В Python есть несколько способов подсчета количества вхождений элемента в список. Этот процесс может быть полезен при анализе данных или при обработке больших объемов информации. Один из наиболее прямолинейных и эффективных методов – использование встроенного метода count(), который позволяет получить количество появлений указанного элемента в списке.
Метод count() является частью стандартной библиотеки Python и имеет следующий синтаксис: список.count(элемент). Он возвращает количество раз, которое элемент встречается в списке, или 0, если элемент не найден. Этот способ работает за время O(n), где n – это длина списка, что делает его достаточно быстрым для большинства задач.
Если требуется подсчитать вхождения нескольких различных элементов или выполнить более сложный анализ, можно использовать цикл for или библиотеку collections. Например, для подсчета вхождений всех элементов в списке эффективным способом будет использование Counter из модуля collections, который создает словарь, где ключами являются элементы списка, а значениями – количество их вхождений. Этот подход полезен при анализе больших объемов данных, поскольку его время работы составляет O(n).
В некоторых случаях, например, при обработке списка с данными, содержащими вложенные структуры, может потребоваться рекурсивное решение или использование более сложных алгоритмов для подсчета вхождений. Однако для большинства задач стандартный метод count() или использование Counter будет самым быстрым и простым решением.
Использование метода count() для подсчета вхождений элемента
Метод count() в Python позволяет быстро подсчитать количество вхождений элемента в список. Он принимает один аргумент – элемент, количество которого необходимо определить. Важно помнить, что метод count() возвращает целое число, которое показывает, сколько раз указанный элемент встречается в списке.
Пример использования метода:
my_list = [1, 2, 3, 1, 4, 1]
count_ones = my_list.count(1)
В данном примере метод count(1) вернет число 3, так как элемент 1 встречается в списке трижды.
Метод count() не изменяет сам список и является полезным инструментом для быстрых подсчетов. Он также учитывает только точные совпадения. Например, если в списке встречаются строки с разными регистрами, метод не будет считать их одинаковыми элементами.
Метод можно использовать с любыми типами данных, находящимися в списке: числами, строками, объектами или даже вложенными структурами данных. Например, для подсчета вхождений строки:
words = ['apple', 'banana', 'apple', 'orange']
count_apples = words.count('apple')
В случае с вложенными списками count() не будет учитывать элементы в них как отдельные элементы. Например, метод не посчитает элементы внутри вложенных списков:
nested_list = [1, [2, 3], 1, [2, 3], 1]
count_ones = nested_list.count(1)
Важно помнить, что метод count() имеет сложность O(n), где n – длина списка. Это значит, что для очень больших списков подсчет может занять значительное время.
Метод count() удобен, когда необходимо подсчитать количество вхождений конкретного элемента в списке без необходимости вручную писать цикл. Однако для более сложных случаев (например, если нужно подсчитать вхождения по определенным условиям или работать с большими данными) могут быть полезны другие методы, такие как использование библиотеки collections.Counter.
Как посчитать количество вхождений с условием: фильтрация значений
Для подсчета количества вхождений элемента в список с учётом фильтрации значений можно использовать несколько подходов. Применяя условия фильтрации, мы можем ограничить поиск только для тех элементов, которые соответствуют заданным критериям.
Рассмотрим основные способы фильтрации и подсчета вхождений:
- Использование функции
filter() и len().
- Использование генераторов списков с условием.
- Использование
collections.Counter с предварительным фильтром.
Пример 1: filter() и len()
Функция filter() позволяет фильтровать элементы списка по заданному условию. Для подсчета подходящих элементов применяем функцию len().
data = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
condition = lambda x: x % 2 == 0 # Условие: только чётные числа
filtered_data = filter(condition, data)
count = len(list(filtered_data))
print(count) # Выведет: 5
В этом примере мы фильтруем только чётные числа и считаем их количество.
Пример 2: Генераторы списков
Генераторы списков предоставляют удобный способ для создания нового списка с элементами, удовлетворяющими условию. Для подсчета вхождений можно сразу применить функцию sum().
data = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
count = sum(1 for x in data if x % 2 == 0)
print(count) # Выведет: 5
Здесь мы используем генератор для подсчёта чётных чисел. В отличие от filter(), данный подход более компактный.
Пример 3: collections.Counter с фильтрацией
Если требуется посчитать не просто количество вхождений, но и анализировать статистику по нескольким значениям, можно использовать модуль collections.Counter. Для этого нужно сначала отфильтровать элементы, а затем применить Counter.
from collections import Counter
data = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
filtered_data = [x for x in data if x % 2 == 0]
counter = Counter(filtered_data)
print(counter) # Выведет: Counter({2: 1, 4: 1, 6: 1, 8: 1, 10: 1})
Здесь мы сначала фильтруем список чётных чисел, а затем создаём объект Counter для анализа их вхождений.
