текстами, требующими структурирования для анализа или визуализации. Рассмотрим, как эффективно превратить строку текста в двумерный массив с помощью стандартных библиотек Python.
Для преобразования текста в двумерный массив обычно используется разделение строки на слова или фразы, после чего каждая часть преобразуется в отдельный список. Это позволяет работать с текстом, как с набором строк и столбцов, где можно легко манипулировать данными, проводить поиск или замену элементов.
Ключевым моментом при таком преобразовании является выбор разделителей для разбивки текста. Строки могут быть разделены пробелами, знаками препинания или другими символами. Рекомендуется использовать регулярные выражения для более гибкого контроля над процессом разделения текста, что позволяет учитывать различные варианты разделителей и исключать лишние пробелы.
Пример реализации такой задачи в Python выглядит следующим образом. Сначала строка текста разбивается на строки по заданному критерию, а затем каждая строка разделяется на слова, формируя двумерный массив. Такой подход гарантирует гибкость при работе с текстами разных форматов и помогает легко адаптировать решение под конкретные требования задачи.
Как разбить строку на строки с фиксированной длиной
text = "Пример строки для разделения"
length = 5
result = [text[i:i+length] for i in range(0, len(text), length)]
print(result)Этот метод разбивает строку на подстроки длиной 5 символов. Сначала устанавливается переменная length, определяющая нужную длину строк, а затем в списковом включении с помощью среза (text[i:i+length]) создаются подстроки. Это эффективный способ, так как он не требует дополнительных библиотек и работает быстро для большинства случаев.
Также можно воспользоваться библиотекой textwrap, которая предоставляет готовые инструменты для разделения строк. Метод wrap() позволяет автоматически разделять текст на строки с заданной максимальной длиной:
import textwrap
text = "Пример строки для разделения"
result = textwrap.wrap(text, width=5)
print(result)Этот подход полезен, когда необходимо обработать более сложные строки, например, с переносами или различными разделителями. wrap() возвращает список строк, каждая из которых не превышает указанную длину.
В случае, если нужно обеспечить разделение на строки с длиной, которая не превышает определённого лимита, но при этом сохранить слова целыми, можно использовать метод fill():
result = textwrap.fill(text, width=5)
print(result)Метод fill() возвращает строку, в которой все слова остаются целыми, а строки не превышают максимальную длину. Он полезен, когда важно избежать разрыва слов на части.
Использование метода split() для разделения текста по символам
Пример использования метода split() для получения списка символов строки:
text = "Пример текста"
result = text.split('')
print(result)
Однако стоит помнить, что передача пустой строки как аргумента может вызвать ошибку. Вместо этого можно применить метод list(), который гарантированно создаст список, где каждый элемент будет отдельным символом строки:
text = "Пример текста" result = list(text) print(result)
Такой подход удобен, если необходимо работать с каждым символом строки по отдельности. Это может быть полезно, например, при обработке текстовых данных или преобразовании текста в двумерный массив.
Также стоит отметить, что метод split() работает эффективно с разделителями, которые могут быть как пробелами, так и другими символами. Однако для разделения строки на отдельные символы его применение не является прямым и требует дополнительных шагов. Использование list() будет более предпочтительным в таких случаях, так как оно напрямую разделяет строку по символам без необходимости указания разделителей.
Как преобразовать список строк в двумерный массив
Для преобразования списка строк в двумерный массив в Python можно использовать метод разбиения строк на подстроки с помощью метода split(). Предположим, что каждая строка списка представляет собой данные, разделённые каким-либо разделителем, например, пробелами или запятыми. Задача состоит в том, чтобы превратить этот список в структуру, удобную для дальнейшей работы, такую как двумерный массив.
Пример с использованием пробела в качестве разделителя:
data = ["1 2 3", "4 5 6", "7 8 9"]
array = [row.split() for row in data]
В этом примере каждая строка разбивается на элементы, а результат преобразуется в список списков, что и является двумерным массивом. Важно заметить, что элементы будут строками. Если необходимо преобразовать их в числовые значения, можно дополнительно использовать map(int, row.split()).
Другой вариант – использование библиотеки numpy, которая предоставляет удобные способы работы с двумерными массивами. В случае работы с числовыми данными, можно сразу создать массив из списка строк:
import numpy as np
data = ["1 2 3", "4 5 6", "7 8 9"]
array = np.array([list(map(int, row.split())) for row in data])
Здесь каждая строка преобразуется в список чисел, а затем строится двумерный массив numpy, что значительно облегчает математические операции с данными.
При использовании других разделителей, таких как запятая или точка с запятой, просто замените пробел на нужный символ в методе split().
Метод подходит для любых текстовых данных, если они имеют чёткую структуру, например, таблицы или CSV-файлы, где строки содержат несколько значений, разделённых одинаковыми символами.
