Один из распространенных запросов при работе с текстовыми данными в Python – это разделение строки на отдельные символы. Задача может возникнуть при анализе текста, обработке пользовательского ввода или в процессе парсинга данных. Рассмотрим несколько способов решения этой задачи с использованием стандартных инструментов Python, без необходимости в сторонних библиотеках.
Первый и самый очевидный способ – использование функции list(), которая преобразует строку в список символов. Это удобный и быстрый метод, если вам нужно работать с каждым символом по отдельности. Например:
text = "Пример"
result = list(text)
print(result) # ['П', 'р', 'и', 'м', 'е', 'р']Этот метод не требует дополнительных усилий и идеально подходит для большинства случаев. Однако есть и другие способы, такие как использование генераторов или метода join() для объединения символов в строку, что может быть полезно в более сложных сценариях.
Стоит также отметить, что методы, использующие list() или другие стандартные функции, сохраняют порядок символов в исходной строке, что полезно при анализе текста, где важна последовательность символов.
Использование метода list() для преобразования строки в список символов

Метод list() в Python позволяет быстро преобразовать строку в список отдельных символов. Это один из самых простых и эффективных способов работы с каждой буквой или символом строки в отдельности.
Для того чтобы преобразовать строку в список, достаточно передать её в функцию list(), например:
строка = "Пример"
список = list(строка)
print(список)
В результате выполнения кода строка «Пример» будет преобразована в список: ['П', 'р', 'и', 'м', 'е', 'р'].
Преимущества использования метода list()
- Простота: Это стандартный метод Python, который легко использовать для преобразования строк.
- Производительность: Преобразование строки в список с помощью
list()работает быстро, даже для длинных строк. - Гибкость: Каждый символ строки становится элементом списка, что упрощает дальнейшую обработку.
Пример применения

Предположим, у вас есть строка, и вы хотите выполнить проверку на наличие гласных в каждом символе строки. С помощью метода list() можно легко разделить строку на отдельные символы:
строка = "Программирование"
список_символов = list(строка)
гласные = ['А', 'Е', 'Ё', 'И', 'О', 'У', 'Э', 'Ю', 'Я']
для символ в список_символов:
если символ.upper() в гласные:
print(символ)
В данном примере создается список, состоящий из символов строки, и затем происходит проверка каждого символа на принадлежность к гласным буквам.
Рекомендации
- Если вам нужно часто работать с отдельными символами строки, лучше использовать
list()для преобразования её в список, а не обращаться к строкам через индексы. - Метод
list()также полезен, если вам нужно изменять символы строки, так как строки в Python неизменяемы, а списки – изменяемы. - Для строк, содержащих пробелы или другие специальные символы, метод
list()будет работать так же, как и для любых других символов, без изменений в логике.
Применение генераторов списка для создания списка символов

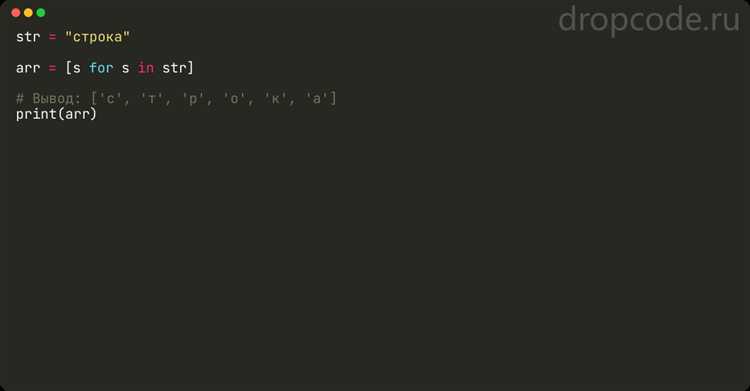
Пример использования генератора для получения списка символов:
string = "Python"
char_list = [char for char in string]
print(char_list)В данном примере создается список, где каждый элемент – это символ строки. Весь процесс выполняется за одну строку кода, что делает его более читаемым по сравнению с обычным циклом.
Если необходимо применить дополнительную фильтрацию, например, для выделения только гласных символов, это также можно сделать с помощью генераторов:
vowels = "aeiou"
filtered_chars = [char for char in string if char.lower() in vowels]
print(filtered_chars)Такой подход позволяет не только получить символы, но и работать с условиями, что делает генераторы списков мощным инструментом для обработки строк.
Генераторы списков также эффективны с точки зрения производительности. При большом объеме данных они оказываются быстрее по сравнению с использованием обычных циклов, поскольку они работают с итераторами и не требуют дополнительного выделения памяти для промежуточных объектов.
Использование цикла for для извлечения символов по одному

