Hibernate – это популярная фреймворк для объектно-реляционного отображения (ORM) в языке программирования Java. Его основная цель – упростить взаимодействие между приложениями на Java и реляционными базами данных, минимизируя необходимость написания SQL-запросов. Hibernate позволяет работать с базами данных через объектно-ориентированные модели, что значительно сокращает количество ошибок, связанных с использованием низкоуровневых запросов, и ускоряет разработку.
При использовании Hibernate объекты Java автоматически маппируются на строки в базе данных. Это обеспечивает удобную работу с данными как с объектами, без необходимости вручную конструировать SQL-запросы для каждой операции. Фреймворк позволяет разработчику сосредоточиться на бизнес-логике, а не на взаимодействии с базой данных, что сокращает время разработки и повышает читаемость кода.
Одним из ключевых преимуществ Hibernate является поддержка транзакций и кэширования. Hibernate предоставляет встроенные механизмы для работы с транзакциями, что позволяет избежать проблем с целостностью данных. Кэширование, в свою очередь, позволяет снизить нагрузку на базу данных, ускоряя выполнение запросов, особенно при работе с большими объемами данных.
Для начала работы с Hibernate необходимо подключить зависимость в проект и настроить конфигурацию соединения с базой данных. При этом используется конфигурационный файл, где описываются параметры подключения и другие настройки. В процессе разработки важно правильно настроить связи между сущностями и грамотно настроить Hibernate для эффективного выполнения запросов и управления данными.
Как настроить Hibernate в проекте на Java
Для настройки Hibernate в проекте на Java необходимо выполнить несколько ключевых шагов. Начнём с добавления зависимостей и настройки конфигурации.
1. Добавление зависимостей Hibernate
Если проект использует Maven, добавьте следующие зависимости в файл pom.xml:
org.hibernate hibernate-core 5.6.10.Final org.hibernate hibernate-entitymanager 5.6.10.Final javax.persistence javax.persistence-api 2.2
Если проект использует Gradle, добавьте следующие строки в файл build.gradle:
implementation 'org.hibernate:hibernate-core:5.6.10.Final' implementation 'org.hibernate:hibernate-entitymanager:5.6.10.Final' implementation 'javax.persistence:javax.persistence-api:2.2'
2. Конфигурация Hibernate
Для работы Hibernate требуется файл конфигурации, который обычно называется hibernate.cfg.xml. Этот файл должен находиться в папке src/main/resources и содержать параметры подключения к базе данных и настройки Hibernate.
org.hibernate.dialect.PostgreSQLDialect update true true org.postgresql.Driver jdbc:postgresql://localhost:5432/mydb myuser mypassword
Основные параметры, которые необходимо указать:
- hibernate.dialect – диалект базы данных, например, для PostgreSQL используйте org.hibernate.dialect.PostgreSQLDialect.
- hibernate.hbm2ddl.auto – настройка автоматического создания или обновления схемы базы данных. Значение update используется для обновления существующей схемы.
- hibernate.connection.driver_class – класс драйвера базы данных.
- hibernate.connection.url – URL подключения к базе данных.
- hibernate.connection.username и hibernate.connection.password – параметры для аутентификации.
3. Создание класса Entity
Каждая сущность в Hibernate должна быть помечена аннотацией @Entity. Пример создания класса сущности:
import javax.persistence.Entity;
import javax.persistence.Id;
@Entity
public class Person {
@Id
private Long id;
private String name;
private int age;
// геттеры и сеттеры
}
Класс Person теперь является сущностью, которая будет отображаться в базе данных. Поле с аннотацией @Id будет использоваться как первичный ключ.
4. Открытие сессии Hibernate
Для взаимодействия с базой данных через Hibernate создайте объект SessionFactory, который управляет сессиями. Используйте SessionFactory для получения Session, с помощью которой выполняются операции с базой данных.
import org.hibernate.Session;
import org.hibernate.SessionFactory;
import org.hibernate.cfg.Configuration;
public class HibernateUtil {
private static SessionFactory factory;
static {
factory = new Configuration().configure("hibernate.cfg.xml").addAnnotatedClass(Person.class).buildSessionFactory();
}
public static Session getSession() {
return factory.getCurrentSession();
}
}
В приведённом примере мы создаём SessionFactory на основе конфигурации и класса сущности Person. Метод getSession() возвращает текущую сессию для работы с базой данных.
