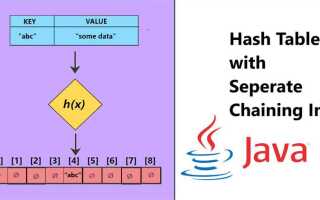
Hash таблица в Java – это структура данных, предназначенная для эффективного хранения и поиска элементов. Основная идея заключается в использовании хеш-функции для преобразования ключа в индекс массива, что позволяет значительно ускорить доступ к данным. В Java hash таблицы представлены классом HashMap, который является частью коллекций Java. Основная цель HashMap – обеспечить быстрый поиск, вставку и удаление элементов, используя ключи, которые ассоциируются с конкретными значениями.
При добавлении элемента в hash таблицу, ключ проходит через хеш-функцию, которая генерирует индекс, на основе которого элемент будет помещён в массив. Это позволяет получить доступ к элементу за постоянное время, O(1), при условии, что хеш-функция равномерно распределяет ключи по массиву. Однако на практике, из-за коллизий (когда два ключа имеют одинаковый хеш), эффективность может снижаться, и время поиска может увеличиться до O(n) в худшем случае.
Для борьбы с коллизиями в Java hash таблицы используют различные методы. Одним из них является метод цепочек, при котором элементы с одинаковыми хешами хранятся в виде связанного списка или другой структуры данных. Это позволяет избежать потери информации и сохранить стабильную производительность в большинстве случаев. Другим методом является открытая адресация, где в случае коллизии осуществляется поиск следующей свободной ячейки в массиве.
Кроме того, HashMap имеет важные особенности, такие как возможность хранения null в качестве значения, но не в качестве ключа. Важно помнить, что порядок элементов в hash таблице не гарантирован, так как порядок зависит от хеш-функции и распределения ключей.
Как устроена hash таблица в Java и что такое хеш-функция
Хеш-функция – это алгоритм, который принимает ключ в качестве входных данных и возвращает целое число, обычно называемое хешем. Хеш-функция должна иметь несколько важных свойств: она должна быть детерминированной (один и тот же ключ всегда должен давать одинаковый результат), быстрой и распределять ключи равномерно по всем индексам массива. В Java стандартная хеш-функция для объектов определяется методом hashCode(), который присутствует в каждом объекте класса Object.
После вычисления хеша значение делится на размер массива (обычно с использованием операции взятия по модулю) для получения индекса, по которому будет размещен элемент. Если два ключа приводят к одинаковому индексу, возникает коллизия, и для ее решения используется один из методов: цепочки (связанного списка) или открытая адресация.
В случае использования цепочек коллизии решаются путем создания списка всех элементов, чьи хеши совпадают, и размещения новых элементов в этом списке. В случае открытой адресации элементы с одинаковым хешем размещаются в другом месте массива по заранее определенному алгоритму (например, линейное или квадратичное пробирование).
Важно понимать, что эффективность работы hash таблицы напрямую зависит от качества хеш-функции. Плохо распределяющая хеш-функция может привести к значительным коллизиям, что ухудшает производительность операций. В Java, например, для класса HashMap стандартная хеш-функция может быть переопределена для улучшения распределения ключей.