Такой метод полезен, если необходимо учитывать не только количество вхождений, но и видеть, сколько раз каждое число встречается в списке.
Фильтрация значений даёт возможность гибко подходить к решению задачи подсчета вхождений. Выбор метода зависит от сложности задачи и предпочтений в написании кода.
Подсчет количества вхождений элементов в списке с помощью циклов

Пример использования цикла for для подсчета количества вхождений элемента в списке:
lst = [1, 2, 3, 2, 4, 2, 5]
element = 2
count = 0
for item in lst:
if item == element:
count += 1
print(count)
В данном примере цикл проходит по каждому элементу списка и увеличивает счетчик count, если элемент равен искомому. Этот метод работает с любыми типами данных в списке, будь то числа, строки или другие объекты.
Также можно использовать цикл while, если нужно реализовать более гибкий контроль над процессом перебора. В этом случае счетчик увеличивается только при выполнении определенного условия.
Пример с использованием цикла while:
lst = [1, 2, 3, 2, 4, 2, 5]
element = 2
count = 0
i = 0
while i < len(lst):
if lst[i] == element:
count += 1
i += 1
print(count)
Этот метод может быть полезен, если необходимо предусмотреть дополнительные проверки или манипуляции с индексом.
Важно отметить, что такие подходы, как правило, имеют временную сложность O(n), где n – количество элементов в списке. Это означает, что время работы программы пропорционально размеру списка.
Если нужно подсчитать вхождения сразу нескольких разных элементов, можно использовать цикл for в сочетании с условными операторами и словарем для хранения результатов подсчета.
Пример подсчета вхождений нескольких элементов:
lst = [1, 2, 2, 3, 4, 2, 5, 3, 1]
count_dict = {}
for item in lst:
if item in count_dict:
count_dict[item] += 1
else:
count_dict[item] = 1
print(count_dict)
Этот подход позволяет эффективно подсчитывать количество вхождений для всех элементов списка и хранить результаты в виде словаря.
Как найти количество вхождений нескольких элементов в списке
Пример использования Counter:
from collections import Counter
my_list = ['apple', 'banana', 'apple', 'orange', 'banana', 'apple']
counter = Counter(my_list)
# Получаем количество вхождений каждого элемента
print(counter)
Этот код выведет словарь, где ключами будут элементы списка, а значениями – их частота появления. Например, {'apple': 3, 'banana': 2, 'orange': 1}.
Чтобы получить количество вхождений нескольких элементов, можно обратиться к нужным ключам:
elements_to_count = ['apple', 'banana']
for element in elements_to_count:
print(f"{element}: {counter[element]}")
Если элемент не найден в списке, Counter вернет значение 0 по умолчанию.
Альтернативным способом может быть использование метода list.count() для каждого элемента списка. Однако это решение менее эффективно, так как требует несколько обходов списка для каждого элемента. Пример:
my_list = ['apple', 'banana', 'apple', 'orange', 'banana', 'apple']
elements_to_count = ['apple', 'banana']
for element in elements_to_count:
print(f"{element}: {my_list.count(element)}")
Этот способ подойдет для небольших списков, но на больших объемах данных будет значительно медленнее, так как для каждого элемента выполняется обход всего списка.
Если необходимо учитывать вхождения элементов в различных частях списка или учитывать условие фильтрации (например, только элементы, начинающиеся с буквы "a"), можно использовать генераторы и фильтрацию:
my_list = ['apple', 'banana', 'apricot', 'orange', 'avocado']
filtered_list = [item for item in my_list if item.startswith('a')]
counter = Counter(filtered_list)
print(counter)
Таким образом, для нахождения количества вхождений нескольких элементов в списке важно выбирать метод в зависимости от размера данных и специфики задачи. Для больших списков лучше использовать Counter, а для малых – метод count().
Использование коллекций Counter для подсчета элементов списка

Модуль collections в Python предоставляет удобную структуру данных Counter, которая позволяет эффективно подсчитывать количество вхождений элементов в коллекцию. Для работы с ним достаточно передать список или другую итерируемую структуру данных в конструктор Counter.
Пример использования:
from collections import Counter
список = [1, 2, 2, 3, 3, 3, 4, 4, 4, 4]
счетчик = Counter(список)
print(счетчик)
Counter({4: 4, 3: 3, 2: 2, 1: 1})
Counter также поддерживает доступ к количеству конкретного элемента через его ключ. Например, чтобы узнать, сколько раз встречается цифра 3, можно сделать следующее:
Если элемент отсутствует в списке, то при попытке обратиться к нему через индекс будет возвращено значение 0:
Для получения самых частых элементов можно воспользоваться методом most_common. Он возвращает список кортежей, где каждый кортеж состоит из элемента и его частоты. Например, чтобы получить два самых часто встречающихся элемента:
Таким образом, Counter предоставляет простой и быстрый способ подсчета элементов, который подходит для большинства задач, связанных с анализом данных и частотным анализом.
