Словари в Python – это мощный инструмент для хранения и обработки данных в виде пар «ключ-значение». Они позволяют эффективно работать с неупорядоченными коллекциями, где каждый элемент имеет уникальный идентификатор (ключ) и связанное с ним значение. Особенность словарей заключается в том, что доступ к данным осуществляется по ключу, что делает операции поиска и модификации быстрыми и удобными. В этой статье рассмотрим несколько практических примеров использования словарей в Python для решения различных задач.
1. Хранение и обработка данных с уникальными идентификаторами. Один из типичных примеров использования словарей – хранение информации о пользователях. Например, в веб-приложении можно использовать словарь для хранения данных о пользователях, где ключом будет служить уникальный ID пользователя, а значением – его профиль, состоящий из имени, адреса электронной почты и других данных.
Пример:
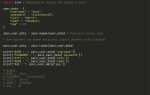
users = {'user_1': {'name': 'Иван', 'email': 'ivan@example.com'}, 'user_2': {'name': 'Мария', 'email': 'maria@example.com'}}
В данном случае, чтобы найти данные о пользователе, достаточно обратиться к словарю по ключу, например, users['user_1'], и получить профиль, ассоциированный с этим ID.
2. Подсчет частоты появления элементов. Еще одна распространенная задача, где применяются словари – это подсчет частоты элементов в коллекции. Например, можно использовать словарь для подсчета количества вхождений каждого слова в текст. В качестве ключей будут выступать сами слова, а значениями – их частоты.
Пример:
text = 'Python Python Java Python Java Java Python'
word_count = {word: text.split().count(word) for word in set(text.split())}
В данном примере словарь word_count будет содержать количество вхождений каждого слова в строке. Такая задача часто встречается при обработке текстов и анализе данных.
3. Оптимизация поиска с помощью словарей. Словари можно использовать для оптимизации алгоритмов поиска. Например, при реализации алгоритмов поиска пути или при анализе связей между объектами словарь может существенно ускорить выполнение программы. Сложность поиска по ключу в словаре составляет O(1), что делает его незаменимым инструментом в случае, когда требуется быстрый доступ к данным.
Пример:
graph = {'A': ['B', 'C'], 'B': ['A', 'D'], 'C': ['A', 'D'], 'D': ['B', 'C']}
visited = set()
def dfs(graph, node, visited):
if node not in visited:
visited.add(node)
for neighbor in graph[node]:
dfs(graph, neighbor, visited)
Здесь словарь graph используется для представления графа, а поиск в глубину (DFS) эффективно реализуется с помощью рекурсии и посещения каждой вершины через ключи словаря.
Словари в Python предлагают гибкость и скорость, которые позволяют решать широкий спектр задач в программировании, от обработки данных до реализации сложных алгоритмов. Важно учитывать особенности их использования для достижения максимальной эффективности в решении конкретных задач.
Создание словаря с помощью литералов
Литералы в Python позволяют создавать словари с использованием прямого синтаксиса. Это один из самых простых и распространённых способов объявления словарей. Литерал словаря представляет собой пару ключ-значение, разделённые двоеточием, а сами пары – запятой. Словарь создаётся, окружая пары фигурными скобками.
Пример создания словаря с литералом:
my_dict = {'name': 'Иван', 'age': 30, 'city': 'Москва'}
В этом примере ключами являются строки (‘name’, ‘age’, ‘city’), а значениями – ‘Иван’, 30 и ‘Москва’. Обратите внимание, что ключи могут быть любых неизменяемых типов (например, строки, числа или кортежи), а значения – любых типов данных, включая другие словари.
При создании словаря через литералы можно сразу задавать ключи и их значения. Это удобный и быстрый способ, если известно, что словарь будет иметь заранее определённые пары ключ-значение. Такой подход позволяет легко создавать словари без необходимости использовать методы добавления элементов.
Еще один пример, где значениями могут быть списки или другие словари:
user_info = {'name': 'Мария', 'contacts': {'email': 'maria@example.com', 'phone': '123-456'}}
Литералы также поддерживают создание пустых словарей. Чтобы создать пустой словарь, достаточно просто использовать пару фигурных скобок:
empty_dict = {}
Кроме того, при использовании литералов важно учитывать, что ключи в словаре должны быть уникальными. Если при создании словаря указать одинаковые ключи, то последний ключ перезапишет предыдущие значения:
duplicate_dict = {'name': 'Анна', 'name': 'Светлана'}
# результат: {'name': 'Светлана'}
Литералы словаря обеспечивают простоту и прозрачность в коде, что делает их идеальными для быстрого создания и инициализации словарей в Python.