Цикл for в Python предоставляет удобный способ перебора элементов последовательности, включая строки. Каждый символ строки можно извлечь по очереди, что делает этот метод полезным при необходимости обработки или анализа каждого символа отдельно.
Для итерации по строке достаточно использовать следующий синтаксис:
for char in строка:
print(char)Пример: Для строки "Пример" цикл for выведет:
П
р
и
м
е
рЕсли необходимо выполнить операцию с каждым символом, можно легко комбинировать цикл с условными операторами или преобразованиями. Например, если нужно выбрать только заглавные буквы, используйте условие:
for char in строка:
if char.isupper():
print(char)Примечание: Итерация с for удобна для простых операций, но в случае необходимости обращения к символам по индексам лучше использовать другие способы (например, enumerate() или доступ через индексы).
Цикл for эффективно работает и в случаях с длинными строками, так как позволяет не загружать всю строку в память целиком, а обрабатывать её по одному символу, что бывает важно при работе с большими объемами данных.
Как работать с методом строк split() для разбиения на символы
Метод split() обычно используется для разбиения строки на подстроки по разделителям. Однако для разбиения строки на отдельные символы можно использовать его с определёнными настройками.
Для того чтобы метод split() разделил строку на символы, нужно передать в качестве разделителя пустую строку: split(''). Это приведёт к разбиению исходной строки на отдельные символы.
строка = "Пример"сплит_строки = строка.split('')print(сплит_строки)выведет:['П', 'р', 'и', 'м', 'е', 'р']
Важно помнить, что метод split() по умолчанию удаляет пустые строки из результата. Это означает, что если строка пуста, результат тоже будет пустым списком.
Кроме того, если в качестве разделителя передать любой символ или строку, то разбиение будет происходить по указанному элементу, а не по каждому символу.
строка = "123,456,789"сплит_строки = строка.split(',')print(сплит_строки)выведет:['123', '456', '789']
Таким образом, метод split() может быть полезен для разбиения строки на отдельные элементы по определённому разделителю, но для разбиения на символы рекомендуется использовать пустую строку в качестве разделителя. Важно учитывать, что метод возвращает список, в котором каждый элемент является строкой, даже если это отдельный символ.
Использование метода join() для преобразования списка символов обратно в строку
Метод join() в Python позволяет эффективно преобразовать список символов в строку. Этот метод применяется к строке-разделителю, который будет вставлен между элементами списка. Пример использования метода:
symbols = ['H', 'e', 'l', 'l', 'o']
result = ''.join(symbols)
В этом примере пустая строка '' используется как разделитель, что приводит к созданию строки без промежутков между символами. Метод join() является более производительным, чем использование циклов для конкатенации строк, так как он избегает создания временных объектов на каждом шаге.
Можно использовать и другие разделители. Например, если нужно добавить пробел между символами:
result = ' '.join(symbols)
Этот метод универсален и работает не только с символами, но и с любыми итерируемыми объектами, такими как списки строк или кортежи. Важно помнить, что метод join() может быть применен только к последовательностям строк, и попытка применить его к объектам других типов вызовет ошибку.
Метод join() является оптимальным инструментом для работы с большими объемами данных, так как он выполняет преобразование за один шаг, что минимизирует накладные расходы на память и скорость.
Преобразование строки в набор уникальных символов
Для извлечения уникальных символов из строки в Python можно использовать встроенные структуры данных, такие как множество (set). Множество автоматически удаляет повторяющиеся элементы, позволяя получить только уникальные символы.
Для преобразования строки в набор уникальных символов достаточно применить функцию set() к строке:
unique_chars = set("example")
В результате unique_chars станет множеством, содержащим уникальные символы из строки. Порядок символов при этом не сохраняется, так как множества не упорядочены.
Если требуется сохранить порядок символов, то можно воспользоваться коллекцией OrderedDict из модуля collections. Это позволит сохранить последовательность появления уникальных символов в строке:
from collections import OrderedDict
unique_chars = ''.join(OrderedDict.fromkeys("example"))
В данном случае OrderedDict.fromkeys() удаляет дубликаты, сохраняя порядок символов.
Чтобы избежать пробелов или других нежелательных символов, можно предварительно отфильтровать строку с использованием выражений или методов, таких как filter():
filtered_string = ''.join(filter(str.isalpha, "ex ample"))
unique_chars = set(filtered_string)
Этот подход исключает пробелы и символы, не являющиеся буквами.
Таким образом, для получения набора уникальных символов можно использовать как простые, так и более сложные методы, в зависимости от требований к сохранению порядка и фильтрации данных.
Вопрос-ответ: