При работе с массивами в Python часто возникает необходимость уменьшить их размерность, особенно когда данные обладают высокими признаками или когда нужно ускорить обработку информации. Наиболее популярным инструментом для таких задач являются библиотеки NumPy и scikit-learn, которые предоставляют множество методов для эффективного преобразования данных.
Если массив имеет несколько измерений, а задача заключается в уменьшении этих измерений, можно использовать операции, такие как преобразование с использованием метода PCA (Principal Component Analysis), что позволяет сохранить важную информацию и избавиться от избыточных данных. PCA анализирует взаимосвязи между признаками и преобразует исходные данные в пространство меньшей размерности, минимизируя потери.
Для выполнения этого шага в Python достаточно применить метод fit_transform() из библиотеки scikit-learn, который автоматически вычислит нужные компоненты для уменьшения размерности. При этом важно контролировать процент объяснённой дисперсии, чтобы избежать потери значимой информации. Например, чтобы сохранить 95% информации, можно указать соответствующий порог в методе PCA.
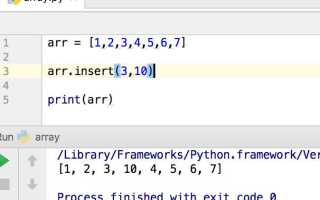
Также существуют более простые методы, такие как использование reshape() в NumPy, который позволяет изменить размерность массива, но сохраняет все данные. Однако важно помнить, что такая операция лишь перестроит массив без сокращения числа признаков, а не уменьшит размерность с точки зрения информации.
Использование метода reshape библиотеки NumPy

Метод `reshape` в библиотеке NumPy позволяет изменять форму массива без изменения его данных. Это полезно, когда требуется преобразовать одномерный массив в многомерный или наоборот, при этом сохранится порядок элементов. Для использования метода достаточно передать новый размер, соответствующий числу элементов в исходном массиве.
Пример использования метода:
import numpy as np
arr = np.arange(12)
reshaped_arr = arr.reshape(3, 4)
print(reshaped_arr)В данном примере исходный массив с 12 элементами преобразуется в двумерный массив размером 3×4. Если размерность, указанная в параметре `reshape`, не соответствует числу элементов в исходном массиве, метод вызовет ошибку.
Метод `reshape` работает по принципу ‘по строкам’. Если необходимо использовать другой порядок, можно воспользоваться параметром `order`. Например, при значении `order=’F’` элементы будут заполняться по столбцам, что полезно для работы с данными, имеющими специфическую структуру.
arr.reshape(3, 4, order='F')Важно помнить, что `reshape` не копирует данные, а лишь изменяет представление массива, что делает операцию быстрой и экономной по памяти. Это означает, что если в исходном массиве изменяются данные, то они отразятся и в reshaped массиве.
Если необходимо создать новую копию массива с изменённой формой, следует использовать метод `reshape` в сочетании с `copy()`. Это позволит избежать изменений в исходном массиве.
new_array = arr.reshape(3, 4).copy()Метод `reshape` также полезен при подготовке данных для машинного обучения, например, для преобразования данных в нужную форму перед обучением модели.
Сжатие многомерных массивов с помощью метода squeeze()

Основные моменты работы с методом squeeze():
- Удаляет все размерности, равные 1.
- Не изменяет массив, если в нем нет размерностей, равных 1.
- Не влияет на данные массива – только изменяет его форму.
Пример использования метода:
import numpy as np arr = np.array([[[1], [2]], [[3], [4]]]) print(arr.shape) # (2, 2, 1) arr_squeezed = arr.squeeze() print(arr_squeezed.shape) # (2, 2)
В данном примере массив arr имеет форму (2, 2, 1). После применения метода squeeze() размерность, равная 1, была удалена, и массив стал размером (2, 2).
Дополнительно, squeeze() принимает аргумент axis, который позволяет указать конкретную размерность для удаления. Если размерность в указанном axis равна 1, она будет удалена. В противном случае метод вернет массив без изменений.
Пример с использованием axis:
arr = np.array([[[1], [2]], [[3], [4]]]) arr_squeezed = arr.squeeze(axis=2) print(arr_squeezed.shape) # (2, 2)
Здесь метод удаляет только третью размерность, так как она равна 1, и результатом будет массив с формой (2, 2).
Этот метод полезен для обработки массивов, полученных из операций, где добавление лишних размерностей может быть нежелательным. Например, при загрузке данных из файлов или после выполнения некоторых математических операций, таких как добавление дополнительного измерения для расширения диапазона данных.
