Для работы с файлами в Python существует несколько способов проверки их содержимого. Основной инструмент для этого – встроенная библиотека os и функции работы с файлами, такие как open() и read(). Однако важно правильно выбрать метод в зависимости от размера файла и целей проверки.
При работе с текстовыми файлами, прежде чем приступать к дальнейшей обработке, стоит убедиться в правильности их открытия и корректности содержимого. Для этого можно использовать функцию open(), которая позволяет открыть файл в различных режимах: на чтение, запись или добавление. Важно помнить, что для безопасного обращения с файлами, особенно с большими, лучше использовать конструкцию with, чтобы автоматически закрывать файл после завершения работы.
Когда дело касается проверки формата или структуры данных в файле, можно применить методы чтения по строкам. Это удобно для анализа небольших файлов или работы с логами. Для файлов больших размеров эффективнее будет использование буферизации, с чтением порциями данных. Функция readline() или цикл for для итерации по файлу позволяют аккуратно обрабатывать каждую строку и выполнять необходимые проверки.
В случае работы с бинарными файлами стоит использовать режим «rb», чтобы гарантировать правильную интерпретацию данных. Для анализа их содержимого можно воспользоваться модулями struct или binascii, которые помогут преобразовать байтовые данные в удобный для анализа формат. Для проверки содержимого таких файлов часто достаточно просто убедиться в их соответствии определенному формату с помощью регулярных выражений или кастомных функций обработки.
Обязательно проверяйте не только содержимое файла, но и его метаданные: размер, дата последней модификации. Это можно сделать с помощью модуля os, который позволяет получить информацию о файле без его открытия. Такой подход значительно увеличивает гибкость работы с файлами в реальных проектах.
Открытие файла и чтение его содержимого с помощью метода open()
В Python для работы с файлами используется встроенная функция open(), которая открывает файл и возвращает файловый объект. Она принимает два основных аргумента: путь к файлу и режим открытия. Режимы могут быть разными, в зависимости от того, что вы хотите сделать с файлом: читать, записывать или добавлять данные. Например, для чтения файла используется режим 'r', для записи – 'w', а для добавления данных – 'a'.
Пример открытия файла для чтения:
file = open('example.txt', 'r')После открытия файла с помощью open(), можно начать читать его содержимое. Для этого используются методы, такие как read(), readline() и readlines().
Метод read() считывает весь файл целиком и возвращает его содержимое в виде строки:
content = file.read()Метод readline() позволяет читать файл построчно. Он считывает одну строку за раз и возвращает её:
line = file.readline()Метод readlines() считывает все строки файла и возвращает их в виде списка строк:
lines = file.readlines()Не забудьте закрыть файл после завершения работы с ним, чтобы освободить ресурсы. Для этого используется метод close():
file.close()Также для правильного управления ресурсами рекомендуется использовать конструкцию with, которая автоматически закрывает файл после завершения работы:
with open('example.txt', 'r') as file:
content = file.read()Этот подход позволяет избежать ошибок, связанных с забыванием закрыть файл, и делает код более чистым и безопасным.
Проверка типа содержимого файла с использованием библиотеки os
Основным методом для проверки типа содержимого является os.path.splitext(), который разделяет путь к файлу на имя и расширение. Это расширение часто может дать представление о типе файла. Например, файлы с расширением .txt обычно содержат текст, а .jpg – изображения.
Пример использования os.path.splitext():
import os
file_path = "example.txt"
filename, file_extension = os.path.splitext(file_path)
print(f"Тип файла: {file_extension}")Этот код вернет .txt, что указывает на текстовый файл. Однако важно помнить, что расширение не всегда точно отражает содержимое файла, и для более надежной проверки типа содержимого стоит использовать другие методы.
Для получения более подробной информации о содержимом файла можно применить функцию os.stat(), которая возвращает метаданные о файле, включая его размер, время последнего доступа и модификации. Эти данные могут быть полезны для анализа, если вы хотите понять, когда файл был обновлен или насколько он велик, что также может подсказать его тип.
Пример использования os.stat():
import os
file_path = "example.txt"
file_stats = os.stat(file_path)
print(f"Размер файла: {file_stats.st_size} байт")Если же задача состоит в проверке, является ли файл исполнимым или доступен ли он для чтения/записи, можно использовать методы os.access() или os.path.isfile(), чтобы определить доступность и тип файла.
Пример использования os.access():
import os
file_path = "example.txt"
Проверка доступности для чтения
if os.access(file_path, os.R_OK):
print("Файл доступен для чтения.")
else:
print("Файл недоступен для чтения.") Таким образом, использование библиотеки os позволяет легко определить тип содержимого файла по его расширению, метаданным или доступности. Однако для точной проверки содержимого файла лучше использовать специализированные библиотеки, такие как magic или mimetypes.
