В языке Python для работы с массивами (или списками) часто возникает необходимость устранить дублирующиеся элементы. Это важно не только для экономии памяти, но и для упрощения обработки данных. В Python существует несколько методов удаления дубликатов, каждый из которых имеет свои особенности и может быть применен в зависимости от ситуации.
Основной способ – использовать структуру данных set, которая по своей природе не позволяет хранить одинаковые элементы. Преобразование списка в set удаляет все дубликаты, но при этом порядок элементов теряется. Чтобы сохранить порядок, можно воспользоваться специальными подходами, такими как использование OrderedDict из модуля collections.
Другим вариантом является использование генераторов списков для фильтрации элементов. Этот метод позволяет контролировать процесс удаления дубликатов и при этом сохранить нужный порядок. Он особенно полезен, когда нужно учитывать более сложные условия фильтрации или изменения данных перед удалением дубликатов.
Как удалить дубликаты с помощью set() в Python

Пример удаления дубликатов из списка с использованием set():
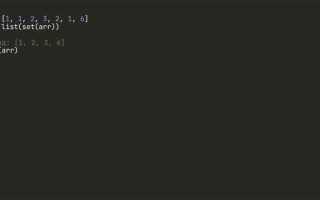
numbers = [1, 2, 3, 3, 4, 5, 5]
unique_numbers = set(numbers)
В результате выполнения этого кода дубликаты 3 и 5 будут удалены, так как множество хранит только уникальные элементы.
Важно учитывать, что множества в Python не сохраняют порядок элементов. Если вам нужно сохранить порядок, можно воспользоваться функцией list(), преобразовав результат обратно в список:
ordered_unique_numbers = list(set(numbers))
print(ordered_unique_numbers) # Порядок может измениться
Для сохранения оригинального порядка элементов, при удалении дубликатов, можно использовать подход с циклом и дополнительной проверкой, например:
unique_numbers_ordered = []
for number in numbers:
if number not in unique_numbers_ordered:
unique_numbers_ordered.append(number)
Этот метод сохраняет порядок элементов в исходном списке и при этом удаляет дубликаты. С использованием set() же можно быстро избавиться от дубликатов, но не всегда гарантирован сохранение порядка.
Использование list comprehension для удаления повторяющихся элементов
Чтобы избавиться от повторяющихся элементов, можно использовать list comprehension в сочетании с множеством (set) для проверки наличия уже добавленных элементов. Множество автоматически исключает дубликаты, и таким образом достигается требуемый результат.
Пример удаления дубликатов с сохранением порядка:
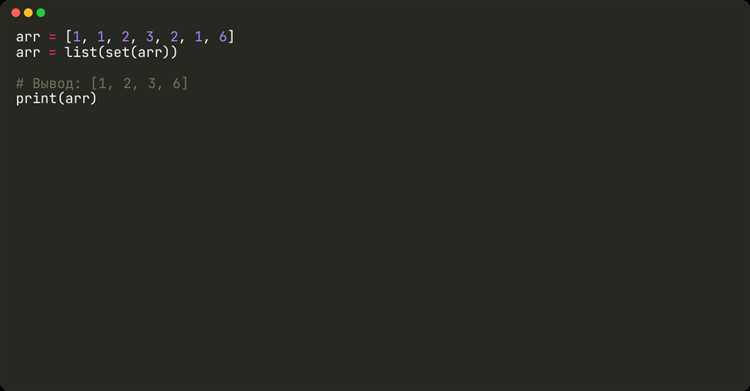
original_list = [1, 2, 2, 3, 4, 4, 5]
unique_list = []
[unique_list.append(x) for x in original_list if x not in unique_list]Здесь создается пустой список unique_list, куда добавляются элементы из original_list только если они ещё не присутствуют в unique_list. Это решение сохраняет порядок элементов в исходном списке.
Более компактное решение можно получить, если использовать множество для отслеживания уже встречавшихся элементов:
original_list = [1, 2, 2, 3, 4, 4, 5]
seen = set()
unique_list = [x for x in original_list if not (x in seen or seen.add(x))]В этом примере множество seen используется для хранения элементов, которые уже добавлены в unique_list. Выражение x in seen or seen.add(x) проверяет, был ли элемент в множестве, и если нет, добавляет его в список и в множество. Это решение не только эффективно, но и компактно.
Использование list comprehension для удаления дубликатов повышает читаемость кода и позволяет быстро обрабатывать массивы, не прибегая к дополнительным операциям, таким как сортировка или преобразование в множество.
