В Python 3 существует несколько проверенных методов, которые могут значительно ускорить выполнение кода. От правильного использования библиотек до оптимизации алгоритмов – каждый из этих способов влияет на общую скорость работы программы. Важно понимать, что улучшение производительности зависит от специфики задачи и структуры проекта, поэтому универсальные решения не всегда подходят.
Использование встроенных функций и библиотек – это один из самых быстрых путей к оптимизации. Например, операции с коллекциями (списки, множества, словари) можно ускорить с помощью встроенных функций, таких как map() или filter(), которые часто оказываются быстрее обычных циклов for. Для работы с большими объемами данных стоит использовать библиотеки, такие как NumPy и Pandas, которые значительно быстрее стандартных структур данных благодаря реализации на C.
Профилирование и анализ кода помогут выявить узкие места в программе. Инструменты профилирования, такие как cProfile, позволяют точно определить, какие части программы занимают наибольшее время. Используя эти данные, можно внести целенаправленные улучшения, например, оптимизировать алгоритмы или перераспределить вычисления.
Вместе с этим стоит учитывать правильное использование кеширования, которое позволяет ускорить выполнение повторяющихся вычислений. Библиотека functools и декоратор lru_cache предоставляют удобные инструменты для реализации кеширования и значительного сокращения времени выполнения функций с часто повторяющимися результатами.
Оптимизация работы с циклом: Как минимизировать излишние вычисления

1. Вычисления вне цикла
Если значение, которое используется внутри цикла, не изменяется, его можно вычислить один раз до начала выполнения цикла. Например, если вы вычисляете длину списка в каждом проходе, это можно сделать один раз:
# Неоптимизированный код:
for i in range(len(my_list)):
if len(my_list) > 5:
do_something()
Оптимизированный код:
list_length = len(my_list)
for i in range(list_length):
if list_length > 5:
do_something()
2. Использование генераторов вместо списков
Вместо создания списка с помощью конструкции list comprehension для обработки данных лучше использовать генераторы. Генератор выполняет итерацию данных «по мере необходимости», что экономит память и уменьшает нагрузку на процессор.
# Неоптимизированный код:
squared_numbers = [x 2 for x in range(1000)]
Оптимизированный код:
squared_numbers = (x 2 for x in range(1000))
3. Избежание ненужных вызовов функций
Каждый вызов функции в Python может быть дорогим. Если в цикле часто вызывается одна и та же функция с одинаковыми параметрами, вычисление результата может быть выполнено один раз вне цикла. Использование кэширования или предварительных вычислений может существенно ускорить выполнение.
# Неоптимизированный код:
for x in range(1000):
do_something(expensive_function(x))
Оптимизированный код:
cached_results = {x: expensive_function(x) for x in range(1000)}
for x in range(1000):
do_something(cached_results[x])
4. Использование встроенных функций и библиотек
Встроенные функции и библиотеки Python, такие как map, filter, или itertools, часто гораздо быстрее, чем самописные реализации. Эти функции написаны на C и имеют минимальные накладные расходы.
# Неоптимизированный код:
results = []
for x in range(1000):
if x % 2 == 0:
results.append(x)
Оптимизированный код:
from itertools import compress
results = list(compress(range(1000), (x % 2 == 0 for x in range(1000))))
5. Разбиение работы на части
Если задача в цикле является вычислительно сложной, можно разбить её на несколько частей и использовать многозадачность. Например, можно использовать многозадачность с помощью concurrent.futures, чтобы распараллелить вычисления. Однако стоит помнить, что многозадачность требует дополнительных усилий для синхронизации и обработки ошибок.
6. Остановка цикла при выполнении условия
Иногда цикл можно завершить раньше, если достигается определенное условие. В таких случаях стоит использовать команду break, чтобы избежать излишних вычислений. Например, если в поиске максимального значения в списке можно остановиться, когда текущий элемент уже больше найденного максимума.
# Неоптимизированный код:
max_value = None
for x in range(1000):
if max_value is None or x > max_value:
max_value = x
Оптимизированный код:
max_value = None
for x in range(1000):
if max_value is None or x > max_value:
max_value = x
if x == 500: # Остановить на 500
break
Минимизация излишних вычислений в циклах может существенно улучшить производительность. Эффективное использование памяти и вычислительных ресурсов позволяет работать с большими объемами данных, избегая ненужных затрат времени на обработку.
