В Python проверка наличия символа или подстроки в строке – одна из самых часто используемых операций, которую можно выполнить несколькими способами. Несмотря на наличие множества методов, ключевым моментом является выбор подходящего инструмента в зависимости от контекста задачи. Например, если необходимо быстро определить присутствие символа, можно обойтись простым и понятным методом с использованием оператора in, который предлагает Python по умолчанию.
Другим распространённым подходом является использование метода find(), который возвращает индекс первого вхождения искомого символа в строку или -1, если символ не найден. Однако этот метод имеет смысл использовать, если помимо проверки вам необходимо узнать позицию символа. В случае же, когда важен только факт наличия символа, лучше отдать предпочтение оператору in, который быстрее и читаемее.
Важно учитывать, что Python предлагает и более продвинутые методы, такие как re.search() из модуля регулярных выражений, который идеально подходит для более сложных поисков, когда требуется не просто наличие символа, но и соблюдение определённого шаблона. В этом случае регулярные выражения позволяют создавать гибкие и мощные условия для поиска символов или подстрок, что особенно полезно в задачах с динамичными условиями поиска.
Использование оператора «in» для проверки наличия символа

Для использования оператора «in» достаточно записать выражение в формате: символ in строка. Это вернет True, если символ присутствует в строке, и False, если нет.
Пример:
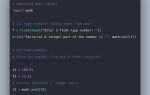
symbol = 'a'
string = 'banana'
result = symbol in string # TrueПреимущество такого подхода заключается в его лаконичности и понятности. Оператор «in» работает не только для проверки отдельных символов, но и для подстрок, что позволяет эффективно искать любые последовательности символов в строках.
При проверке символов или подстрок важно учитывать, что оператор «in» выполняет проверку с учетом регистра. Например, 'A' in 'apple' вернет False, поскольку строчная «a» и заглавная «A» считаются разными символами.
Этот метод особенно полезен при работе с текстовыми данными, где важно быстро проверить наличие определенного символа без необходимости использовать сложные циклы или регулярные выражения.
Метод.find() для поиска символа в строке

Метод find() в Python используется для поиска первого вхождения символа или подстроки в строке. Этот метод возвращает индекс первого символа найденного элемента, если он существует, и -1, если элемент не найден.
Основной синтаксис метода выглядит так:
str.find(substring, start=0, end=len(str))Здесь:
substring– искомая подстрока или символ, который необходимо найти.start– индекс, с которого начинается поиск (по умолчанию 0).end– индекс, до которого продолжается поиск (по умолчанию длина строки).
Метод find() полезен, если необходимо узнать позицию первого вхождения символа в строку. Например:
text = "Привет, мир!"
index = text.find("м")
print(index) # Выведет 8Если символ не найден, метод вернёт -1:
index = text.find("x")
print(index) # Выведет -1Важно помнить, что метод чувствителен к регистру символов. Например, поиск строки «п» в «Привет» вернёт -1, поскольку символы не совпадают по регистру:
text = "Привет"
index = text.find("п")
print(index) # Выведет -1Метод find() работает эффективно для поиска одиночных символов и подстрок. Однако если нужно найти все вхождения элемента в строке, стоит рассмотреть другие методы, такие как регулярные выражения или цикл. Также стоит отметить, что метод не выбрасывает исключений, что делает его безопасным для использования в коде, который не предполагает наличия искомого элемента в строке.
Метод.index() и его отличие от.find() при поиске символа
Метод .index() и метод .find() в Python выполняют одну задачу – поиск символа или подстроки в строке. Оба метода возвращают индекс первого вхождения искомого элемента. Однако между ними есть ключевые различия, которые влияют на поведение программы в случае ошибок.
Метод .index() генерирует исключение ValueError, если искомый символ или подстрока не найдены в строке. Это позволяет немедленно обработать ошибку и выполнить соответствующие действия в блоке обработки исключений. Например:
text = "Привет, мир!"
index = text.index("мир") # Вернет 8
index = text.index("здравствуй") # ValueError: substring not foundМетод .find(), в отличие от .index(), не вызывает исключение в случае отсутствия искомого символа. Вместо этого он возвращает -1, что делает его более безопасным для использования, когда необходимо просто проверить наличие символа без необходимости обработки ошибок:
text = "Привет, мир!"
find_result = text.find("мир") # Вернет 8
find_result = text.find("здравствуй") # Вернет -1Выбор между .index() и .find() зависит от контекста задачи. Если нужно точно узнать, что символ или подстрока присутствуют в строке, и обработать ошибку в случае их отсутствия, стоит использовать .index(). Если же нужно просто проверить наличие символа без выброса исключений, предпочтительнее .find().
Проверка наличия символа с помощью регулярных выражений

Для проверки наличия символа в строке можно использовать модуль re, который предоставляет мощные инструменты для работы с регулярными выражениями. В Python регулярные выражения позволяют найти символы, соответствующие заданному шаблону, с высокой гибкостью.
Чтобы проверить, содержится ли конкретный символ в строке, используйте функцию re.search(). Эта функция ищет первое вхождение паттерна в строку и возвращает объект, если совпадение найдено, или None, если символ не найден.
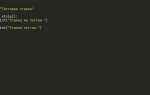
import re
pattern = r"а"
string = "Пример строки"
result = re.search(pattern, string)
if result:
print("Символ найден")
else:
print("Символ не найден")
В данном примере регулярное выражение r"а" ищет символ «а» в строке. Если он найден, функция re.search() возвращает объект совпадения, в противном случае – None.
Некоторые важные моменты:
- Регулярные выражения чувствительны к регистру. Если нужно игнорировать регистр, добавьте флаг
re.IGNORECASEв функциюre.search(). - Для проверки нескольких символов используйте классы символов. Например,
[abc]соответствует любому из символов ‘a’, ‘b’ или ‘c’. - Если необходимо найти все вхождения символа, используйте функцию
re.findall(), которая вернёт все совпадения в виде списка.
result = re.findall(r"[а-я]", "Пример строки")
print(result)
В этом примере функция re.findall() находит все символы кириллицы в строке и возвращает их в виде списка.
Регулярные выражения – это мощный инструмент для поиска и замены в строках. Они позволяют задавать более сложные критерии поиска, например, искать символы, следующие за определённым шаблоном или стоящие на определённых позициях в строке.
Как обработать случай, когда символ не найден в строке