Метод distinct() в pandas: как это работает с массивами
В библиотеке pandas отсутствует метод distinct() в явном виде. Для удаления дубликатов используется drop_duplicates(). Однако, при работе с массивами через pandas.Series или pandas.DataFrame он выполняет ту же функцию, что и distinct() в SQL или PySpark.
- Чтобы удалить повторяющиеся элементы в одномерном массиве, достаточно обернуть его в
Seriesи применитьdrop_duplicates():import pandas as pd data = [1, 2, 2, 3, 4, 4, 4] unique_values = pd.Series(data).drop_duplicates().tolist() - Если требуется сохранить порядок появления элементов,
drop_duplicates()справляется без дополнительных аргументов. Для изменения порядка – сортировка после фильтрации:unique_sorted = pd.Series(data).drop_duplicates().sort_values().tolist() - Для двумерных массивов (
DataFrame) дубликаты удаляются по всем столбцам:df = pd.DataFrame([[1, 2], [1, 2], [2, 3]]) unique_rows = df.drop_duplicates() - Удаление дубликатов по конкретным столбцам:
df.drop_duplicates(subset=[0]) - Если важен только первый или последний экземпляр, параметр
keepпринимает значения'first','last'илиFalse:df.drop_duplicates(keep='last')
drop_duplicates() работает быстрее, если типы данных однородны и отсутствуют пропущенные значения. Для массивов с вложенными структурами (например, списки в ячейках) потребуется предварительное преобразование к хешируемому типу.
Удаление дубликатов с сохранением порядка элементов

Чтобы удалить дубликаты и сохранить порядок, используют комбинацию множества и списка. Множество обеспечивает уникальность, список – исходную последовательность.
Пример на основе цикла:
def remove_duplicates(seq):
seen = set()
result = []
for item in seq:
if item not in seen:
seen.add(item)
result.append(item)
return result
Этот способ работает для любых хэшируемых объектов, включая числа, строки, кортежи. Время выполнения – O(n), где n – длина исходного массива. В отличие от преобразования в set, здесь порядок не нарушается.
Если требуется работать с неизменяемыми входными данными, можно использовать генераторное выражение и объект OrderedDict:
from collections import OrderedDict
def remove_duplicates(seq):
return list(OrderedDict.fromkeys(seq))
Метод fromkeys сохраняет только первые вхождения ключей, игнорируя повторяющиеся. Это короче, но применимо только к хэшируемым типам.
Для списков с вложенными структурами, например списков списков, потребуется другой подход – сериализация или преобразование во что-то хэшируемое. Например:
def remove_duplicates_nested(seq):
seen = set()
result = []
for item in seq:
key = tuple(item)
if key not in seen:
seen.add(key)
result.append(item)
return result
Если элементы не приводятся к хэшируемому виду, можно использовать список для хранения уже встреченных элементов и сравнивать поэлементно, но это снижает производительность до O(n²).
Как обрабатывать дубликаты в больших массивах с помощью itertools
Модуль itertools предоставляет инструменты для итеративной обработки, позволяющие работать с большими массивами без необходимости загружать всё в память. Для удаления дубликатов полезна функция groupby, которая группирует последовательные одинаковые элементы.
Перед использованием groupby данные необходимо отсортировать, иначе одинаковые элементы не окажутся рядом, и группировка будет некорректной. Пример:
from itertools import groupby
data = sorted(очень_большой_массив)
уникальные = [k for k, _ in groupby(data)]
Этот способ подходит, когда важен низкий расход памяти. groupby обрабатывает элементы по одному, не создавая дополнительных копий массива.
Если необходимо не только удалить дубликаты, но и посчитать количество вхождений, можно использовать генератор внутри словаря:
from itertools import groupby
data = sorted(большой_массив)
подсчёт = {k: len(list(g)) for k, g in groupby(data)}
Для работы с отсортированными потоками данных, например при чтении из файла построчно, groupby позволяет избежать полной загрузки в память:
with open('data.txt') as f:
for key, group in groupby(sorted(line.strip() for line in f)):
print(key)
Если сортировка слишком затратна, а массив уже отсортирован, groupby позволяет избавиться от повторов без лишних операций. При этом важно, чтобы сортировка соответствовала логике сравнения.
Реализация удаления дубликатов без использования дополнительных библиотек

Для удаления дубликатов без сторонних модулей можно использовать базовые конструкции языка. Один из вариантов – проход по массиву с добавлением уникальных элементов в новый список.
def remove_duplicates(arr):
result = []
for item in arr:
if item not in result:
result.append(item)
return result
Этот метод сохраняет порядок элементов. Временная сложность – O(n²) из-за проверки вхождения в список. При работе с небольшими массивами он подходит, но при росте объёма данных производительность резко снижается.