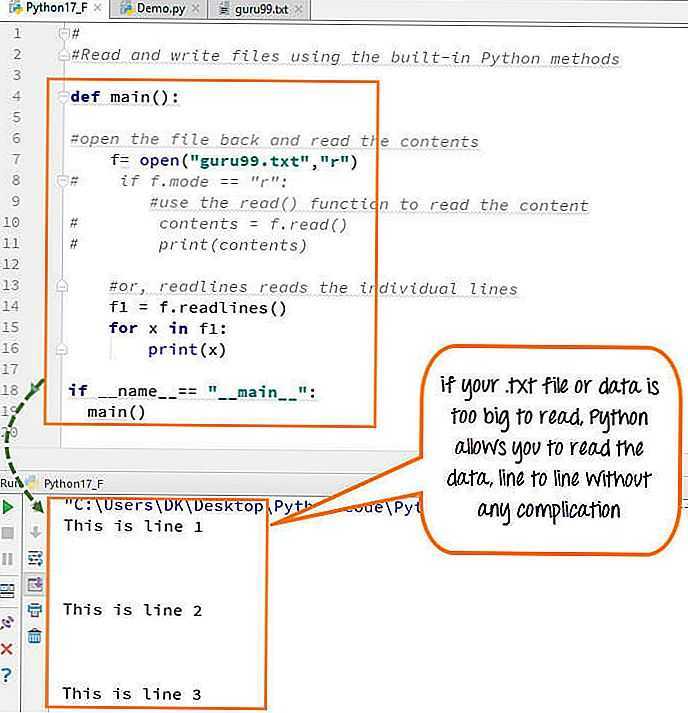
Чтение текстовых файлов построчно с использованием метода readlines()
Метод readlines() в Python позволяет читать содержимое текстового файла построчно. Этот метод возвращает список строк, где каждая строка представлена как элемент списка, включая символы новой строки. Это удобный способ для обработки файлов, размер которых позволяет загрузить их полностью в память.
Для использования readlines() откройте файл с помощью функции open(), затем вызовите метод на объекте файла. Пример:
with open('example.txt', 'r') as file:
lines = file.readlines()
В результате переменная lines будет содержать список всех строк из файла. Если файл большой, следует помнить, что чтение всех строк сразу может привести к избыточному использованию памяти. В таких случаях стоит рассмотреть построчное чтение с помощью цикла или метода readline().
Чтобы обработать строки без символов новой строки в конце, можно использовать метод strip():
with open('example.txt', 'r') as file:
lines = [line.strip() for line in file.readlines()]
Это удалит символы новой строки и пробелы в начале и в конце каждой строки. В случае работы с большими файлами рекомендуется использовать генераторы, чтобы не загружать весь файл в память сразу. Пример использования генератора:
def read_lines(file_path):
with open(file_path, 'r') as file:
for line in file:
yield line.strip()
Метод readlines() удобно использовать, когда нужно работать с небольшими файлами или когда весь файл можно загрузить в память. Для обработки очень больших файлов или потоковых данных лучше использовать другие подходы, такие как итерации по файлу в цикле или использование генераторов.
Как проверить наличие ошибок при чтении файла с помощью обработки исключений
При работе с файлами важно учитывать, что могут возникать различные ошибки, такие как отсутствие файла, проблемы с доступом или повреждение данных. Чтобы эффективно обработать такие ситуации, необходимо использовать обработку исключений в Python.
Для начала следует использовать конструкцию try-except, которая позволяет перехватывать ошибки, возникающие во время работы с файлом. Например, если файл не существует или у вас нет прав на его чтение, Python вызовет исключение FileNotFoundError или PermissionError. Эти исключения можно перехватить и обработать соответствующим образом.
Пример простого кода с обработкой ошибок:
try:
with open('example.txt', 'r') as file:
content = file.read()
except FileNotFoundError:
print("Файл не найден.")
except PermissionError:
print("Нет прав на чтение файла.")
except Exception as e:
print(f"Произошла ошибка: {e}")
В данном примере обработка ошибок позволяет точно определить, какая именно проблема возникла при попытке открыть файл. Также важно использовать блок except Exception, который позволит поймать все другие непредсказуемые ошибки, например, связанные с повреждением данных.
Не стоит забывать, что обработка ошибок делает программу более стабильной, а также предотвращает её неожиданные сбои при возникновении проблем с файлами. Правильная структура обработки исключений улучшает пользовательский опыт и помогает легче выявлять источники ошибок в коде.
Как работать с бинарными файлами в Python
Работа с бинарными файлами в Python требует специфического подхода, так как такие файлы содержат данные в формате, не предназначенном для чтения человеком. В Python для работы с бинарными файлами используется режим открытия файла ‘rb’ (чтение в бинарном формате) или ‘wb’ (запись в бинарном формате).
При открытии файла в бинарном режиме данные считываются или записываются как последовательность байтов. Это важно, так как операции с байтами отличаются от работы с текстовыми данными.