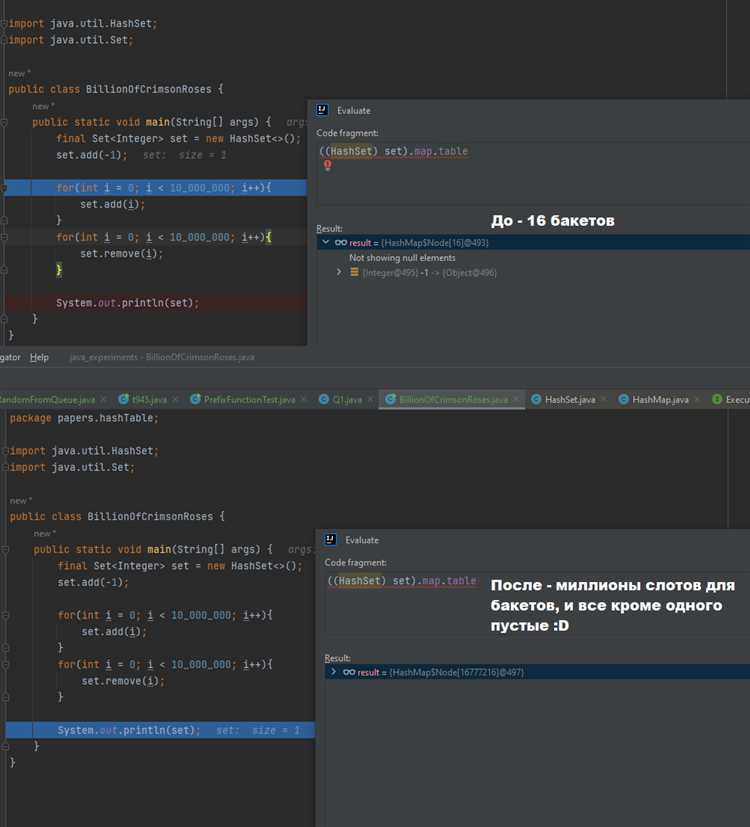
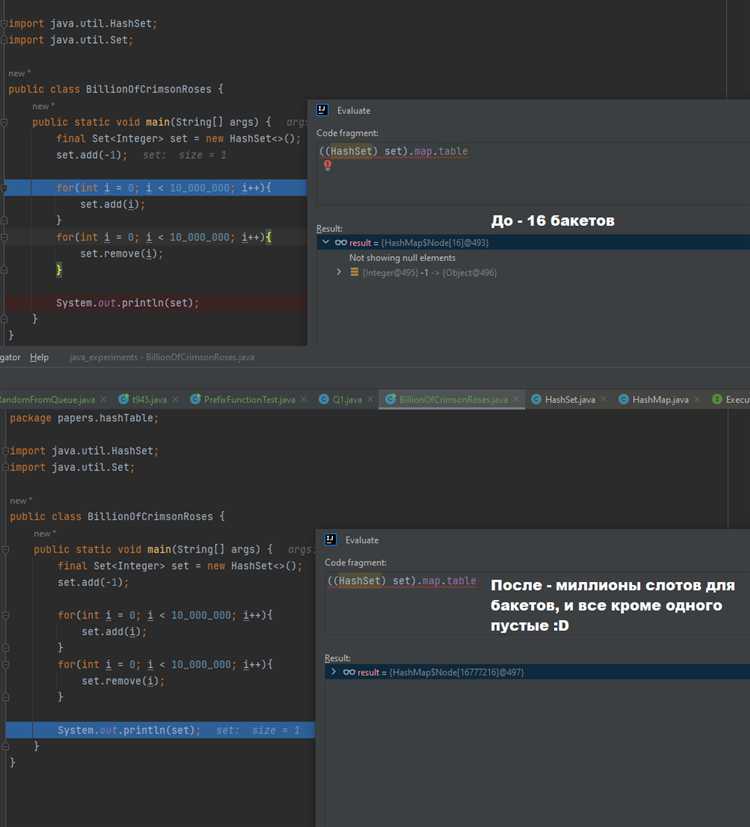
При использовании хеш-таблиц в Java важно контролировать нагрузку на таблицу – отношение количества элементов в таблице к количеству слотов. Когда нагрузка становится слишком высокой, происходит перераспределение элементов по новому массиву с увеличением его размера, что также требует пересчета хешей.
Как происходит добавление элементов в hash таблицу в Java
Первым шагом является вычисление хеш-кода ключа. В Java метод hashCode() объекта генерирует целое число, которое используется для дальнейших вычислений. Этот код затем преобразуется в индекс с использованием операции взятия остатка от деления на размер таблицы. Это позволяет распределить элементы по различным ячейкам таблицы.
Далее происходит проверка на коллизии. Коллизия возникает, когда два различных ключа приводят к одинаковому индексу. Для решения этой проблемы Java использует несколько подходов, включая цепочки (chaining) и открытое адресование. При использовании цепочек каждый индекс таблицы хранит ссылку на список элементов, что позволяет добавлять новые элементы в виде узлов в конец списка. В случае с открытым адресованием элементы размещаются в соседних ячейках, если текущая ячейка уже занята.
Если в таблице недостаточно места для нового элемента, происходит её автоматическое расширение. Обычно это происходит при превышении определённого коэффициента загрузки, который по умолчанию равен 0.75. В процессе расширения таблица перераспределяет существующие элементы по новым индексам, что требует перерасчёта хешей.
Важно помнить, что выбор хеш-функции имеет большое значение для производительности таблицы. Хорошая хеш-функция должна минимизировать вероятность коллизий и равномерно распределять элементы по таблице. Некачественная хеш-функция может привести к значительным затратам времени на поиск и добавление элементов.
Поиск элементов в hash таблице: как работает поиск по ключу
Поиск элемента в hash таблице происходит на основе хеш-функции, которая преобразует ключ в индекс в массиве (или бакете). Этот индекс затем используется для быстрого доступа к значению. Важнейшие шаги процесса поиска:
- 1. Хеширование ключа: При добавлении или поиске элемента в hash таблице хеш-функция принимает ключ и вычисляет индекс в массиве. Этот индекс определяет, где хранится соответствующее значение.
- 2. Обработка коллизий: Если два разных ключа имеют одинаковый хеш (коллизия), то для их хранения используется дополнительная структура данных, например, связанный список или дерево. В случае коллизий поиск может потребовать проверки нескольких элементов в одном бакете.
- 3. Поиск по индексу: После вычисления хеша и нахождения соответствующего индекса в массиве происходит проверка содержимого этого бакета. Если элемент с искомым ключом найден, возвращается его значение.
- 4. Окончательная проверка: Если несколько элементов хранятся в одном бакете из-за коллизий, каждый элемент проверяется на соответствие ключу. При этом поиск обычно происходит до тех пор, пока не будет найден элемент или не кончатся все элементы в бакете.
Алгоритм поиска имеет среднюю временную сложность O(1) при отсутствии коллизий. В случае большого количества коллизий сложность может увеличиться, но она всё равно остается относительно быстрой благодаря оптимизированным методам разрешения коллизий.
Рекомендации для оптимизации:
- Выбор хеш-функции: Хорошая хеш-функция минимизирует количество коллизий и равномерно распределяет элементы по бакетам, что улучшает производительность поиска.
- Управление размером таблицы: Если таблица становится слишком большой, время поиска увеличивается из-за роста коллизий. Рекомендуется увеличивать размер таблицы и перераспределять элементы (rehash) по мере необходимости.
Коллизии в hash таблице и способы их разрешения
Коллизия возникает в hash таблице, когда два разных элемента имеют одинаковый хеш-код. Это приводит к тому, что они могут быть помещены в одну и ту же ячейку таблицы, нарушая принцип уникальности ключей. Важно понимать, что коллизии неизбежны при ограниченном объеме памяти и достаточно большом количестве данных, поэтому важно использовать эффективные способы их разрешения.
1. Метод цепочек (Chaining)
Метод цепочек заключается в том, что для каждого индекса таблицы создается связанный список. Когда два элемента имеют одинаковый хеш-код, они просто добавляются в список, связанный с этим индексом. При таком подходе таблица не ограничена фиксированным количеством элементов, и количество коллизий можно контролировать с помощью управления длиной цепочек. Однако, при увеличении цепочек производительность может снизиться, если они становятся слишком длинными.
2. Открытая адресация (Open Addressing)
В отличие от метода цепочек, в открытой адресации все элементы хранятся непосредственно в самой таблице. При коллизии поиск следующего доступного места для вставки происходит с использованием одного из методов:
- Линейное пробирование – если ячейка занята, то пробуем следующую, и так до тех пор, пока не найдем пустую.
- Квадратичное пробирование – аналогично линейному, но шаг увеличивается по квадрату (например, 1, 4, 9 и т.д.), что снижает вероятность циклических зависимостей.
- Двойное хеширование – при коллизии применяется дополнительное хеширование, чтобы вычислить новый индекс. Это повышает распределение элементов и снижает вероятность большого скопления данных в одной области.
3. Использование динамического расширения
В случае частых коллизий, таблица может быть расширена. Это можно сделать автоматически при достижении определенной загрузки таблицы. Применение этого метода позволяет сохранить хорошую производительность даже при увеличении числа элементов, однако операция перераспределения данных может быть дорогостоящей, если она происходит слишком часто.
4. Резервные методы
Для повышения устойчивости и уменьшения вероятности коллизий также можно использовать дополнительные подходы, такие как перенос данных в новую таблицу или использование множества хеш-функций для различных ключей, что минимизирует вероятность того, что разные ключи будут иметь одинаковый хеш.
Выбор метода зависит от специфики задачи и требований к производительности. Важно анализировать нагрузку на таблицу и типы данных, чтобы выбрать наиболее оптимальный подход для разрешения коллизий.
Как удалить элемент из hash таблицы в Java

Для удаления элемента из hash таблицы в Java используется метод remove() класса HashMap. Этот метод удаляет пару «ключ-значение», если такой ключ существует в таблице.
Пример синтаксиса:
hashMap.remove(ключ);
Метод remove() принимает один параметр – ключ, соответствующий элементу, который требуется удалить. Если ключ найден, его пара «ключ-значение» удаляется, и метод возвращает значение, ассоциированное с этим ключом. Если ключ отсутствует, метод возвращает null и не изменяет таблицу.