Использование встроенных библиотек для ускорения кода
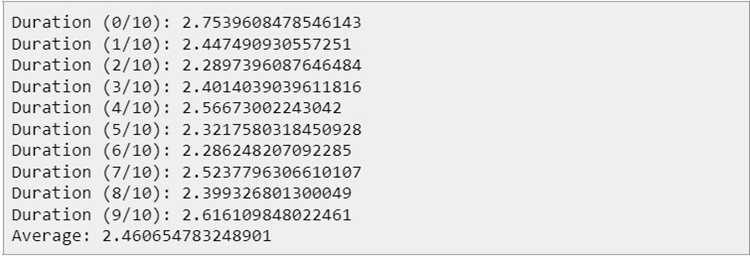
Встроенные библиотеки Python предоставляют высокопроизводительные решения для часто используемых задач, что может значительно ускорить выполнение программы. Использование таких библиотек, как `collections`, `itertools`, `functools` и других, позволяет избежать написания медленных пользовательских решений, а также использовать оптимизированные алгоритмы и структуры данных.
Одной из мощных библиотек является `collections`, которая включает в себя структуры данных, такие как `deque`, `Counter`, `OrderedDict` и `defaultdict`. Например, для работы с очередями и стеками лучше использовать `deque`, который предоставляет быстрые операции добавления и удаления элементов с обоих концов. В отличие от обычных списков, `deque` не требует сдвига всех элементов при добавлении или удалении, что делает его более эффективным в таких сценариях.
Библиотека `itertools` представляет собой набор инструментов для работы с итераторами, которые могут значительно ускорить обработку больших данных. Например, использование `itertools.chain` для объединения нескольких коллекций позволяет избежать создания промежуточных списков и сократить время работы кода. Также стоит обратить внимание на функции `itertools.combinations` и `itertools.permutations`, которые оптимизированы для генерации сочетаний и перестановок без создания всех возможных вариантов в памяти.
Функции из `functools`, такие как `lru_cache`, помогают ускорить повторные вызовы функции, кешируя результаты. Это особенно полезно для рекурсивных функций или функций с высокими затратами на вычисления. Использование кэширования позволяет снизить время выполнения за счет сокращения числа вычислений для одинаковых входных данных.
Для работы с многозадачностью и параллельными вычислениями стоит обратить внимание на библиотеку `concurrent.futures`. Она позволяет легко распараллелить задачи с помощью потоков или процессов. Например, использование `ThreadPoolExecutor` или `ProcessPoolExecutor` для параллельного выполнения функции на нескольких ядрах процессора может значительно ускорить выполнение ресурсоемких задач, таких как обработка больших файлов или сетевых запросов.
Оптимизированные алгоритмы и структуры данных, предоставляемые стандартной библиотекой Python, позволяют значительно улучшить производительность кода, избегая ненужных операций и снижая избыточность. Применение этих библиотек позволяет не только ускорить выполнение, но и улучшить читаемость и поддерживаемость кода.
Применение многозадачности с помощью многопоточности и multiprocessing

В Python для ускорения выполнения программ можно использовать многозадачность, которая достигается через многопоточность или использование модуля multiprocessing. Оба подхода направлены на оптимизацию параллельных вычислений, но имеют разные механизмы и области применения.
Для задач, связанных с вычислениями, многопоточность не дает значительных улучшений производительности из-за GIL. В таких случаях лучше использовать multiprocessing, который создает отдельные процессы, каждый из которых имеет свой собственный GIL, что позволяет использовать многозадачность для тяжелых вычислительных задач.
Multiprocessing – это решение для параллельных вычислений, обеспечивающее полное использование многозадачности через отдельные процессы. Модуль multiprocessing позволяет эффективно распределять задачи между несколькими ядрами процессора. Преимущество этого подхода – способность Python запускать несколько процессов одновременно, что особенно важно для операций, требующих интенсивных вычислений (например, обработка больших массивов данных, машинное обучение, обработка изображений и видео).