Разбиение текста по пробелам и создание двумерной структуры
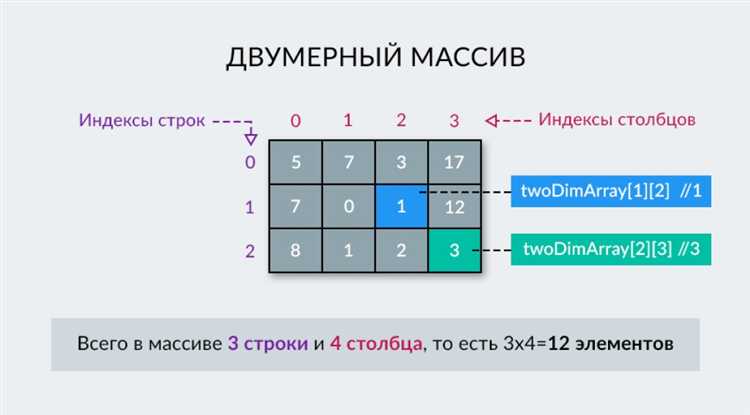
Например, если есть строка:
text = "это пример текста"Выполнив text.split(), получим список:
["это", "пример", "текста"]Для создания двумерного массива часто нужно разбить текст не только по пробелам, но и по строкам. Чтобы добиться этого, сначала применяем splitlines() для разделения текста на строки, а затем на каждую строку накладываем split() для выделения слов. Пример:
text = "первая строка\nвторая строка\nтретья строка"
lines = text.splitlines()
result = [line.split() for line in lines]
print(result)Этот код создает двумерный список, где каждая строка преобразована в список слов:
[["первая", "строка"], ["вторая", "строка"], ["третья", "строка"]]Важно: при необходимости учесть различные разделители (например, запятые или точки с запятой), можно передать их в качестве аргумента методу split(). Например:
text = "яблоки, груши, бананы"
result = text.split(", ")
print(result)Это даст результат:
["яблоки", "груши", "бананы"]Этот подход позволяет гибко работать с текстовыми данными, разбивая их на логические единицы и создавая структуру, удобную для дальнейшей обработки.
Как использовать регулярные выражения для обработки текста

Регулярные выражения (regex) – мощный инструмент для поиска и обработки текста. В Python модуль re предоставляет функционал для работы с регулярными выражениями. Они позволяют эффективно извлекать, изменять и анализировать строки, что особенно полезно при преобразовании текста в структуру, такую как двумерный массив.
Основные операции, которые можно выполнить с помощью регулярных выражений:
- Поиск подстрок: Регулярные выражения позволяют искать в строках определённые шаблоны. Это удобно для поиска чисел, дат, ключевых слов и т. д.
- Замена: С помощью регулярных выражений можно заменить части строки, что полезно для очистки текста от лишних символов или форматирования.
- Разделение строк: Регулярные выражения позволяют разделять строки по определённым шаблонам, например, по пробелам или знакам препинания, что важно при разбивке текста на массивы.
Пример использования регулярных выражений в Python:
import re # Пример поиска всех чисел в строке text = "В этом тексте есть 10 чисел, например, 20 и 30." numbers = re.findall(r'\d+', text)
В данном примере используется регулярное выражение \d+, которое находит все последовательности цифр в строке.
Регулярные выражения могут быть сложными, но их преимущества заключаются в том, что они позволяют выполнять обработку данных быстрее и с меньшими затратами ресурсов по сравнению с традиционными методами. Вот несколько полезных функций из модуля re:
- re.match() – проверяет, начинается ли строка с шаблона.
- re.search() – находит первое вхождение шаблона в строке.
- re.findall() – находит все вхождения шаблона и возвращает их в виде списка.
- re.sub() – заменяет все вхождения шаблона на указанный текст.
Для обработки текста с использованием регулярных выражений можно эффективно применить методы findall() или split() для разбивки текста на слова или фразы, а затем конвертировать их в двумерный массив.
Пример разделения текста на двумерный массив слов:
text = "Это первый пример текста. Вот второй пример." words = re.split(r'\s+|\.', text)
Здесь используется регулярное выражение \s+|\., которое разделяет строку по пробелам и точкам. В результате получается массив слов, который затем можно преобразовать в двумерный массив.
Использование регулярных выражений позволяет значительно упростить обработку текста, повысив точность и скорость выполнения задач, связанных с анализом строковых данных.
Создание двумерного массива из текста с разделителями
Чтобы преобразовать текст в двумерный массив в Python, можно использовать метод разделения строки с помощью определённых разделителей. Важно заранее определиться с разделителями, которые будут использоваться для разделения текста на строки и элементы внутри каждой строки. Например, если строки разделены символами новой строки, а элементы внутри строк – пробелами или запятыми, это можно учесть при разработке алгоритма.