Чтение бинарных данных
Для чтения данных из бинарного файла используется метод read(), который считывает данные в виде байтов. Например:
with open('file.bin', 'rb') as f:
data = f.read()
print(data)Если файл большой, можно читать его частями, используя read(size), где size – это количество байтов, которое нужно считать:
with open('file.bin', 'rb') as f:
chunk = f.read(1024) # читаем 1 КБ за раз
while chunk:
print(chunk)
chunk = f.read(1024)Запись в бинарные файлы
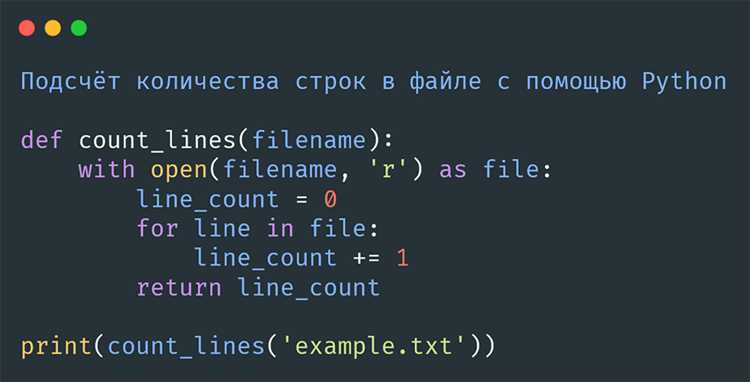
Для записи в бинарные файлы используется режим ‘wb’. Метод write() записывает переданные байты в файл:
data = b'\x01\x02\x03\x04'
with open('output.bin', 'wb') as f:
f.write(data)Важно, что передаваемые данные должны быть в виде байтов (тип bytes) или байтовой строки. Если нужно записать данные, которые не являются байтами (например, числа или строки), их нужно сначала преобразовать в байтовый формат.
Работа с числами и строками в бинарных файлах
Для работы с числами, строками и другими структурами данных в бинарных файлах удобно использовать модуль struct. Он позволяет упаковку и распаковку данных в и из бинарного формата.
- Для упаковки данных в бинарный формат используется функция
struct.pack(). Например:
import struct
packed_data = struct.pack('i', 123) # упаковываем целое число
with open('output.bin', 'wb') as f:
f.write(packed_data)- Для распаковки данных из бинарного формата используется
struct.unpack(). Например:
with open('output.bin', 'rb') as f:
data = f.read(4) # читаем 4 байта
unpacked_data = struct.unpack('i', data) # распаковываем целое число
print(unpacked_data[0])Чтение и запись больших данных
При работе с большими бинарными файлами рекомендуется использовать буферизацию для повышения производительности. Операции с большими файлами лучше выполнять по частям, чтобы избежать излишней загрузки памяти. Для этого используйте методы read(size) и write(data), передавая им данные небольшими частями.
Для эффективной работы с большими файлами можно использовать следующий подход:
def process_file(filename):
with open(filename, 'rb') as f:
while chunk := f.read(4096): # читаем 4 КБ за раз
# обработка данных
passТакой подход позволяет избежать блокировки памяти при работе с большими объемами данных.
Заключение

Работа с бинарными файлами в Python – это важный аспект при обработке форматов, таких как изображения, видео, аудио или другие специфические файлы. Знание режимов открытия файлов и методов работы с байтами, а также использование модуля struct для упаковки и распаковки данных обеспечит гибкость и эффективность при работе с бинарными данными.
Проверка кодировки текста в файле с использованием библиотеки chardet
Библиотека chardet позволяет автоматически определять кодировку текстовых файлов, что особенно полезно при работе с файлами, где кодировка заранее неизвестна или может быть нестандартной. Она поддерживает широкий спектр кодировок, включая UTF-8, Windows-1251, ISO-8859-1 и другие.
Для начала работы с chardet, нужно установить библиотеку с помощью команды:
pip install chardetОсновной инструмент для определения кодировки в библиотеке – это функция chardet.detect(). Она принимает на вход байтовую строку и возвращает словарь с результатами, включая предполагаемую кодировку и уверенность в правильности этой оценки. Например:
import chardet
with open('example.txt', 'rb') as f:
raw_data = f.read()
result = chardet.detect(raw_data)
print(result)
В результате будет выведен словарь, в котором ключи 'encoding' и 'confidence' содержат кодировку и степень уверенности в правильности её определения (от 0 до 1). Например:
{'encoding': 'utf-8', 'confidence': 0.99}
Если уверенность в определении кодировки низкая, рекомендуется дополнительно проверить файл с использованием других методов или библиотек, так как chardet не всегда может точно определить кодировку, особенно если текст содержит много нечитаемых символов.
Важно помнить, что при открытии файла для анализа, необходимо работать с ним в бинарном режиме (rb), так как любые преобразования в строки могут повлиять на точность распознавания.
Также стоит учитывать, что chardet не всегда даёт точный результат, особенно с файлами, содержащими много символов из разных языков или зашифрованные данные. В таких случаях можно комбинировать результаты с другими инструментами или использовать более специфичные подходы для работы с кодировками.