Основные различия между threading и multiprocessing заключаются в том, что в многопоточном приложении потоки используют один и тот же адрес памяти, а в многозадачности с multiprocessing каждый процесс работает в своем собственном адресном пространстве. Это позволяет избежать проблем, связанных с синхронизацией потоков, но в то же время требует больше системных ресурсов для управления процессами.
Важный момент при использовании multiprocessing – это необходимость обмена данными между процессами. Для этого используются очереди Queue или каналы Pipe, которые обеспечивают безопасный обмен информацией между процессами. Однако передача данных между процессами может быть медленной из-за необходимости копирования данных между отдельными адресами памяти.
При использовании multiprocessing для параллельных вычислений рекомендуется обращать внимание на количество процессов. Обычно оптимальное число процессов – это количество физических ядер процессора. Вы можете узнать количество доступных ядер с помощью метода os.cpu_count().
Как улучшить работу с большими данными через генераторы и итераторы
Генераторы создаются с помощью выражений, использующих ключевое слово yield, и позволяют итерационно возвращать значения. В отличие от обычных функций, которые возвращают все значения сразу, генераторы возвращают их по одному, что значительно снижает потребление памяти. Пример:
def read_large_file(file_path): with open(file_path) as f: for line in f: yield line.strip()
В этом примере функция read_large_file не загружает весь файл в память, а возвращает строки по мере чтения, что значительно ускоряет обработку файлов большого размера.
Для обработки данных с помощью итераторов, Python предоставляет встроенные инструменты, такие как iter() и next(). Итератор позволяет итерировать по коллекции, не загружая её целиком в память. Пример использования:
data = range(1000000) iterator = iter(data) for i in range(10): print(next(iterator))
Этот подход полезен, когда требуется обрабатывать данные, не зная их полной длины заранее, например, при обработке потоков данных или данных, получаемых из внешних источников.
Для ускорения работы с большими объемами данных можно комбинировать генераторы и различные инструменты Python. Например, использование itertools.chain для объединения нескольких генераторов:
import itertools gen1 = (x for x in range(100)) gen2 = (x for x in range(100, 200)) combined = itertools.chain(gen1, gen2) for value in combined: print(value)
Этот способ позволяет эффективно объединять несколько источников данных, не увеличивая потребление памяти.
Кроме того, важно помнить, что генераторы и итераторы особенно полезны в многозадачных приложениях, где важно минимизировать блокировки. Генераторы могут использоваться в асинхронных приложениях с помощью async def и await, что дает возможность создавать асинхронные генераторы для работы с большими данными, не блокируя основной поток.
Использование этих механизмов может значительно повысить производительность при работе с большими объемами данных, снизить нагрузку на память и ускорить обработку в реальном времени.
Использование компиляции в Cython для повышения скорости исполнения
Первым шагом является установка Cython. Это можно сделать через pip:
pip install cython
Основная идея использования Cython заключается в том, чтобы превратить наиболее производительные части кода в C-расширения. Например, если у вас есть цикл или интенсивная математическая операция, можно переписать её с использованием Cython для повышения скорости. Cython позволяет явно указывать типы переменных, что способствует оптимизации работы с памятью и вычислениями.
Вот пример кода Python, который можно ускорить с помощью Cython:
# python_code.py def sum_of_squares(n): result = 0 for i in range(n): result += i * i return result
Этот код можно переписать в Cython с указанием типов данных для переменных:
# cython_code.pyx def sum_of_squares(int n): cdef int result = 0 cdef int i for i in range(n): result += i * i return result
Для компиляции Cython-кода необходимо создать файл setup.py с настройками компиляции:
from Cython.Build import cythonize
from setuptools import setup
setup(
ext_modules=cythonize("cython_code.pyx")
)
Затем следует запустить команду для компиляции:
python setup.py build_ext --inplace
После компиляции появляется скомпилированный файл, который можно импортировать и использовать как обычный Python-модуль. Это значительно ускорит выполнение функции по сравнению с исходным кодом на чистом Python.
Cython позволяет не только улучшить производительность за счет компиляции в C, но и интегрировать Python с другими языками, такими как C или C++, а также использовать библиотеки, написанные на этих языках. Для более глубоких оптимизаций можно использовать Cython для работы с массивами через библиотеку NumPy, что делает её идеальной для научных вычислений.