5. Выполнение операций с базой данных
Теперь можно использовать Hibernate для выполнения операций. Пример добавления нового объекта в базу данных:
import org.hibernate.Session;
public class Main {
public static void main(String[] args) {
Session session = HibernateUtil.getSession();
try {
session.beginTransaction();
Person person = new Person();
person.setName("John Doe");
person.setAge(30);
session.save(person);
session.getTransaction().commit();
} finally {
session.close();
}
}
}
Этот код создаёт новый объект Person, сохраняет его в базу данных и подтверждает транзакцию.
6. Завершающие шаги
После завершения настройки Hibernate, важно не забывать о правильной обработке транзакций и закрытии сессий, чтобы избежать утечек памяти. Кроме того, необходимо обеспечить корректную настройку базы данных и классов сущностей для эффективного взаимодействия с Hibernate.
Создание Entity-классов для работы с Hibernate
Для работы с Hibernate необходимо создать классы, которые будут соответствовать таблицам базы данных. Эти классы называются Entity. Каждый Entity-класс должен быть аннотирован и реализовывать определённые правила для корректной работы с Hibernate.
Основные шаги для создания Entity-классов:
- Аннотация @Entity: Класс должен быть аннотирован с помощью
@Entity, чтобы Hibernate мог его распознать как сущность. Это обязательное условие для всех классов, которые должны быть сохранены в базе данных. - Аннотация @Table: Для явного указания имени таблицы в базе данных используется аннотация
@Table. Если таблица называется так же, как и класс, аннотация не обязательна, но её использование помогает избежать ошибок, если имя таблицы отличается от имени класса. - Уникальный идентификатор @Id: Каждый Entity-класс должен иметь поле, которое будет выступать в роли первичного ключа. Это поле помечается аннотацией
@Id. Для его генерации часто используется аннотация@GeneratedValue, которая указывает способ генерации значения идентификатора (например, AUTO, IDENTITY, SEQUENCE). - Типы данных: Для полей Entity-классов необходимо использовать типы данных, которые Hibernate может корректно преобразовать в соответствующие типы SQL. Например, для строк используется
String, для чисел –Integer,Long, для дат –java.util.Date. - Геттеры и сеттеры: Для каждого поля необходимо определить геттеры и сеттеры. Это необходимо для корректной работы Hibernate, так как он использует рефлексию для работы с полями класса.
Пример простого Entity-класса:
@Entity
@Table(name = "person")
public class Person {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "first_name")
private String firstName;
@Column(name = "last_name")
private String lastName;
@Column(name = "birth_date")
private Date birthDate;
// Геттеры и сеттеры
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getFirstName() {
return firstName;
}
public void setFirstName(String firstName) {
this.firstName = firstName;
}
public String getLastName() {
return lastName;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
public Date getBirthDate() {
return birthDate;
}
public void setBirthDate(Date birthDate) {
this.birthDate = birthDate;
}
}
Рекомендуется следить за следующими аспектами:
- Поля, которые не должны сохраняться в базе данных, можно пометить аннотацией
@Transient. - Аннотация
@Columnпозволяет задать дополнительные параметры для столбца, такие как имя столбца, уникальность или возможность быть NULL. - Для работы с отношениями между сущностями (например, «один ко многим» или «многие ко многим») используются аннотации
@OneToMany,@ManyToOne,@ManyToMany,@JoinColumnи другие.
Правильное создание Entity-классов помогает Hibernate эффективно работать с базой данных, обеспечивая простоту и гибкость при выполнении операций с данными.
Основные операции с базой данных через Hibernate: save, update, delete

В Hibernate операции с базой данных выполняются с использованием методов, которые обеспечивают манипуляцию с объектами Java, отображёнными на таблицы базы данных. Рассмотрим три основные операции: save, update и delete.
Save – это операция, которая сохраняет объект в базе данных. При её выполнении Hibernate проверяет, существует ли уже запись с таким идентификатором в базе. Если нет, создается новая запись. Метод session.save(Object entity) добавляет объект в таблицу, соответствующую его классу. Важно помнить, что save возвращает идентификатор созданной записи, который можно использовать для дальнейших операций с объектом.
Пример использования:
Session session = sessionFactory.openSession();
Transaction transaction = session.beginTransaction();
MyEntity entity = new MyEntity();
entity.setName("Example");
session.save(entity);
transaction.commit();
session.close();
При этом объект, переданный в save, должен быть в состоянии «Transient», то есть он не должен быть связан с сессией или иметь свой идентификатор в базе данных.
