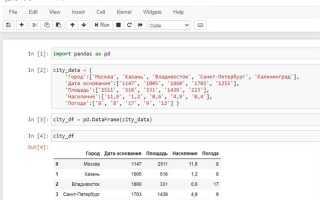
При работе с данными в Python с использованием библиотеки pandas часто возникает необходимость в переименовании столбцов в DataFrame. Это может быть полезно, когда названия столбцов не соответствуют требованиям анализа или обработки данных, или когда требуется привести их к единому стилю. Переименование столбцов позволяет улучшить читаемость и упрощает дальнейшую работу с данными.
Для переименования столбцов в DataFrame существует несколько эффективных методов. Один из самых простых способов – использовать метод rename(), который позволяет изменить название столбцов, указав старое и новое имя в виде словаря. Этот метод изменяет столбцы на лету, не требуя изменения самой структуры данных.
Важно помнить, что переименование столбцов в pandas не всегда подразумевает полное изменение всех имен. В некоторых случаях имеет смысл изменять только несколько столбцов, что можно легко реализовать через аргумент columns. Однако, при работе с большими наборами данных, важно правильно планировать переименование, чтобы избежать конфликтов и ошибок в дальнейшем.
Также стоит отметить, что в pandas есть возможность не только переименовывать столбцы, но и изменять их порядок, что может быть полезно для представления данных в удобном для пользователя виде. Все эти операции помогают сделать работу с DataFrame более гибкой и удобной для дальнейшего анализа данных.
Переименование столбцов с использованием метода rename()
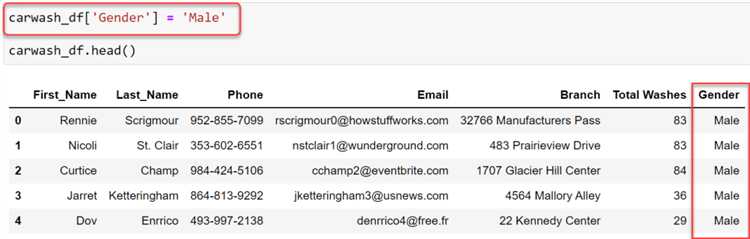
Метод rename() в pandas позволяет гибко изменять имена столбцов в DataFrame. Для использования метода нужно передать словарь, где ключами будут старые имена столбцов, а значениями – новые. Такой подход удобен, когда необходимо переименовать лишь несколько столбцов, не изменяя остальные.
Пример синтаксиса:
df.rename(columns={'старое_имя': 'новое_имя'}, inplace=True)
При передаче аргумента inplace=True изменения будут выполнены непосредственно в исходном DataFrame, без создания нового объекта. Если не указывать inplace, метод вернет новый DataFrame с измененными именами столбцов.
Пример с несколькими столбцами:
df.rename(columns={'старый_столбец1': 'новый_столбец1', 'старый_столбец2': 'новый_столбец2'}, inplace=True)
Стоит помнить, что при использовании rename() не нужно заботиться о порядке столбцов. Порядок в DataFrame сохраняется, а переименования происходят только по указанным ключам. Однако важно учитывать, что метод не заменяет имена столбцов, не указанные в словаре, поэтому не стоит ожидать изменений для других столбцов.
Если столбец имеет несколько слов, можно использовать символы подчеркивания для улучшения читаемости. Например, «Название_столбца» можно заменить на «название_столбца».
Как переименовать несколько столбцов одновременно
Пример кода:
import pandas as pd
Создаем DataFrame
df = pd.DataFrame({
'old_name1': [1, 2, 3],
'old_name2': [4, 5, 6],
'old_name3': [7, 8, 9]
})
Переименовываем несколько столбцов
df = df.rename(columns={'old_name1': 'new_name1', 'old_name2': 'new_name2'})
print(df)В приведенном примере столбцы с именами ‘old_name1’ и ‘old_name2’ переименованы в ‘new_name1’ и ‘new_name2’. Столбец ‘old_name3’ остался без изменений.
Важно помнить, что метод rename() возвращает новый DataFrame, в то время как оригинальный DataFrame остается без изменений, если не указано inplace=True. Если нужно изменить DataFrame на месте, можно сделать так:
df.rename(columns={'old_name1': 'new_name1', 'old_name2': 'new_name2'}, inplace=True)Этот подход эффективен, когда необходимо быстро внести несколько изменений в структуру данных без лишних шагов.