При разработке с использованием Cython стоит помнить, что лучше компилировать только те части кода, которые действительно нуждаются в оптимизации. Чрезмерное использование Cython может привести к излишнему усложнению кода, что затруднит его поддержку. Однако для критичных участков, где важна скорость, использование Cython оправдано и приносит ощутимые результаты.
Профилирование и анализ узких мест в приложении Python
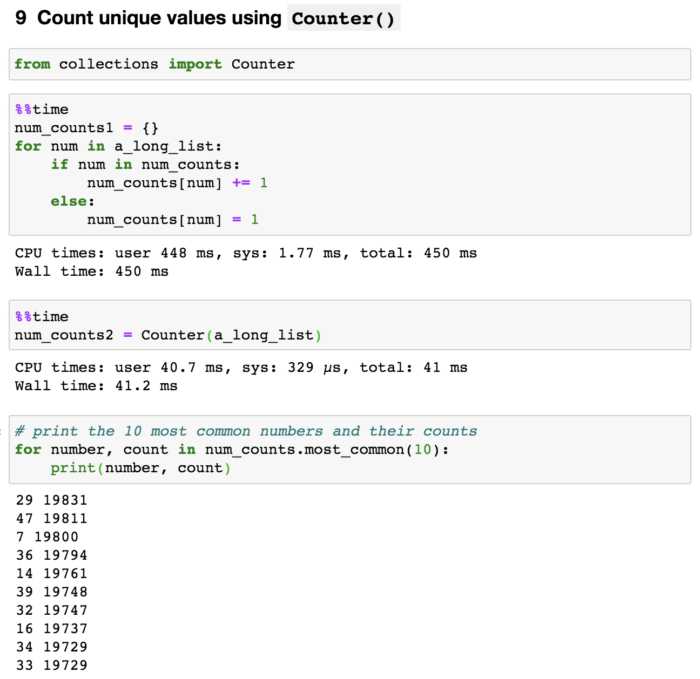
Основные инструменты профилирования:
- cProfile – стандартный модуль, который позволяет отслеживать, сколько времени тратится на выполнение каждой функции в программе. Он подходит для больших приложений и может легко интегрироваться в существующий код.
- profile – аналог cProfile, но с меньшей производительностью, используется в основном для более детализированного анализа.
- timeit – инструмент для точного измерения времени выполнения небольших фрагментов кода. Идеален для сравнительного анализа разных реализаций одного алгоритма.
- line_profiler – расширение для Python, которое профилирует выполнение на уровне строк, позволяя выявить проблемы производительности в конкретных строках кода.
Пример использования cProfile:
import cProfile
def my_function():
# Код, который нужно профилировать
pass
cProfile.run('my_function()')
Результат выполнения даст информацию о времени, которое тратится на выполнение каждой функции, включая количество вызовов и время выполнения каждой функции.
После того как вы получите информацию о времени выполнения функций, важно оценить, где находятся основные проблемы производительности:
- Частые вызовы функций – иногда функция вызывает другие функции с большим количеством операций, что может замедлить выполнение. Определив такие вызовы, можно попытаться их оптимизировать или избежать.
- Низкая эффективность алгоритмов – если алгоритм использует слишком сложные операции или некорректно обрабатывает данные, это может быть причиной замедления работы программы.
- Многократные обращения к внешним ресурсам – например, частые запросы к базе данных или файловой системе могут значительно замедлить работу приложения. Использование кэширования или асинхронных подходов может ускорить выполнение.
Для диагностики работы с памятью полезно использовать модуль memory_profiler, который позволяет отслеживать потребление памяти в реальном времени. Это помогает выявить утечки памяти или чрезмерное использование ресурсов в определённых частях приложения.
Важно учитывать, что профилирование может добавить нагрузку на приложение, поэтому его нужно использовать в условиях, максимально приближенных к рабочим, а не в тестовой среде с минимальной нагрузкой.
После профилирования необходимо выполнить анализ полученных данных и разработать стратегию оптимизации. Основные подходы к улучшению производительности:
- Оптимизация алгоритмов – использование более быстрых структур данных, уменьшение сложности операций.
- Параллелизация вычислений с использованием многозадачности или многопоточности, если это возможно.
- Использование кэширования для хранения результатов часто выполняемых операций.