Update позволяет обновить существующую запись в базе данных. Метод session.update(Object entity) обновляет запись в таблице, если объект уже существует в базе данных. Hibernate проверяет, был ли изменён объект в текущей сессии, и если изменения присутствуют, то обновляет соответствующую строку в таблице. Для этого объект должен быть в состоянии «Persistent», то есть он должен быть связан с текущей сессией и иметь действительный идентификатор.
Пример использования:
Session session = sessionFactory.openSession();
Transaction transaction = session.beginTransaction();
MyEntity entity = session.get(MyEntity.class, 1L);
entity.setName("Updated Name");
session.update(entity);
transaction.commit();
session.close();
Важно помнить, что если объект не найден в базе данных, то операция обновления не будет выполнена, и необходимо обработать возможное исключение.
Delete используется для удаления объекта из базы данных. Метод session.delete(Object entity) удаляет строку, которая соответствует объекту, связанному с текущей сессией. Перед удалением объект должен быть в состоянии «Persistent», и его идентификатор должен соответствовать существующей записи в базе.
Пример использования:
Session session = sessionFactory.openSession(); Transaction transaction = session.beginTransaction(); MyEntity entity = session.get(MyEntity.class, 1L); session.delete(entity); transaction.commit(); session.close();
При удалении объекта важно учитывать, что Hibernate не просто удаляет строку в базе, но и проверяет возможные связи с другими таблицами через механизмы каскадных операций (например, с помощью аннотации @Cascade), которые могут приводить к удалению связанных объектов.
Основные операции – save, update и delete – обеспечивают базовые возможности взаимодействия с базой данных, но для более сложных сценариев могут использоваться дополнительные механизмы, такие как каскадирование и настройка сессий.
Работа с HQL (Hibernate Query Language) для выполнения запросов

Основные особенности HQL:
- Работа с сущностями вместо таблиц.
- Использование именованных параметров для предотвращения SQL-инъекций.
- Поддержка агрегации, сортировки, фильтрации и объединений между сущностями.
Для выполнения HQL-запросов в Hibernate необходимо использовать сессию. Пример выполнения запроса:
Session session = sessionFactory.openSession();
Transaction transaction = session.beginTransaction();
String hql = "FROM User WHERE age > :age";
Query query = session.createQuery(hql);
query.setParameter("age", 18);
List users = query.list();
transaction.commit();
session.close();
В данном примере мы выбираем всех пользователей, чей возраст больше 18 лет. Использование параметризированных запросов с :age помогает избежать SQL-инъекций и повышает безопасность кода.
Пример использования агрегатных функций:
String hql = "SELECT AVG(salary) FROM Employee"; Query query = session.createQuery(hql); Double averageSalary = (Double) query.uniqueResult();
HQL поддерживает все основные агрегатные функции, такие как COUNT, SUM, AVG, MIN и MAX, которые можно использовать для обработки данных в базе.
Для сложных запросов можно использовать объединения (JOIN). Пример запроса с использованием JOIN:
String hql = "SELECT p.name, o.date FROM Product p INNER JOIN p.orders o WHERE o.status = :status";
Query query = session.createQuery(hql);
query.setParameter("status", "SHIPPED");
List results = query.list();
В этом примере происходит объединение таблиц «Product» и «Order» через сущности, связанные через свойство «orders» в классе «Product». Результат запроса – это список объектов, содержащих имя продукта и дату заказа.
HQL поддерживает также сортировку данных:
String hql = "FROM Product ORDER BY price DESC"; Query query = session.createQuery(hql); Listproducts = query.list();
Запрос извлекает все продукты и сортирует их по цене в убывающем порядке.
Для более сложных запросов HQL предоставляет возможность работать с подзапросами:
String hql = "FROM Employee e WHERE e.salary > (SELECT AVG(salary) FROM Employee)"; Query query = session.createQuery(hql); Listemployees = query.list();
Это позволяет извлекать данные, удовлетворяющие определенным условиям, основанным на результатах других запросов.
Использование HQL требует знания структуры сущностей и их связей. Преимущество HQL перед стандартным SQL заключается в том, что он работает с объектами Java, а не с таблицами, что облегчает взаимодействие с объектно-ориентированными моделями данных. Однако важно помнить, что для эффективного выполнения сложных запросов необходимо учитывать производительность и структуру базы данных.