Как учитывать регистр при подсчете вхождений строк

При подсчете строк в списке важно учитывать, различаются ли строки только регистром. В Python строка "Python" не равна "python", если не применять методы нормализации регистра.
- Чтобы строго учитывать регистр, используйте метод
list.count() без преобразования регистра:
words = ["Python", "python", "PYTHON"]
count = words.count("Python") # Результат: 1
- Если необходимо отличать все варианты написания, используйте
collections.Counter для точного подсчета:
from collections import Counter
words = ["Python", "python", "PYTHON", "Python"]
counter = Counter(words)
print(counter["Python"]) # Результат: 2
print(counter["python"]) # Результат: 1
- Если нужно различать все уникальные строки с учетом регистра, примените
set() и list.count() по каждой строке:
unique_words = set(words)
counts = {word: words.count(word) for word in unique_words}
Для исключения регистра из подсчета используйте метод str.lower() или str.upper() перед подсчетом. Но если важна чувствительность к регистру, любое изменение регистра запрещено.
Что делать, если элемент не найден в списке: обработка исключений

В Python метод list.index() вызывает исключение ValueError, если указанный элемент отсутствует в списке. Чтобы избежать прерывания выполнения программы, используйте конструкцию try–except.
Пример:
список = [1, 2, 3, 4, 5]
try:
индекс = список.index(10)
except ValueError:
индекс = -1
Если важно не только избежать ошибки, но и обработать ситуацию отсутствия элемента, задайте значение по умолчанию или выполните альтернативную логику внутри блока except.
Альтернатива без try–except – проверка наличия элемента через in:
если 10 in список:
индекс = список.index(10)
else:
индекс = -1
Для подсчёта количества вхождений используйте list.count(), который возвращает 0 при отсутствии элемента, без исключений. Это предпочтительно, если задача не требует точного индекса.
Использование try–except оправдано, если необходимо найти первую позицию элемента, но он может отсутствовать. Не перехватывайте исключение без обработки – это затрудняет отладку и снижает читаемость.
Как посчитать вхождения с учетом вложенных списков и объектов
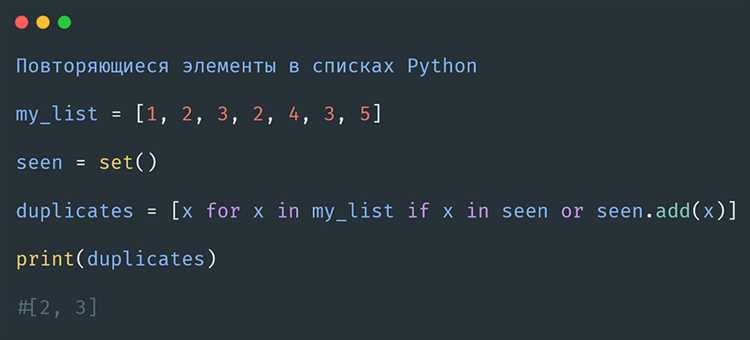
Пример решения задачи с вложенными списками:
def count_occurrences(lst, target):
count = 0
for item in lst:
if isinstance(item, list): # Если элемент – список, рекурсивно вызываем функцию
count += count_occurrences(item, target)
else:
count += item == target # Проверяем, равен ли элемент целевому значению
return count
Этот код эффективно считает вхождения искомого элемента в списке, даже если он вложен в другие списки. Используя проверку isinstance(item, list), функция понимает, что если элемент является списком, нужно вызвать функцию для поиска внутри этого списка.
Для более сложных структур данных, например, для объектов, где необходимо учитывать атрибуты, можно изменить функцию так, чтобы она проверяла атрибуты объектов. Рассмотрим пример, где объекты имеют разные атрибуты, и мы ищем вхождения по значению атрибута:
class Item:
def __init__(self, value):
self.value = value
def count_occurrences(lst, target):
count = 0
for item in lst:
if isinstance(item, list):
count += count_occurrences(item, target)
elif isinstance(item, Item): # Если элемент – объект, проверяем атрибут
count += item.value == target
else:
count += item == target
return count
Этот подход позволяет учитывать как вложенные структуры данных, так и объекты, что делает код гибким для использования в более сложных случаях.
Важно помнить, что при работе с вложенными структурами важно тщательно обрабатывать каждый тип данных. Вложенные словари или другие коллекции могут потребовать дополнительных проверок и модификаций функции, чтобы точно посчитать все вхождения элемента.
Вопрос-ответ:
Как посчитать, сколько раз определенный элемент встречается в списке в Python?
В Python для подсчета количества вхождений элемента в список можно использовать метод `count()`. Например, если у вас есть список `my_list = [1, 2, 3, 2, 4, 2]` и нужно подсчитать, сколько раз в нем встречается число `2`, можно написать так: `my_list.count(2)`. Этот метод возвращает количество вхождений элемента в список.