Рекомендация: Если имена столбцов должны следовать определенному шаблону или быть преобразованы с помощью какой-либо логики, можно использовать методы, такие как map() или str.replace() для более сложных преобразований. Например, если нужно добавить суффикс ко всем столбцам:
df.columns = df.columns + '_new'Такой метод полезен для массового изменения имен, когда нет необходимости в специфической замене каждого столбца вручную.
Использование атрибута columns для изменения названий столбцов

Атрибут `columns` в pandas позволяет быстро изменить имена столбцов в DataFrame, предоставляя простой способ для переименования. Он возвращает объект типа Index, представляющий текущие имена столбцов, что даёт возможность присвоить новый список или массив значений для их изменения.
Для изменения имен столбцов достаточно присвоить атрибуту `columns` новый список строк, соответствующий количеству столбцов в DataFrame. Например:
import pandas as pd
# Исходный DataFrame
df = pd.DataFrame({
'A': [1, 2, 3],
'B': [4, 5, 6]
})
# Изменение имен столбцов
df.columns = ['X', 'Y']
print(df)
Этот код заменяет имена столбцов на ‘X’ и ‘Y’. Важно, чтобы количество новых имен соответствовало количеству существующих столбцов, иначе возникнет ошибка. Также рекомендуется использовать осмысленные и уникальные имена, чтобы облегчить дальнейшую работу с данными.
Если необходимо изменить только часть имен столбцов, можно воспользоваться методом `str.replace` или применить более сложные операции с помощью выражений для изменения только определённых столбцов. Например:
df.columns = df.columns.str.replace('A', 'Alpha')
print(df)
Этот подход удобен, когда необходимо провести массовое переименование столбцов по определённому шаблону.
Помимо простого присваивания новых имен, можно комбинировать `columns` с другими методами pandas для более сложных операций, таких как преобразование всех имён в нижний регистр:
df.columns = df.columns.str.lower() print(df)
Использование атрибута `columns` позволяет гибко и быстро адаптировать DataFrame под нужды анализа, сохраняя высокую читаемость и понятность кода.
Что делать, если столбцы имеют одинаковые имена
Когда в DataFrame встречаются столбцы с одинаковыми именами, это может привести к путанице при обращении к данным и создании анализов. Для корректной работы с такими данными необходимо предпринять несколько шагов для решения проблемы.
- Переименовать столбцы вручную. Если столбцы с одинаковыми именами находятся в разных контекстах, можно явно присвоить каждому уникальное имя. Используйте метод
rename()или прямое изменение атрибутаcolumns, чтобы избежать дублирования. - Проверить наличие дубликатов. Перед обработкой данных полезно проверить, сколько столбцов с одинаковыми именами в DataFrame. Это можно сделать, применив метод
duplicated()илиvalue_counts()для индексов столбцов. - Использовать числовые индексы. В случае, если столбцы действительно должны иметь одинаковые имена по какой-либо причине, можно изменить их на уникальные имена с добавлением индексов. Например,
'column_1', 'column_2', чтобы каждый столбец оставался узнаваемым, но не конфликтовал с другими. - Удалить лишние столбцы. Иногда наличие одинаковых столбцов не имеет смысла. В таком случае можно просто удалить дублирующиеся столбцы с помощью
drop(), оставив только один с нужным именем. - Использовать методы агрегирования. Если дублирование столбцов произошло в результате повторяющихся данных, можно агрегировать информацию, например, с помощью
groupby()илиagg(), чтобы сохранить нужную информацию без дублирования столбцов.
Применяя эти методы, можно эффективно устранить проблему одинаковых имен столбцов в DataFrame, что значительно упростит дальнейшую работу с данными и их анализ.
Переименование столбцов с учётом чувствительности к регистру
Когда требуется изменить названия столбцов в DataFrame, важно учитывать чувствительность к регистру, особенно если названия содержат одинаковые символы в разных регистрах. В Python библиотека pandas позволяет легко работать с данными, но по умолчанию переименование столбцов не различает регистр. Если необходимо строго сохранить регистр, стоит учитывать некоторые особенности.
Для переименования столбцов с учётом чувствительности к регистру можно использовать метод rename(), который позволяет задавать конкретные замены. Например:
df.rename(columns={'oldColumnName': 'NewColumnName'}, inplace=True)Этот метод не будет игнорировать разницу в регистрах и изменит название столбца только в том случае, если оно точно совпадает с оригиналом по регистру. Если столбцы имеют одинаковые имена, но с разными регистрами, важно гарантировать, что указанные в словаре замены имена также учитывают этот факт.