Использование аннотаций для настройки маппинга объектов в Hibernate

Hibernate использует аннотации для настройки маппинга между объектами Java и таблицами базы данных. Это позволяет значительно упростить процесс настройки и управления сохранением данных. В отличие от XML-конфигурации, аннотации интегрируются прямо в код, что делает проект более читаемым и поддерживаемым.
@Entity является основной аннотацией, обозначающей класс как сущность, которая будет храниться в базе данных. Каждый класс, помеченный этой аннотацией, должен быть связан с таблицей базы данных. Для указания имени таблицы используется аннотация @Table. Например:
@Entity
@Table(name = "users")
public class User {
// поля и методы
}
Аннотация @Id используется для указания поля, которое является первичным ключом в таблице. Обычно это уникальный идентификатор, который помогает Hibernate отслеживать объект в базе данных. Если первичный ключ состоит из нескольких полей, можно использовать аннотацию @EmbeddedId или @IdClass для их настройки.
@Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id;
Для указания связи между сущностями Hibernate предоставляет несколько типов аннотаций. Например, для связи «один ко многим» используется @OneToMany, а для «многие ко многим» – @ManyToMany. Эти аннотации определяют, как таблицы будут связаны, и управляют отношениями между объектами.
@OneToMany(mappedBy = "user") private Listorders;
Для связи «многие к одному» используется @ManyToOne, а для «один к одному» – @OneToOne. Важно помнить, что при использовании этих аннотаций необходимо настроить параметры каскадирования (например, @Cascade) и стратегию загрузки (например, LAZY или EAGER).
@Column позволяет более точно настраивать свойства столбца таблицы, такие как имя, длина и уникальность. Например, если необходимо задать максимальную длину строки в столбце, можно использовать аннотацию @Column(length = 50).
@Column(name = "email", length = 100, unique = true) private String email;
Если нужно настроить поведение при сохранении или удалении данных, могут быть использованы аннотации @PrePersist и @PreRemove. Эти аннотации помогают выполнить дополнительные действия перед сохранением или удалением сущности.
Кроме того, аннотация @Transient позволяет исключить поле из маппинга, что полезно для временных или вычисляемых данных, которые не должны сохраняться в базе.
@Transient private int tempValue;
Использование аннотаций в Hibernate позволяет гибко настраивать поведение маппинга и обеспечивать высокую производительность при работе с базой данных, минимизируя необходимость в конфигурации XML и упрощая поддержание проекта.
Как настроить кэширование в Hibernate для ускорения работы с данными
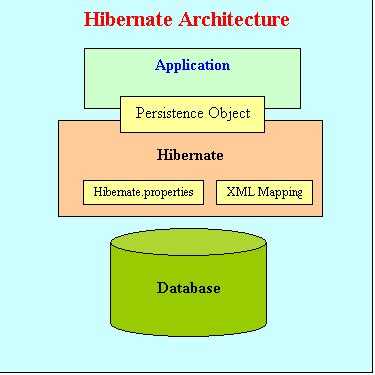
Для ускорения работы с базой данных и уменьшения нагрузки на нее, Hibernate предоставляет механизм кэширования, который позволяет хранить часто запрашиваемые данные в памяти. Это значительно ускоряет выполнение повторных запросов и снижает время отклика приложения. В Hibernate реализованы два типа кэширования: кэш первого уровня и кэш второго уровня.
Кэш первого уровня работает по умолчанию и связан с сессией. Он хранит объекты только в пределах одной сессии, что означает, что каждый объект будет повторно загружаться из базы данных, если сессия закрыта. Чтобы использовать кэш первого уровня, не требуется дополнительной конфигурации, поскольку он включен по умолчанию. Важно понимать, что при закрытии сессии объекты из кэша первого уровня теряются.
Кэш второго уровня работает на уровне сессии фабрики (SessionFactory) и может хранить объекты между сессиями. Для его использования необходимо настроить соответствующие параметры в конфигурации Hibernate. Он может быть реализован с использованием различных провайдеров кэша, таких как EHCache, Infinispan, или другие. Чтобы включить кэш второго уровня, нужно в конфигурации Hibernate указать провайдер кэша и активировать его.