Если необходимо выполнить дополнительные действия после удаления (например, обработать значение перед удалением), можно использовать результат вызова метода:
Integer value = hashMap.remove(ключ);
if (value != null) {
// Дополнительная обработка
}
Важное замечание: удаление элемента в HashMap происходит за амортизированное время O(1), что означает, что операция удаления выполняется очень быстро, даже при большом количестве элементов в таблице.
Также стоит учитывать, что метод remove() корректно работает в многопоточной среде только в случае использования ConcurrentHashMap, поскольку HashMap не синхронизирован. Если требуется безопасная работа с несколькими потоками, следует использовать более подходящие коллекции.
Особенности работы с hash таблицей в многозадачных приложениях
В многозадачных приложениях работа с hash таблицей в Java требует особого подхода, так как одновременные операции чтения и записи могут привести к проблемам с синхронизацией и целостностью данных. Рассмотрим ключевые моменты, которые стоит учитывать при работе с hash таблицей в многозадачной среде.
- Проблемы с конкурентным доступом: В стандартной
HashTableреализована внутренняя синхронизация, но она может стать узким местом, если большое количество потоков одновременно обращается к таблице. Это приводит к задержкам и снижению производительности. - Использование
ConcurrentHashMap: Для многозадачных приложений рекомендуется использоватьConcurrentHashMap, который предлагает более эффективную синхронизацию. В отличие отHashTable, он использует сегментированную синхронизацию, позволяя нескольким потокам одновременно работать с разными сегментами карты. - Изоляция потоков: Важно разделять ресурсы между потоками, чтобы минимизировать блокировки. В
ConcurrentHashMapкаждый сегмент таблицы защищен собственным механизмом синхронизации, что позволяет улучшить производительность при одновременных операциях. - Синхронизация при модификации данных: Если необходимо выполнять операции модификации данных в нескольких потоках, важно следить за тем, чтобы синхронизация происходила только там, где это действительно нужно. Например, использование методов
computeилиmergeпозволяет выполнить атомарные операции, снижая вероятность ошибок из-за гонки потоков. - Обработка коллизий: В многозадачных приложениях важно учитывать, что коллизии при вставке элементов могут быть более вероятны при высоком уровне конкуренции. Использование продвинутых методов обработки коллизий (например, использование ссылок на списки или деревья) позволяет эффективно справляться с этим.
- Отсутствие блокировок для операций чтения:
ConcurrentHashMapпозволяет выполнять операции чтения без блокировок, что делает его идеальным выбором для приложений с высоким объемом операций чтения и низким количеством записей.
Для достижения максимальной производительности в многозадачных приложениях следует избегать использования старой версии HashTable и предпочтительнее использовать ConcurrentHashMap, комбинируя его с механизмами оптимизации синхронизации и изоляции потоков. Важно тестировать приложение в условиях многозадачности, чтобы минимизировать возможные проблемы с блокировками и производительностью.
Когда стоит использовать hash таблицу, а когда другие структуры данных
Hash таблицы идеально подходят для случаев, когда требуется быстрый доступ к данным по ключу. Их использование оправдано в следующих ситуациях:
1. Когда важна скорость поиска. Если вам нужно выполнять операции поиска, вставки или удаления за константное время, hash таблица будет наилучшим выбором. В среднем операции выполняются за O(1), что делает её очень эффективной при большом объёме данных.
2. Когда ключи уникальны и хорошо распределены. Hash таблицы требуют уникальных и равномерно распределённых ключей для эффективной работы. При этом важно, чтобы коллизии (случай, когда два разных ключа хешируются в одну позицию) не мешали производительности, и для их обработки был выбран оптимальный метод (например, цепочечное хеширование).
3. Когда необходима динамическая вставка и удаление данных. Hash таблицы адаптируются к изменениям объёма данных и позволяют эффективно вставлять и удалять элементы. В отличие от некоторых других структур данных, таких как массивы или списки, изменение размера таблицы происходит динамически, минимизируя затраты времени на операции.
Однако в некоторых случаях использование других структур данных может быть более предпочтительным:
1. Когда порядок элементов имеет значение. Если вам важно сохранять порядок элементов, hash таблица не подойдёт. Для таких случаев лучше использовать структуры данных, которые сохраняют порядок, например, TreeMap или LinkedHashMap.