Простейший способ – это использование метода split(). Для разделения строк можно использовать символ новой строки (\n), а для элементов внутри строки – пробел или любой другой символ. Пример:
text = "яблоко, груша, банан\nкрасный, зелёный, жёлтый\nсобака, кошка, птица"
array = [line.split(', ') for line in text.split('\n')]
print(array)
Здесь текст разделяется на строки с помощью split('\n'), а затем каждая строка разбивается на элементы по запятой и пробелу с помощью split(', ').
Если требуется использовать несколько разделителей для строки, например, пробел и запятая, можно воспользоваться регулярными выражениями с модулем re. Пример:
import re
text = "яблоко, груша, банан\nкрасный, зелёный, жёлтый\nсобака, кошка, птица"
array = [re.split('[, ]+', line) for line in text.split('\n')]
print(array)
В этом примере регулярное выражение [, ]+ разделяет строку как по пробелу, так и по запятой, что позволяет гибко обрабатывать разные разделители.
Также стоит помнить, что при работе с текстами, содержащими специальные символы или пробелы в начале/конце строк, полезно использовать метод strip(), чтобы удалить лишние пробелы перед и после строки, предотвращая возможные ошибки при разделении.
Используя эти методы, можно эффективно преобразовывать текст в двумерные массивы, независимо от сложности формата данных.
Как учесть пробелы и символы новой строки при разбиении
При разбиении текста на двумерный массив в Python важно правильно обработать пробелы и символы новой строки, чтобы сохранить структуру данных. Использование метода split() может привести к нежелательным результатам, если не учитывать эти символы.
Для точного разделения текста с учётом пробелов и символов новой строки следует использовать регулярные выражения через модуль re. Например, можно учесть не только обычные пробелы, но и несколько пробелов подряд или символы новой строки (\n) и возврата каретки (\r).
Для учёта пробелов и новых строк можно применить следующий подход:
import re text = "Пример текста\nс несколькими пробелами и строками.\nНовая строка." # Разбиение по пробелам и символам новой строки result = re.split(r'\s+', text) print(result)
В данном примере регулярное выражение \s+ разделяет строку по любым пробельным символам, включая пробелы, табуляции и символы новой строки. Это позволяет точно разделить текст, учитывая структуру, без потери информации о разделителях.
Если требуется сохранить сам символ новой строки как отдельный элемент в массиве, можно использовать следующее регулярное выражение:
result = re.split(r'(\s+|\n)', text)
Это разбиение учтет не только пробелы и табуляции, но и отдельные строки, включая их как отдельные элементы в массиве, что полезно, если необходимо дальнейшее управление текстом в строках.
Для более сложных случаев, например, если текст содержит много нестандартных символов или требуется определённая логика разбиения, можно комбинировать различные выражения и методы работы с текстом, включая предварительную очистку или замены.
Как преобразовать строку в двумерный массив с учётом длины слов
Допустим, у нас есть строка, содержащая несколько слов, разделённых пробелами. Задача состоит в том, чтобы преобразовать эту строку в двумерный массив, где каждая строка будет иметь длину, соответствующую количеству символов в слове.
Пример исходной строки:
"Пример строки для преобразования"
Шаги для преобразования:
- Шаг 1: Разделим строку на слова. Для этого используем метод
split(), который разделяет строку по пробелам. - Шаг 2: Для каждого слова определим его длину и сформируем строки, состоящие из повторяющихся символов, которые соответствуют длине слова.
- Шаг 3: Результатом будет двумерный массив, в котором каждая строка имеет длину, равную длине слова из исходной строки.
Пример реализации на Python:
input_string = "Пример строки для преобразования" words = input_string.split() Создаем двумерный массив two_dimensional_array = [[word[i] for i in range(len(word))] for word in words] print(two_dimensional_array)
В результате получаем следующий двумерный массив:
[['П', 'р', 'и', 'м', 'е', 'р'], ['с', 'т', 'р', 'о', 'к', 'и'], ['д', 'л', 'я'], ['п', 'р', 'е', 'о', 'б', 'р', 'а', 'з', 'о', 'в', 'а', 'н', 'и', 'я']]
Каждый подмассив в данном случае соответствует одному слову, и каждый элемент в подмассиве – это отдельный символ из этого слова.
Примечания:
- Для более сложных разделителей (например, запятых или точек) можно использовать регулярные выражения с модулем
re. - Этот метод также может быть полезен для анализа или манипуляции текстами, где важна длина слов и их структура.
- Если нужно работать с заглавными и строчными буквами отдельно, перед преобразованием можно привести строку к одному регистру с помощью метода
lower()илиupper().
Таким образом, преобразование строки в двумерный массив с учётом длины слов позволяет удобно структурировать данные для дальнейшего анализа или обработки текста в Python.