Для настройки кэша второго уровня в Hibernate необходимо выполнить следующие шаги:
hibernate.cache.use_second_level_cache=true hibernate.cache.provider_class=org.hibernate.cache.ehcache.EhCacheProvider hibernate.cache.region.factory_class=org.hibernate.cache.ehcache.EhCacheRegionFactory hibernate.cache.use_query_cache=true
Данный фрагмент конфигурации включает кэш второго уровня и задает использование EHCache в качестве провайдера. Для работы с кэшированием запросов нужно также активировать кэш запросов (hibernate.cache.use_query_cache=true). Это позволяет кэшировать результаты выполненных HQL и Criteria-запросов, что дополнительно ускоряет работу приложения при повторных запросах.
Кроме того, необходимо настроить аннотации кэширования на уровне сущностей и запросов. Например, чтобы указать, что сущность должна использовать кэш, добавьте аннотацию @Cache:
@Entity
@Cache(usage = CacheConcurrencyStrategy.READ_WRITE)
public class User {
// поля и методы
}
Аннотация @Cache позволяет указать стратегию конкурентности для кэширования, такие как READ_ONLY, READ_WRITE, NONSTRICT_READ_WRITE и TRANSACTIONAL. Выбор стратегии зависит от требований к целостности данных и частоты изменений. Например, для сущностей, которые часто изменяются, лучше использовать READ_WRITE, а для редко изменяющихся данных – READ_ONLY.
Чтобы кэшировать результаты запросов, можно использовать аннотацию @Cacheable в запросах HQL или Criteria API:
@Query("from User where id = :id")
@Cacheable(true)
public User getUserById(@Param("id") Long id);
В случае использования кэширования запросов важно правильно управлять жизненным циклом данных в кэше. Для этого можно настроить TTL (Time-to-Live) и максимальный размер кэша в конфигурации провайдера, например, для EHCache:
Это позволяет управлять временем жизни кэшированных объектов и предотвратить переполнение кэша. Параметры настройки зависят от выбранного провайдера кэша, поэтому рекомендуется ознакомиться с документацией конкретного решения.
Включение кэширования в Hibernate значительно повышает производительность при работе с базой данных, особенно в случае большого числа повторных запросов. Однако важно помнить, что кэширование может привести к несоответствию данных, если изменения в базе данных происходят без учета кэшированных объектов. Поэтому необходимо следить за актуальностью кэшируемых данных и при необходимости очищать кэш или обновлять его содержимое.
Вопрос-ответ:
Что такое Hibernate?
Hibernate — это фреймворк для работы с базами данных в языке программирования Java. Он представляет собой библиотеку, которая позволяет разработчикам взаимодействовать с реляционными базами данных через объектно-ориентированное программирование. Hibernate упрощает процесс преобразования данных между объектами Java и таблицами базы данных, используя так называемое ORM (Object-Relational Mapping). Это позволяет избежать необходимости писать сложные SQL-запросы для операций с базой данных.
Как работает Hibernate в Java?
Hibernate автоматически преобразует Java-объекты в строки SQL и наоборот, благодаря чему разработчики могут работать с данными как с обычными объектами, а не с набором строк и чисел. Фреймворк использует концепцию маппинга, чтобы связывать классы Java с таблицами в базе данных, а поля классов — с колонками этих таблиц. Hibernate выполняет множество операций для упрощения работы с данными, включая управление транзакциями, кэширование и поддержку различных стратегий загрузки данных (например, ленивой или жадной загрузки).
Что такое ORM и почему Hibernate его использует?
ORM (Object-Relational Mapping) — это технология, которая позволяет разработчику работать с объектами в коде, не заботясь о деталях реализации базы данных. Hibernate использует ORM для того, чтобы автоматически преобразовывать объекты Java в данные, которые могут быть сохранены в реляционной базе данных, и наоборот. Это помогает упростить разработку, сократив необходимость писать много SQL-запросов вручную и ускоряя взаимодействие с базой данных.
Какие преимущества дает использование Hibernate в Java?
Использование Hibernate в Java имеет несколько ключевых преимуществ. Во-первых, оно значительно упрощает работу с базой данных, позволяя разработчику сосредоточиться на объектно-ориентированном подходе, а не на SQL-запросах. Во-вторых, Hibernate поддерживает автоматическое управление транзакциями, кэширование, что повышает производительность приложения. Кроме того, фреймворк упрощает поддержку различных баз данных, так как обеспечивает абстракцию от их особенностей. Это особенно полезно в больших проектах, где требуется поддержка разных СУБД.