Применение метода flatten() для преобразования массива в одномерный
Метод flatten() в Python используется для преобразования многомерных массивов в одномерные. Он полезен при работе с массивами, которые имеют более одной оси, например, с матрицами или многомерными списками. Этот метод эффективно упрощает данные для последующей обработки или анализа.
Обычно flatten() применяется к объектам типа numpy.ndarray. После его вызова массив, вне зависимости от своей исходной формы, преобразуется в одномерный, где все элементы оказываются в одном ряду. Например, многомерный массив с размерами (2, 3) будет преобразован в одномерный массив из 6 элементов.
Пример использования:
import numpy as np
array = np.array([[1, 2, 3], [4, 5, 6]])
flattened_array = array.flatten()
print(flattened_array)
Результат: [1 2 3 4 5 6]
Метод flatten() возвращает новый массив, и его использование не изменяет исходный. Это важно учитывать, если необходимо сохранить оригинальную структуру данных. В отличие от метода ravel(), который может вернуть представление массива, а не его копию, flatten() всегда возвращает новый объект.
Когда необходимо преобразовать многомерные данные для простого анализа, например, при обработке изображений или работая с большими массивами данных, использование flatten() позволяет уменьшить сложность работы с данными. Однако, стоит помнить, что превращение массива в одномерный может привести к потере контекста многомерной структуры, что важно учитывать при дальнейших вычислениях.
Извлечение подмассивов с использованием индексации и срезов
Для получения отдельного элемента массива используется индексация. В Python индексация начинается с нуля. Например, если есть массив arr = [10, 20, 30, 40], доступ к элементу с индексом 2 можно получить так: arr[2], что вернёт 30.
Срезы позволяют извлекать подмассивы, задавая диапазон индексов. Синтаксис среза выглядит следующим образом: arr[start:end]. Здесь start – индекс начала среза, end – индекс, до которого будет извлечён подмассив (не включая сам индекс end). Например, для массива arr = [10, 20, 30, 40, 50], срез arr[1:4] вернёт подмассив [20, 30, 40].
Для более гибкой работы с срезами можно использовать третий параметр – шаг. Например, срез arr[::2] извлечёт каждый второй элемент из массива. Если arr = [10, 20, 30, 40, 50], результатом будет [10, 30, 50].
Важно помнить, что если индекс начала среза превышает длину массива, Python вернёт пустой список. Также, если индекс конца выходит за пределы, Python просто извлечёт элементы до конца массива. Например, arr[1:10] для массива [10, 20, 30] вернёт [20, 30].
Индексация и срезы могут быть использованы и с многоуровневыми массивами, такими как списки списков. Например, если arr = [[1, 2], [3, 4], [5, 6]], то arr[1] вернёт подмассив [3, 4], а срез arr[0:2] даст [[1, 2], [3, 4]].
Для извлечения подмассивов без изменений исходных данных можно использовать копирование срезов. Например, subarray = arr[start:end][:] создаст копию подмассива, не затрагивая исходный массив.
Преобразование массивов с помощью функции np.newaxis
Функция np.newaxis используется для добавления новой оси в массив, что позволяет изменять его размерность без копирования данных. Это полезно при необходимости преобразования одномерного массива в двумерный или многомерный. В отличие от стандартных методов изменения формы, np.newaxis позволяет гибко манипулировать размерностью, не создавая дополнительные копии данных.
При применении np.newaxis к существующему массиву, создается представление с добавленной осью. Например, если у нас есть одномерный массив, добавление новой оси преобразует его в двумерный.
import numpy as np
# Одномерный массив
arr = np.array([1, 2, 3, 4])
# Преобразование в двумерный массив
arr_2d = arr[:, np.newaxis]
print(arr_2d)
В результате, исходный одномерный массив [1, 2, 3, 4] превращается в двумерный массив размером (4, 1).
Еще один пример: добавление новой оси в начало массива для создания нового измерения.
arr_2d_start = arr[np.newaxis, :]
print(arr_2d_start)
Теперь массив имеет размерность (1, 4), где добавлена новая ось в начале.
Применение np.newaxis особенно удобно при работе с операциями, требующими согласования размерности массивов, например, при многомерных вычислениях или при применении операций, где массивы должны иметь одинаковое количество осей. Это часто встречается в задачах машинного обучения, обработке изображений или анализе данных.
Удаление лишних осей с помощью метода np.squeeze()

Метод np.squeeze() используется для удаления осей, размер которых равен 1, из массива NumPy. Это полезно, когда нужно привести массив к более компактному виду, избавившись от несущественных осей. Рассмотрим его использование на практике.