Когда в Python необходимо проверить наличие символа в строке, часто возникает ситуация, когда символ не найден. В таком случае важно корректно обработать этот сценарий, чтобы избежать ошибок в программе. Рассмотрим несколько вариантов, как это можно сделать.
Если символ отсутствует в строке, метод find() возвращает -1. Это позволяет легко обработать случай, когда символ не найден:
string = "Привет, мир!"
if string.find('x') == -1:
print("Символ не найден.")
Используя этот подход, можно заранее принять решение о дальнейшем ходе программы в случае отсутствия символа.
Ещё один способ – это использование оператора in. Если символ не найден, выражение if 'x' not in string вернёт True, что также позволяет обработать ситуацию:
string = "Привет, мир!"
if 'x' not in string:
print("Символ не найден.")
Важно учитывать, что метод in является более читаемым и часто используется, когда нужно просто проверить наличие символа.
Также, при обработке ошибки можно воспользоваться исключениями. В случае, если выполнение программы зависит от наличия символа в строке, можно выбросить исключение:
string = "Привет, мир!"
if 'x' not in string:
raise ValueError("Символ не найден в строке.")
Этот подход особенно полезен в крупных проектах, где важно сразу фиксировать ошибку, а не продолжать выполнение программы.
Таким образом, подход к обработке отсутствующего символа зависит от контекста задачи. Используйте метод find() для получения индекса символа, оператор in для простых проверок, и исключения для более сложных случаев. Все эти методы позволяют эффективно работать с ситуацией, когда символ не найден в строке.
Проверка наличия символа в строках с учетом регистра

Пример использования оператора in для поиска символа с учетом регистра:
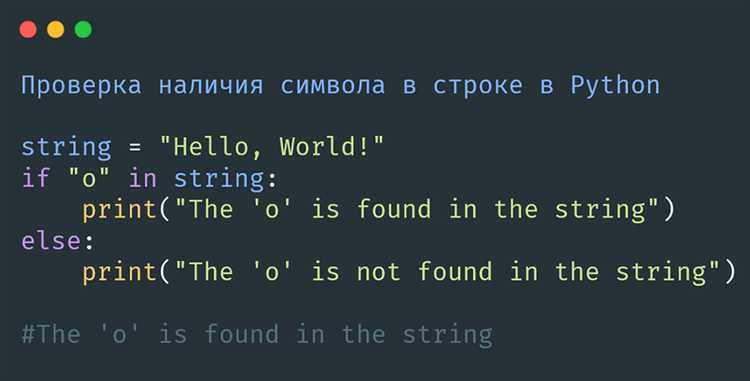
text = "Hello World"
result = 'H' in text # True
result = 'h' in text # FalseЗдесь первый запрос возвращает True, потому что заглавная буква «H» присутствует в строке. Во втором случае результат False, так как строчная буква «h» не найдена в строке.
Если необходимо выполнить проверку без учета регистра, можно использовать метод lower() или upper(), которые преобразуют строку в один регистр. Например:
text = "Hello World"
result = 'h'.lower() in text.lower() # TrueЭтот код преобразует и символ, и строку в строчные буквы перед сравнением, что позволяет игнорировать различия в регистре.
Для более сложных случаев, когда нужно учитывать другие условия или выполнять регулярные выражения, можно использовать модуль re. Однако в большинстве задач стандартных методов достаточно для проверки символов с учетом регистра.
Как использовать метод count() для подсчета вхождений символа в строку
Метод count() в Python позволяет быстро определить, сколько раз конкретный символ или подстрока встречаются в строке. Это один из самых эффективных способов подсчета вхождений без необходимости вручную перебирать элементы строки.
Метод count() принимает два аргумента:
- Первый аргумент – это символ или подстрока, количество вхождений которых нужно подсчитать.
- Второй и третий аргументы (необязательные) – это индекс начала и окончания поиска. Если их не указать, метод проверяет всю строку.
Пример базового использования метода:
text = "hello world"
count = text.count("o")
print(count)Этот код вернет число 2, так как символ «o» встречается дважды.
Также можно указать диапазон поиска, задав индекс начала и конца:
text = "hello world"
count = text.count("o", 0, 5)
print(count)В данном примере метод будет искать вхождения «o» только в подстроке с индексами от 0 до 4, что вернет результат 1.
Использование метода count() эффективно для подсчета символов в строках, особенно когда нужно точно ограничить область поиска или обработать строку целиком. Этот метод также полезен, когда необходимо узнать, сколько раз встречается определенный элемент, чтобы, например, выполнить дополнительные вычисления или проверки.
- Если требуется посчитать вхождения подстроки, а не одиночного символа, метод работает точно так же.
- Метод
count()не изменяет строку и не вызывает ошибок, если искомая подстрока отсутствует – результат будет равен нулю.