Более быстрый способ – использовать словарь, так как операции с ключами выполняются за O(1). С версии Python 3.7 словари сохраняют порядок добавления элементов, поэтому порядок исходного массива сохраняется.
def remove_duplicates(arr):
return list(dict.fromkeys(arr))
Этот подход работает в O(n) и не требует подключения модулей. Он эффективен при больших объёмах данных и минимален по количеству строк.
Для модификации массива на месте можно использовать цикл и удаление повторов через pop(). Это снижает читаемость и увеличивает сложность, но экономит память:
def remove_duplicates_in_place(arr):
i = 0
seen = []
while i < len(arr):
if arr[i] in seen:
arr.pop(i)
else:
seen.append(arr[i])
i += 1
Этот способ менее эффективен, но может быть полезен, если требуется сохранить оригинальный список без создания копий.
Оптимизация удаления дубликатов для массивов с числовыми значениями
При работе с массивами чисел наибольшую производительность обеспечивает использование встроенных структур данных, таких как множества и словари. Выбор подхода зависит от требований к порядку элементов и допустимого объёма памяти.
- Если порядок элементов не имеет значения, оптимален способ через преобразование в множество:
list(set(numbers)). Время выполнения – O(n), но порядок будет потерян. - Для сохранения порядка используется конструкция с
dict.fromkeys():list(dict.fromkeys(numbers)). Порядок сохраняется, также работает за O(n). - При больших объёмах данных и частом повторении значений экономнее использовать
collections.Counterтолько при необходимости узнать частоту. Для удаления дубликатов этот метод избыточен.
Если массив отсортирован, дубликаты удаляются быстрее:
def remove_duplicates_sorted(arr):
if not arr:
return []
result = [arr[0]]
for num in arr[1:]:
if num != result[-1]:
result.append(num)
return result
- Время – O(n), память – O(n) в худшем случае.
- Работает только с предварительно отсортированными данными.
Для массивов, содержащих только целые числа в ограниченном диапазоне, возможно использование булевого массива (битовой карты):
def remove_duplicates_bitmask(arr, max_value):
seen = [False] * (max_value + 1)
result = []
for num in arr:
if not seen[num]:
seen[num] = True
result.append(num)
return result
- Работает за O(n), требует O(m) памяти, где m – максимальное значение в массиве.
- Подходит, если значения находятся в известном ограниченном диапазоне.
Выбор метода определяется ограничениями: необходимостью сохранить порядок, допустимым объёмом памяти и диапазоном значений.
Как работать с массивами, содержащими кортежи и другие сложные структуры
При удалении дубликатов из массива, содержащего кортежи, важно учитывать их хешируемость. Кортежи, содержащие только неизменяемые объекты, можно напрямую преобразовать в множество: unique = list(set(data)). Если в кортеже есть изменяемые объекты (например, списки), возникнет ошибка TypeError.
Для структур, содержащих вложенные списки, применяют преобразование в хешируемую форму. Один из вариантов – сериализация. Пример: json.dumps позволяет превратить объект в строку, пригодную для сравнения:
import json
data = [(1, [2, 3]), (1, [2, 3]), (4, [5])]
seen = set()
result = []
for item in data:
marker = json.dumps(item, sort_keys=True)
if marker not in seen:
seen.add(marker)
result.append(item)
Если кортежи содержат объекты пользовательских классов, нужно определить метод __hash__ и __eq__ в этих классах. Без этого корректное сравнение невозможно, и set не будет работать.
Для вложенных структур можно также использовать рекурсивное преобразование к хешируемым типам. Пример функции:
def make_hashable(obj):
if isinstance(obj, (list, tuple)):
return tuple(make_hashable(e) for e in obj)
if isinstance(obj, dict):
return tuple(sorted((k, make_hashable(v)) for k, v in obj.items()))
return obj
data = [(1, [2, 3]), (1, [2, 3]), (4, [5])]
unique = list({make_hashable(i): i for i in data}.values())
Для массивов, включающих словари, применяют заморозку ключей и значений. Пример: frozenset(d.items()) делает словарь пригодным для использования в множестве. Это работает только при неизменяемых значениях внутри словаря.
Если структура включает нестабильные элементы (временные метки, id), необходимо заранее исключить их из сравнения. Это можно сделать через фильтрацию ключей перед сериализацией или хешированием.