2. Когда требуется сортировка элементов. Hash таблица не предоставляет механизмов для сортировки. Для сортировки данных можно использовать TreeMap (когда нужно отсортировать элементы по ключу) или PriorityQueue (для сортировки по значениям с приоритетом).
3. Когда важна память. Hash таблицы могут потреблять больше памяти из-за необходимости хранения дополнительных данных, таких как список для разрешения коллизий. Если задача требует минимизации использования памяти, и операции поиска не так критичны по скорости, лучше выбрать другие структуры данных, например, массивы или списки.
4. Когда нужен доступ к элементам по индексу. Если ваш код требует доступа к элементам по индексу, hash таблица не будет лучшим вариантом. В таких случаях лучше использовать массивы или ArrayList, которые обеспечивают быстрый доступ по индексу с временной сложностью O(1).
Таким образом, выбор между hash таблицей и другими структурами данных зависит от специфики задачи. Hash таблица является отличным выбором для быстрого поиска и динамических операций, но не всегда оптимальна, когда важен порядок, сортировка или минимизация использования памяти.
Вопрос-ответ:
Что такое hash таблица в Java?
Hash таблица в Java — это структура данных, которая позволяет хранить элементы в виде пар «ключ-значение». Она использует хеш-функцию для преобразования ключа в индекс, по которому можно быстро найти соответствующее значение. Java предоставляет класс `HashMap`, который реализует эту структуру. Основной задачей хеш-таблицы является обеспечение быстрого поиска, добавления и удаления элементов.
Как работает hash таблица в Java?
Когда вы добавляете элемент в hash таблицу, хеш-функция генерирует индекс для ключа. Этот индекс используется для поиска соответствующего места в массиве, где хранится значение. Если несколько ключей генерируют одинаковый индекс (коллизия), то используется специальная техника для их обработки, например, цепочки или открытая адресация. Важно, что операция поиска в hash таблице выполняется за время O(1) в среднем, что делает её быстрой при работе с большими объемами данных.
Что такое коллизия в hash таблице и как её можно обработать?
Коллизия в hash таблице происходит, когда два разных ключа хешируются в один и тот же индекс. Это может вызвать проблему, так как оба значения будут записаны в одну ячейку. Для решения этой проблемы существуют разные методы. Один из них — использование цепочек, когда каждый элемент, попавший в одну ячейку, сохраняется в списке или другой структуре данных. Другой способ — открытая адресация, когда элементы с коллизией размещаются в других ячейках, вычисленных с использованием определенной схемы.
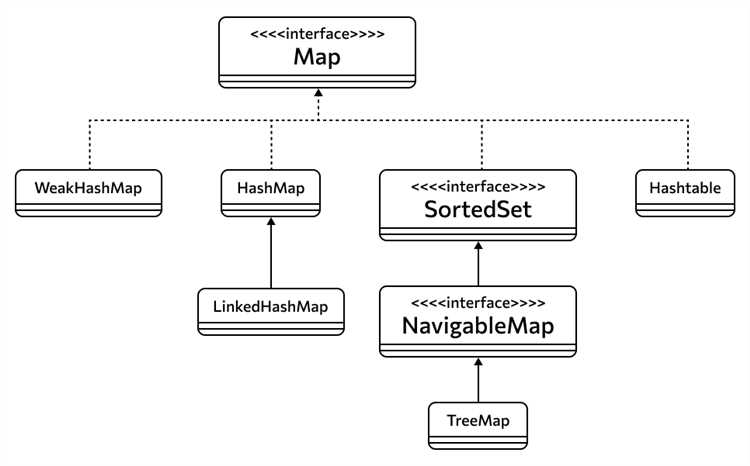
В чем отличие между HashMap и Hashtable в Java?
Основное отличие между `HashMap` и `Hashtable` заключается в том, что `HashMap` не синхронизирован, а `Hashtable` синхронизирован, что означает, что он безопасен для многопоточного использования. Однако из-за синхронизации `Hashtable` может работать медленнее. В современном программировании предпочтительнее использовать `HashMap`, а для многопоточных приложений — `ConcurrentHashMap` или другие более специализированные решения.
Почему в Java используется хеширование в hash таблицах?
Хеширование позволяет быстро вычислять индекс для ключа, что делает операции вставки, поиска и удаления очень быстрыми — в среднем за время O(1). Это особенно важно при работе с большими объемами данных, где производительность критична. Хеш-функция распределяет ключи равномерно по массиву, минимизируя количество коллизий и улучшая работу таблицы. Таким образом, хеширование обеспечивает высокую скорость работы структуры данных.