- Использование сторонних библиотек, написанных на C или C++, для выполнения вычислительно сложных операций (например, NumPy).
Профилирование и анализ узких мест позволяют значительно улучшить производительность Python-приложений, выявив и устранив ключевые проблемы.
Вопрос-ответ:
Какие способы ускорения Python существуют для повышения производительности в многозадачных приложениях?
Для повышения производительности многозадачных приложений на Python можно использовать несколько подходов. Во-первых, стоит обратить внимание на многопоточность и многозадачность. Хотя Python использует Global Interpreter Lock (GIL), позволяющий работать только одному потоку с интерпретатором, можно воспользоваться модулями, как `concurrent.futures` или `threading` для задач, которые не требуют интенсивных вычислений. Для вычислительных задач рекомендуется использовать многопроцессность с помощью модуля `multiprocessing`, так как каждый процесс будет иметь свой собственный интерпретатор Python и не будет ограничен GIL. Также можно попробовать использовать асинхронное программирование с библиотеками `asyncio`, которое эффективно работает при необходимости ожидания внешних ресурсов, таких как запросы к базе данных или сети.
Как можно ускорить Python код, если он работает с большими объемами данных?
Для работы с большими объемами данных важно оптимизировать как использование памяти, так и скорость обработки. Использование встроенных структур данных Python, таких как списки и словари, может быть недостаточно эффективно для больших объемов. В таких случаях стоит рассмотреть библиотеки, такие как `numpy` и `pandas`, которые оптимизированы для работы с массивами данных и поддерживают операции на уровне C. Также можно использовать модуль `array` для хранения данных в более компактном виде. Для эффективной работы с большими файлами, можно использовать потоковую обработку данных, загружая и обрабатывая их частями, а не целиком. Кроме того, стоит обратить внимание на использование кэширования, например, с помощью библиотеки `functools.lru_cache` для хранения результатов часто вызываемых функций.
Как улучшить производительность Python при выполнении математических операций?
Для ускорения выполнения математических операций в Python стоит использовать специализированные библиотеки, такие как `numpy` и `scipy`. Эти библиотеки оптимизированы для работы с числовыми данными и используют эффективные алгоритмы, а также написаны на C, что позволяет значительно ускорить выполнение операций по сравнению с чисто Python-реализациями. В некоторых случаях полезно использовать типы данных, которые занимают меньше памяти, например, `float32` вместо `float64`. Еще один способ — это параллельная обработка с помощью библиотеки `multiprocessing` или модулей, поддерживающих GPU-вычисления, таких как `cupy` для ускорения выполнения математических операций на графических процессорах.
Что делать, если Python код использует слишком много памяти?
Если ваш Python код использует слишком много памяти, стоит начать с анализа структуры данных, которые вы используете. Например, списки и словари могут быть менее эффективными по сравнению с массивами `numpy` или специализированными структурами данных из `collections` (например, `deque` или `defaultdict`). Также рекомендуется использовать генераторы вместо списков для работы с большими наборами данных, так как генераторы загружают в память только один элемент за раз. Для работы с большими файлами лучше использовать обработку данных в потоковом режиме с помощью библиотеки `io` или `itertools`. Еще одним способом оптимизации памяти является использование библиотеки `memory_profiler`, которая позволяет мониторить использование памяти во время выполнения программы и помогает выявить участки кода, которые требуют оптимизации.
Как можно ускорить Python код при работе с базами данных?
При работе с базами данных для ускорения выполнения запросов в Python полезно использовать несколько техник. Во-первых, стоит оптимизировать сами SQL-запросы, избегая излишних вложенных запросов и операций, которые требуют больших затрат времени. Для работы с базами данных можно использовать такие библиотеки, как `SQLAlchemy`, которая позволяет работать с базой данных на более высоком уровне, или `psycopg2` для работы с PostgreSQL, которая предоставляет прямой доступ к базе данных и может быть быстрее в некоторых случаях. Если запросы выполняются часто, полезно использовать кэширование, например, с помощью библиотеки `redis` или `memcached`. Еще одним важным моментом является использование асинхронных библиотек, таких как `asyncpg`, которые могут значительно ускорить работу с базой данных, если необходимо обрабатывать несколько запросов одновременно.