Как добавить и удалить элементы из словаря
Для работы со словарями в Python важно знать, как добавлять и удалять элементы. Это позволяет эффективно изменять содержимое словаря во время выполнения программы.
Добавление элементов
Для добавления элемента в словарь используется простое присваивание значения ключу:
my_dict[key] = value- Если ключ уже существует в словаре, его значение будет обновлено.
- Если ключа нет, он будет создан с заданным значением.
Пример:
my_dict = {'a': 1, 'b': 2}
my_dict['c'] = 3 # Добавление нового элемента
print(my_dict) # {'a': 1, 'b': 2, 'c': 3}Удаление элементов
Для удаления элементов из словаря можно использовать несколько методов:
- del – удаляет элемент по ключу:
del my_dict['b']
print(my_dict) # {'a': 1, 'c': 3}Если ключ отсутствует в словаре, возникнет ошибка KeyError.
- pop() – удаляет элемент и возвращает его значение:
value = my_dict.pop('a')
print(value) # 1
print(my_dict) # {'c': 3}- Можно задать значение по умолчанию, которое будет возвращено, если ключ не найден:
value = my_dict.pop('d', 'default')
print(value) # default- popitem() – удаляет последний добавленный элемент:
item = my_dict.popitem()
print(item) # ('c', 3)
print(my_dict) # {} # словарь пустЭтот метод полезен, если нужно извлечь элементы в том порядке, в котором они были добавлены (с учетом версии Python 3.7 и выше).
- clear() – очищает весь словарь:
my_dict.clear()
print(my_dict) # {}Метод clear() удаляет все элементы словаря и делает его пустым.
Перебор ключей и значений в словаре с помощью циклов
Для эффективного перебора элементов словаря в Python обычно применяются циклы. Важно понимать, как правильно извлекать и использовать ключи и значения при помощи стандартных методов. Рассмотрим несколько распространённых способов перебора.
Первый способ – это перебор ключей словаря. Для этого можно использовать метод dict.keys(), который возвращает представление всех ключей в словаре.
example_dict = {'a': 1, 'b': 2, 'c': 3}
for key in example_dict.keys():
print(key)В результате цикла будут выведены все ключи: a, b, c.
Если необходимо одновременно обрабатывать как ключи, так и их соответствующие значения, используется метод dict.items(). Этот метод возвращает кортежи, состоящие из ключа и значения, что позволяет получить доступ к обеим частям элемента в одном цикле.
for key, value in example_dict.items():
print(f"Ключ: {key}, Значение: {value}")Это удобный способ, когда нужно провести обработку и ключей, и значений в одном цикле. Например, можно модифицировать значения, проверяя их с помощью условий:
for key, value in example_dict.items():
if value > 1:
example_dict[key] = value * 2
print(example_dict)Результатом будет обновлённый словарь с удвоенными значениями для элементов, где значение больше 1.
Если требуется перебрать только значения, можно использовать метод dict.values(), который возвращает все значения словаря. Этот метод подходит, когда нужно работать исключительно с данными без привязки к ключам.
for value in example_dict.values():
print(value)Для эффективного использования перебора также важно помнить о скорости выполнения. Цикл по dict.items() может быть несколько медленнее, чем по dict.keys() или dict.values(), если вам не нужно работать с обоими элементами словаря. Выбирайте метод в зависимости от ваших задач.
Использование метода get() для безопасного доступа к значениям
Метод get() словаря в Python позволяет безопасно извлекать значения по ключу, избегая ошибок, которые могут возникнуть при использовании прямого доступа через квадратные скобки. В отличие от обращения через dict[key], метод get() не вызывает исключение KeyError, если ключ отсутствует в словаре.
Основное преимущество использования get() заключается в том, что он позволяет задать значение по умолчанию для отсутствующего ключа. Например, если ключ не найден, метод вернет None, но при необходимости можно указать другое значение, которое будет возвращено в случае отсутствия ключа.
Пример использования метода:
my_dict = {'a': 1, 'b': 2}
Безопасный доступ к существующему ключу
value_a = my_dict.get('a') # Вернет 1
Попытка доступа к несуществующему ключу
value_c = my_dict.get('c') # Вернет None
Использование значения по умолчанию
value_d = my_dict.get('d', 'default') # Вернет 'default'
Это особенно полезно в ситуациях, когда невозможно заранее гарантировать наличие ключа в словаре, например, при обработке данных из внешних источников или при динамическом формировании ключей.