Пример использования метода:
import numpy as np
arr = np.random.rand(1, 3, 1, 5)
print(arr.shape) # (1, 3, 1, 5)
squeezed_arr = np.squeeze(arr)
print(squeezed_arr.shape) # (3, 5)
Метод squeeze() по умолчанию удаляет все оси, размер которых равен 1. Это полезно, например, после операций, возвращающих массивы с избыточными размерами.
Кроме того, можно передать аргумент axis, чтобы удалить оси только по конкретному индексу:
squeezed_arr = np.squeeze(arr, axis=0)
print(squeezed_arr.shape) # (3, 1, 5)
- Если размер оси не равен 1, метод вызовет ошибку.
- Метод возвращает новый массив, не изменяя исходный.
- Для удаления нескольких осей можно несколько раз применить
squeeze()с разными значениями аргументаaxis.
Важно помнить, что удаление осей с размером 1 не всегда подходит, особенно если вы хотите сохранить исходную структуру данных. В таких случаях можно использовать другие методы, например, np.reshape(), для гибкости в работе с размерностью массива.
Использование PCA для уменьшения размерности данных
PCA преобразует исходные данные в новые координаты, где каждая ось (главная компонента) указывает в направлении наибольшей дисперсии данных. Обычно выбираются только первые несколько компонент, которые объясняют большую часть дисперсии, что и позволяет снизить размерность.
Процесс применения PCA включает несколько ключевых этапов:
- Стандартизация данных: PCA чувствителен к масштабу признаков. Поэтому необходимо привести все переменные к одному масштабу, например, с помощью стандартизации (вычитание среднего и деление на стандартное отклонение).
- Вычисление ковариационной матрицы: На основе стандартизированных данных рассчитывается ковариационная матрица, которая помогает определить взаимосвязь между признаками.
- Собственные значения и собственные векторы: Из ковариационной матрицы извлекаются собственные значения и собственные векторы. Эти векторы соответствуют главным компонентам, а собственные значения показывают важность каждой компоненты.
- Выбор главных компонент: Обычно выбираются первые несколько компонент, которые объясняют наибольшую часть дисперсии. Количество компонент зависит от желаемого уровня сохранения информации.
- Преобразование данных: Исходные данные проецируются на выбранные компоненты, создавая новый набор признаков с уменьшенной размерностью.
Чтобы использовать PCA в Python, достаточно библиотеки sklearn. Пример кода:
from sklearn.decomposition import PCA from sklearn.preprocessing import StandardScaler # Стандартизация данных scaler = StandardScaler() X_scaled = scaler.fit_transform(X) # Применение PCA pca = PCA(n_components=2) X_pca = pca.fit_transform(X_scaled) # Доля объясненной дисперсии print(pca.explained_variance_ratio_)
Важно отметить, что применение PCA не всегда оправдано. Если данные уже обладают низкой размерностью или важны все признаки, использование PCA может привести к потере информации. Поэтому стоит подходить к выбору метода с учетом конкретной задачи и характеристик данных.
Вопрос-ответ:
Что такое уменьшение размерности массива в Python и зачем это нужно?
Уменьшение размерности массива (или редукция размерности) — это процесс преобразования многомерного массива в массив с меньшей размерностью. Это необходимо, когда требуется уменьшить сложность анализа данных, ускорить вычисления или улучшить визуализацию. Примеры таких методов включают использование техник, как главные компоненты (PCA) или линейное подпространство.
Какие библиотеки Python можно использовать для уменьшения размерности массивов?
В Python для уменьшения размерности массивов наиболее популярны библиотеки NumPy, Scikit-learn и TensorFlow. Например, в Scikit-learn можно использовать метод PCA для применения метода главных компонент. NumPy предоставляет базовые функции для работы с массивами и их преобразованием, а TensorFlow помогает с уменьшением размерности в контексте глубокого обучения.
Какие преимущества имеет уменьшение размерности для анализа данных?
Уменьшение размерности помогает улучшить интерпретацию данных, снизить вычислительную нагрузку и уменьшить вероятность переобучения модели. Это особенно полезно при работе с большими наборами данных, когда важно не потерять основные характеристики, но уменьшить число переменных для более эффективного анализа или моделирования.
Какие еще методы уменьшения размерности существуют в Python?
Помимо PCA, существует несколько других методов уменьшения размерности. Например, t-SNE (t-distributed Stochastic Neighbor Embedding) и методы на основе автоэнкодеров. t-SNE хорош для визуализации, когда нужно представить данные в 2D или 3D. Автоэнкодеры используются в глубоких нейронных сетях для уменьшения размерности с сохранением важной информации. Также часто применяются методы, такие как LDA (Линейный дискриминантный анализ) и NMF (Non-negative Matrix Factorization).