В случае необходимости массового переименования столбцов, где важно не только изменить название, но и сохранить точный регистр, можно использовать следующий подход:
df.columns = [col.upper() if col == 'target' else col.lower() for col in df.columns]Этот код изменит регистр столбца ‘target’ на верхний, оставив другие без изменений. Метод str.upper() и str.lower() являются полезными для манипуляций с регистром, но они также могут быть использованы с учетом чувствительности.
В некоторых случаях полезно перед переименованием столбцов создать их копии с преобразованным регистром для сравнения. Это позволяет избежать случайных ошибок при редактировании данных, где одинаковые столбцы могут иметь разный регистр, что делает их идентификацию более сложной. Например:
df.columns = [col.lower() for col in df.columns]Это приведет все столбцы к одному регистру, и дальше можно будет использовать метод rename() для замены нужных элементов.
Рекомендуется всегда проверять регистр столбцов перед проведением массовых изменений, особенно если исходные данные могут содержать нестандартное форматирование или быть получены из различных источников с разными стандартами именования.
Автоматическое переименование столбцов с помощью list comprehension
Использование list comprehension позволяет эффективно переименовывать столбцы в DataFrame, особенно когда нужно внести изменения по определенному шаблону. Вместо явного перебора столбцов с помощью циклов, можно воспользоваться компактной и читаемой конструкцией list comprehension.
Для начала, предположим, что у нас есть DataFrame с определенными столбцами, например, с пробелами в названиях или с нечитаемыми символами. Чтобы привести их к более удобочитаемому виду, можно воспользоваться следующим методом:
import pandas as pd
# Создаем DataFrame
df = pd.DataFrame({
'First Name': [ 'Alice', 'Bob', 'Charlie'],
'Last Name': ['Smith', 'Jones', 'Brown']
})
# Преобразуем названия столбцов: удалим пробелы и приведем к нижнему регистру
df.columns = [col.replace(' ', '_').lower() for col in df.columns]
print(df)В приведенном примере с помощью list comprehension мы заменяем пробелы на символы подчеркивания и приводим все названия столбцов к нижнему регистру. Это позволяет упростить работу с данными, делая названия столбцов более стандартными для дальнейших операций.
Данный способ особенно полезен при работе с большими наборами данных, где наименование столбцов может содержать различные пробелы, символы или другие нестандартные элементы. List comprehension позволяет избежать многократного обращения к каждому столбцу через цикл и повышает читаемость кода.
Другим распространенным применением является добавление префиксов или суффиксов к столбцам. Например, если необходимо добавить суффикс «_new» ко всем столбцам, можно применить такой подход:
# Добавляем суффикс '_new' ко всем столбцам
df.columns = [col + '_new' for col in df.columns]
print(df)Таким образом, list comprehension дает возможность быстро и эффективно производить переименование столбцов с учетом различных требований, будь то изменение формата имен, добавление префиксов или использование других шаблонов.
Как изменить названия столбцов при загрузке данных из CSV

Для изменения названий столбцов при загрузке данных из CSV-файла в Pandas, можно использовать параметр `names` в функции `pd.read_csv()`. Это позволяет задать новые имена для столбцов непосредственно при загрузке данных, не изменяя их после загрузки.
Пример:
import pandas as pd
# Указание новых названий столбцов при загрузке CSV
df = pd.read_csv('data.csv', names=['Column1', 'Column2', 'Column3'])
Если CSV-файл уже содержит строки с заголовками, но вы хотите заменить их на другие, используйте параметр `header=0`, чтобы пропустить первую строку и применить новые имена столбцов:
df = pd.read_csv('data.csv', header=0, names=['NewCol1', 'NewCol2', 'NewCol3'])
Важно учитывать, что в случае использования параметра `names`, если CSV-файл имеет строки заголовков, они будут заменены новыми значениями, а исходные заголовки будут проигнорированы. В случае, если необходимо сохранить старые названия, можно сначала загрузить данные без указания параметра `names`, а затем переименовать столбцы вручную.
Пример изменения названий столбцов после загрузки:
df.columns = ['UpdatedCol1', 'UpdatedCol2', 'UpdatedCol3']
Этот способ гибкий и позволяет работать с данными, где названия столбцов заранее неизвестны или требуют корректировки в процессе загрузки.