Кроме того, метод get() улучшает читаемость кода, избегая необходимости обрабатывать исключения вручную, что делает код компактным и более понятным.
Важно помнить, что метод get() следует использовать, когда поведение по умолчанию (например, None) или пользовательское значение имеет смысл в контексте задачи. Если ключ должен обязательно присутствовать в словаре, то прямой доступ через dict[key] с последующей обработкой исключения может быть более подходящим вариантом.
Вложенные словари: как работать с многослойными структурами
Пример структуры:
users = {
"alice": {"age": 30, "email": "alice@example.com", "active": True},
"bob": {"age": 25, "email": "bob@example.com", "active": False}
}
Для доступа к данным необходимо использовать цепочку ключей:
email_bob = users["bob"]["email"]
Чтобы избежать ошибки KeyError при обращении к несуществующему ключу, используйте метод get():
phone = users.get("alice", {}).get("phone")
Обход вложенного словаря осуществляется с помощью вложенных циклов:
for username, info in users.items():
for key, value in info.items():
print(f"{username} – {key}: {value}")
Для обновления вложенного значения:
users["alice"]["active"] = False
Добавление нового уровня вложенности:
users["charlie"] = {"age": 40, "email": "charlie@example.com", "active": True}
Удаление вложенного элемента:
del users["bob"]["email"]
Глубокое копирование вложенных словарей требует использования модуля copy:
import copy
users_copy = copy.deepcopy(users)
Для сериализации многослойных структур в строку применяйте модуль json:
import json
json_data = json.dumps(users)
Парсинг обратно:
parsed = json.loads(json_data)
Работа с вложенными словарями требует точности при обращении к ключам и знании структуры на каждом уровне.
Объединение словарей с помощью оператора обновления

Оператор обновления |= был добавлен в Python 3.9 и обеспечивает лаконичный способ объединения словарей. Он изменяет левый словарь, добавляя или перезаписывая пары ключ-значение из правого словаря.
data1 = {'a': 1, 'b': 2}
data2 = {'b': 3, 'c': 4}
data1 |= data2
print(data1) # {'a': 1, 'b': 3, 'c': 4}
Особенности оператора |=:
- Работает только со словарями. Передача других типов вызовет исключение
TypeError. - Ключи из второго словаря заменяют совпадающие ключи первого без предупреждений.
- Можно использовать в цепочке с другими операциями модификации словаря.
Рекомендации при использовании:
- Перед объединением убедитесь, что данные не содержат нежелательных пересечений ключей, если важно сохранить оригинальные значения.
- Для неизменяемого объединения используйте оператор
|, который возвращает новый словарь без модификации исходных. - Если требуется поддержка версий Python ниже 3.9, используйте метод
update(), так как оператор|=будет недоступен.
Оператор |= предпочтителен, когда необходимо кратко и читаемо обновить один словарь значениями другого без создания новой переменной.
Применение словарей для подсчета частоты элементов

Для подсчета частоты символов, слов или других элементов удобно использовать словари, где ключом выступает элемент, а значением – его количество. Это позволяет выполнять операцию за один проход по данным с амортизированной сложностью O(1) на обновление счётчика.
Пример подсчета количества букв в строке:
text = "анализ данных"
frequency = {}
for char in text:
if char in frequency:
frequency[char] += 1
else:
frequency[char] = 1
print(frequency)Результат: {‘а’: 2, ‘н’: 2, ‘а’: 2, ‘л’: 1, ‘и’: 1, ‘з’: 1, ‘ ‘: 1, ‘д’: 1, ‘н’: 2, ‘ы’: 1, ‘х’: 1}
Для ускорения разработки можно использовать collections.Counter, но вручную созданный словарь предоставляет полный контроль над логикой обработки. Например, можно легко фильтровать элементы с частотой выше заданного порога или сортировать по значению:
filtered = {k: v for k, v in frequency.items() if v > 1}
sorted_items = sorted(frequency.items(), key=lambda item: item[1], reverse=True)Такой подход применяется в задачах анализа текста, логов, голосований, когда необходимо быстро получить распределение по категориям. Обновление частоты не требует промежуточных структур и обеспечивает высокую производительность даже на больших объемах данных.